

1. VerbaAlpina kurze Projektvorstellung
1.1. Hintergrund
- Alpenraum: mehrsprachig (5 Standardsprachen mit ihren jeweiligen Dialekte) aber ähnliche Lebenswelt (ähnliche Traditionen, Arbeitsbereiche, Gewohnheiten usw.)
1.2. Ziele
- Zusammenhänge zwischen den verschiedenen Sprachräumen anhand sprachlichen Materials zu schaffen
- „Den Alpenraum in seiner historischen linguistischen Zusammengehörigkeit darzustellen“
2. Konzeption bzw. Ablauf des Projektes
2.1. Allgemeines
- VerbaAlpina funktioniert online und verfügt über
- eine Web-Nutzeroberfläche (https://www.verba-alpina.gwi.uni-muenchen.de); Frontend durch WordPress
- eine Datenbank (https://pma.gwi.uni-muenchen.de/); Backend
- Jede Funktion und jedem Tool auf der Oberfläche entspricht ein Eintrag in die Datenbank
- Die im Rahmen von VerbaAlpina verarbeiteten Daten stammen aus zwei verschiedenen Quellen:
- aus Wörterbüchern bzw. Sprachatlanten (v.a. analog aber auch digital)
- aus dem Crowdsourcing
- Wichtiges Merkmal der VA-Daten: Georeferenzierung
2.2. Datenquellen: Sprachatlanten und Wörterbücher
Die Sprachatlanten (weiß) und Wörterbücher (schwarz), die für VerbaAlpina relevant sind, werden auf der folgenden Karte dargestellt:
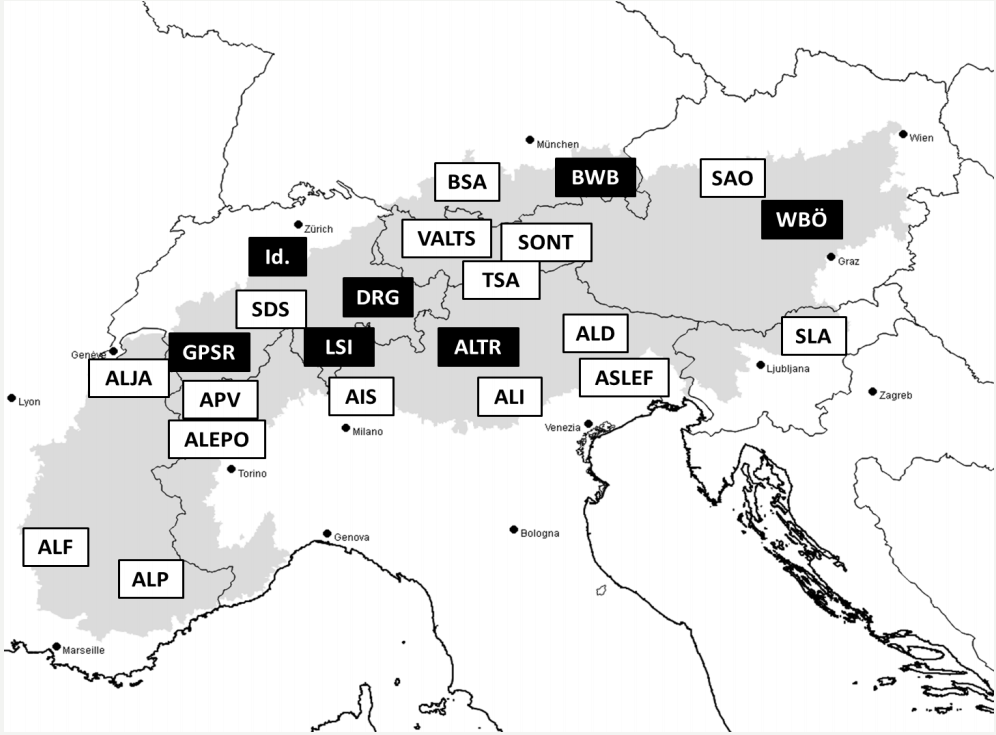
Sprachatlanten (weiß) und Wörterbücher (schwarz) im Bearbeitungsgebiet (entspricht den Grenzen der Alpenkonvention) von VerbaAlpina
2.3. Partnerschaften
- VerbaAlpina schließt mit Partner im In- sowie Ausland Kooperationen.
- Die Liste der Kooperationspartner kann unter folgendem Link abgerufen werden: https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=185&db=xxx
- Zweck der Kooperationen: Datenaustausch, Kontakte, Wissenschaftlicher Beirat
3. Arbeitsschritte
Sprachdaten werden im Rahmen von VerbaAlpina auf drei Ebenen verarbeitet, die im Folgenden beschrieben werden.
3.1. Transkription
Mit Transkription ist die Tätigkeit gemeint, die das 'abschreiben' von Sprachbelegen aus Sprachatlanten und Wörterbüchern umfasst. Dadurch werden Daten, die ursprünglich auf Papier vorliegen, digitalisiert und somit in den Datenbestand von VA aufgenommen.
Die Transkription erfolgt über Oberfläche von VerbaAlpina:
Einloggen --> Backend --> VerbaAlpina --> Transkriptionstool
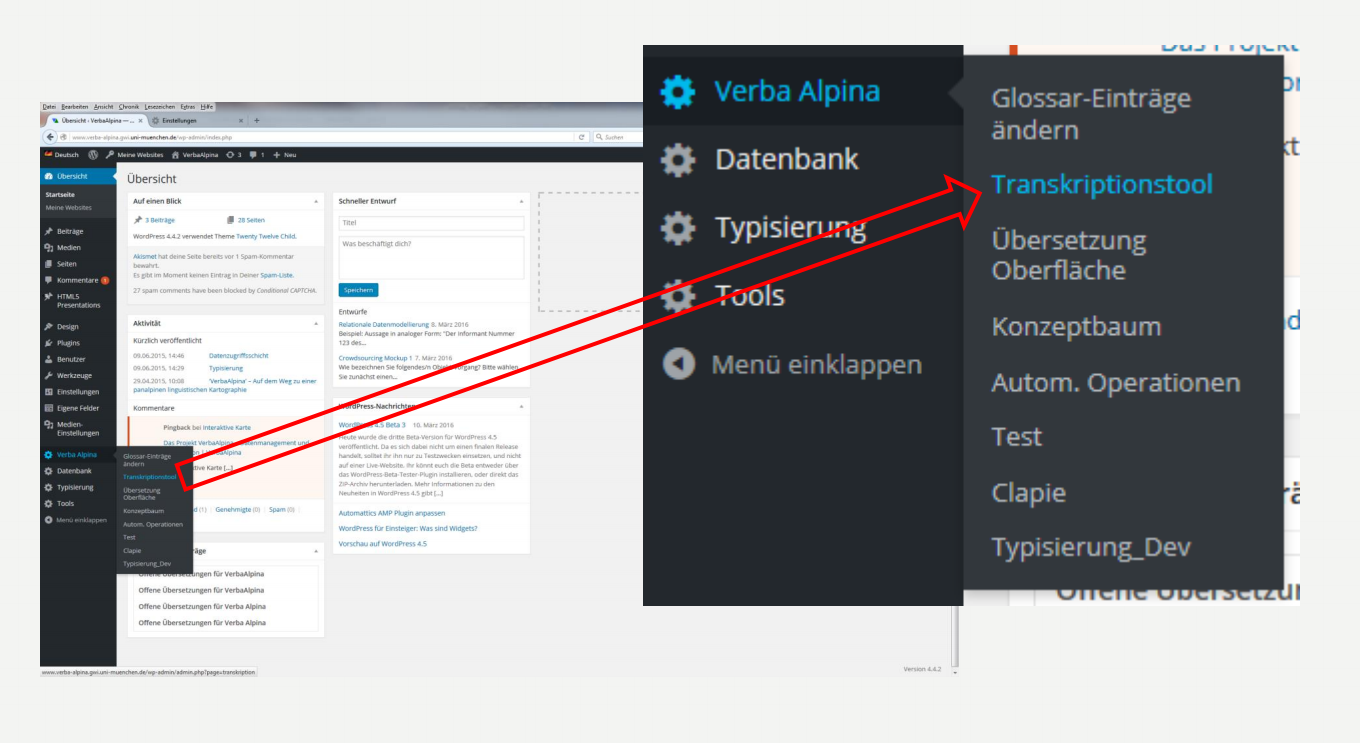
Screenshot
So schaut das Transkritpions-Tool aus:
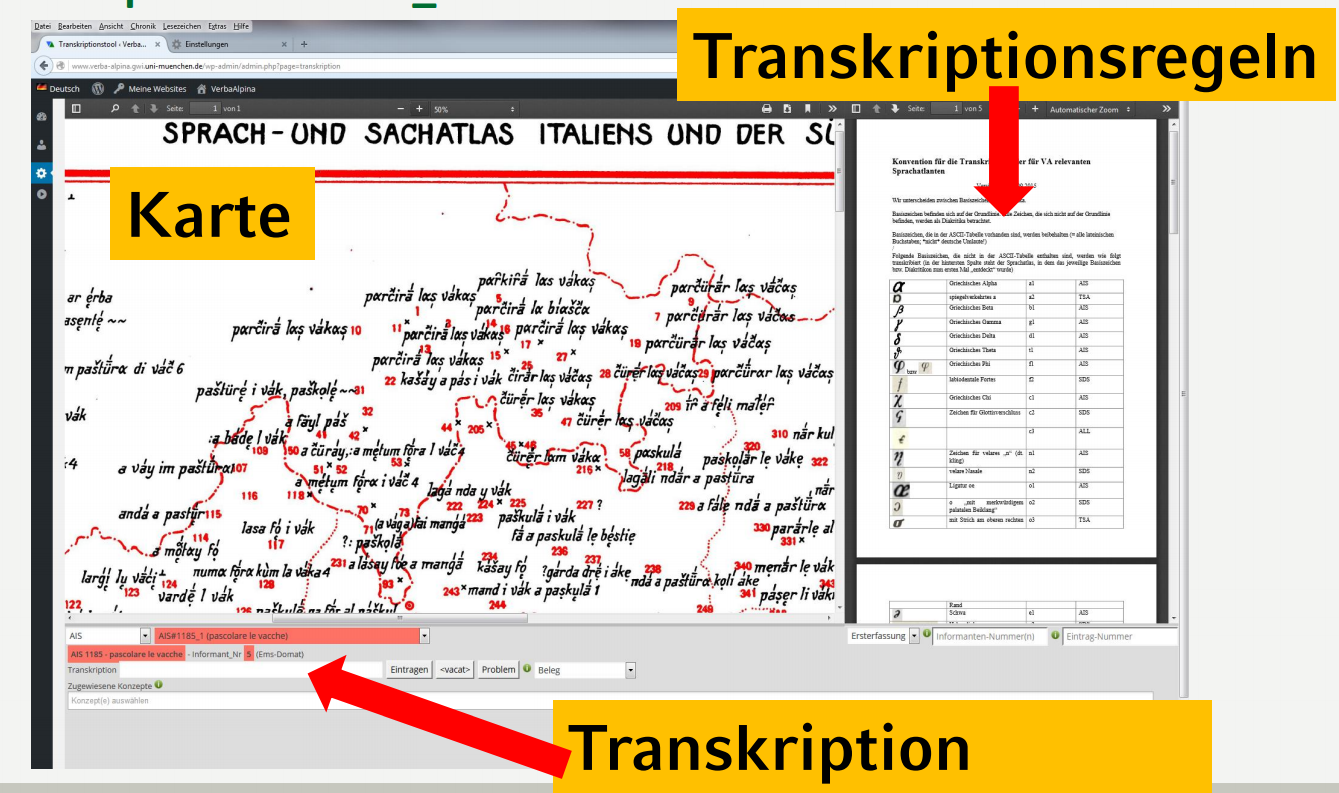
Wichtig:
- Sind die Kartentitel rot markiert, dann bedeutet dies, dass....Sind sie grün markiert, dann
- Mit Informant_Nr ist direkt vom jeweiligen Atlas übernommen
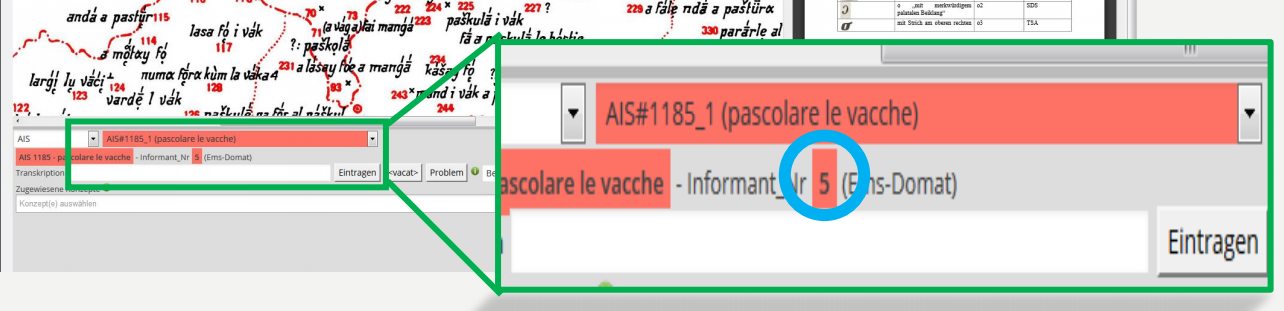
- Betacode: um den Informationsverlust zu vermeiden, hat VerbaAlpina eine Codierung kreiert, damit die Daten, so transkribiert werden können, wie sie in der Originalquelle stehen (Stichwort: quellentreu)
- Jedem Beleg, der transkribiert wird, muss ein Konzept zugeordnet werden (s. Anlegen eines Konzepts)
- Tippt man in das Feld etwas ein, erscheint rechts eine Vorschau;
- liegt ein Fehler in der Kodierung der Transkription vor (d.h. erkennt das System die eingetippten Zeichen nicht, so erscheint die Warnung "nicht gültig". Der Beleg muss dementsprechend neu transkribiert werden.
- Wenn in der Vorschau nur ein Teil der Transkription rot markiert wird, bedeutet dies, dass die Transkription stimmen kann (bzw. dass die Zeichenkette vom System erkannt wird, dass es aber nicht graphisch darstellen kann). Der Beleg kann so erfasst werden;
- Transkribieren = Übung
Weiterführende Methodologie-Beiträge von VerbaAlpina über die Transkription:
3.2. Tokenisierung
Die Tokenisierung erfolgt zum Teil automatisch. Durch die Tokenisierung werden die sprachlichen Äeusserungen in einzelnen Teilen aufgesplittert.
Damit dieser Prozess erfolgreich abgeschlossen werden kann, ist es wichtig, dass die Transkription richtig ist. Es ist im Nachhinein mühsam, die Daten nachträglich zu korrigieren. Deshalb sollten die transkribierten Belege mit der Originalfassung in den Atlanten bzw. Wörterbüchern immer stimmen.
Die Tokenisierung betrifft Hilfskräfte weniger: Normalerweise wird diese von den wissenschaftlichen Mitarbeitern durchgeführt.
3.3. Typisierung
Zu typisieren bedeutet sprachliche Ausdrücke unter Typen zusammenzufassen. Jeder 'Typ' ist als eine Klasse von sprachlichen Ausdrücken zu verstehen.
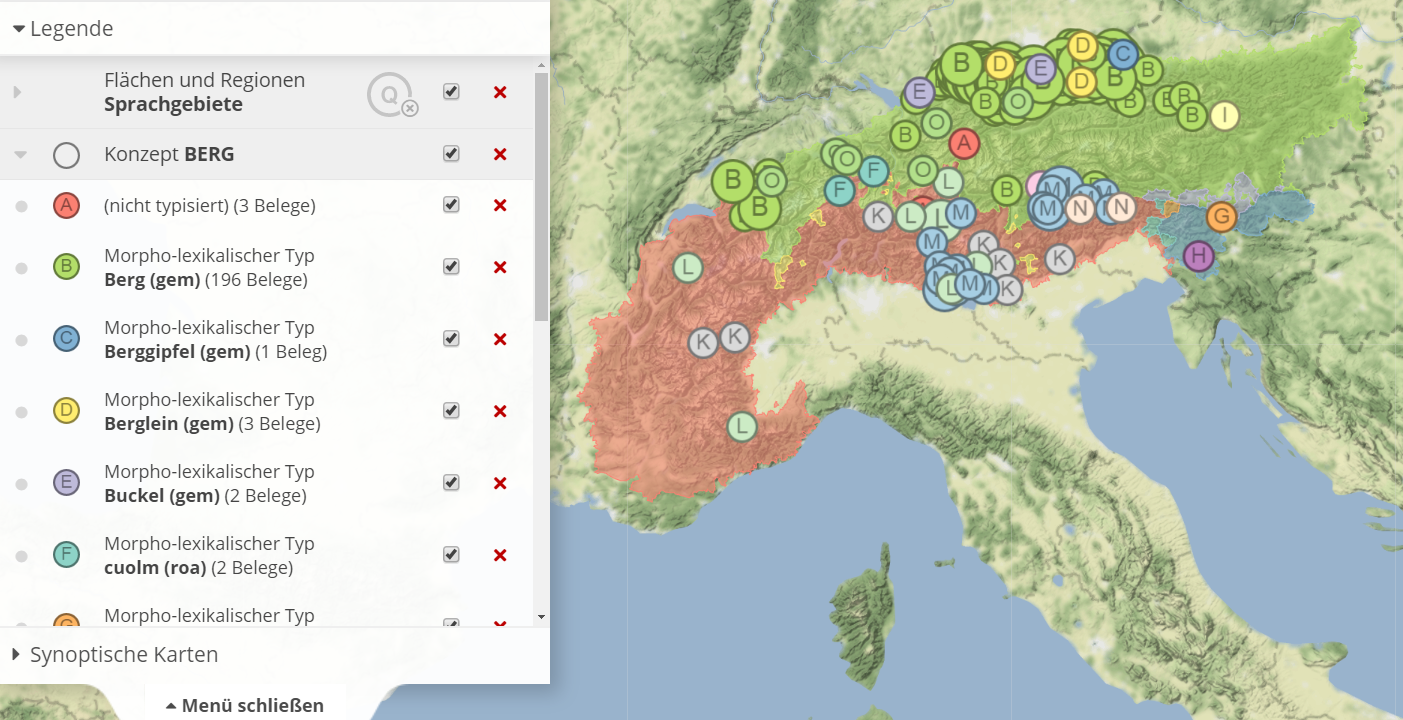
Beispiel der Typen des Konzepts "BERG" nach der Typisierung
Die Typisierung ist für VerbaAlpina zentral: Wenn das Ziel von VA die Darstellung von Zusammengehörigkeit ist, dann stellt die Typisierung eine zentrale Aufgabe dar. Aus diesem Grunde ist die Typisierung nur dann durchzuführen, wenn man sich sicher fühlt.
3.3.1. Methodologie-Beitrag: Typisierung
Bitte folgende Zeilen sorgfältig durchlesen:
Um sprachliche Belege in Gruppen zusammenzufassen, werden diese morpho-lexikalischen Typen zugeordnet. Oft sind die entsprechenden Typen aber noch nicht vorhanden. Im Folgenden soll also das Anlegen morpho-lexikalischer Typen am Beispiel eines Kompositums aus den deutschsprachigen Crowd-Daten erläutert werden.
Zum hier im Beispiel gezeigten Beleg Dachboden aus den Crowd-Daten existiert noch kein passender morpho-lexikalischer Typ.
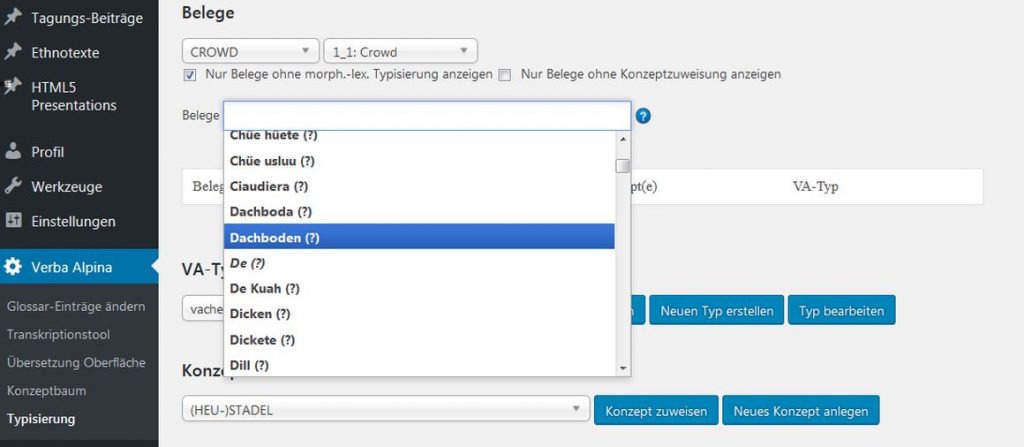
Im Falle von Dachboden handelt es sich um ein Kompositum aus den Nomen Dach und Boden. Da auch die Zuordnung einzelner Wortbestandteile von Interesse sein kann reicht es daher nicht, einfach einen morpho-lexikalischen Typ Dachboden (m.) (gem.) anzulegen. Denn wenn man wissen möchte, was alles als Boden bezeichnet wird, wie es beim Heuboden der Fall ist oder die Konzepte herausfiltern will, die durch Dach näher bestimmt werden wie Dachfirst oder Dachstuhl.
Grundsätzlich ist bei den Belegen zu berücksichtigen, ob eine Genus-Angabe vorhanden ist und es eine lemmatische Entsprechung in den Referenzwörterbüchern findet. Falls keine Genus-Angabe vorhanden, dann muss der morpho-lexikalischer Typ, der keine Genus-Angabe beinhaltet, für die Zuweisung gewählt.
Im Falle von Dach und Boden findet sich ein Eintrag im Duden, der auch inhaltlich dem Wortbestandteil in Dachboden entspricht, eben dem Boden, der sich unter dem Dach befindet.
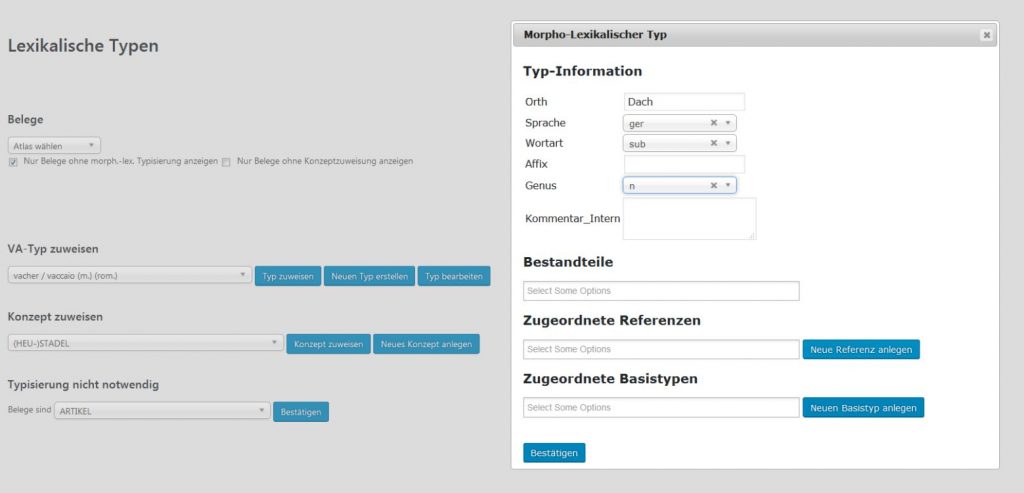
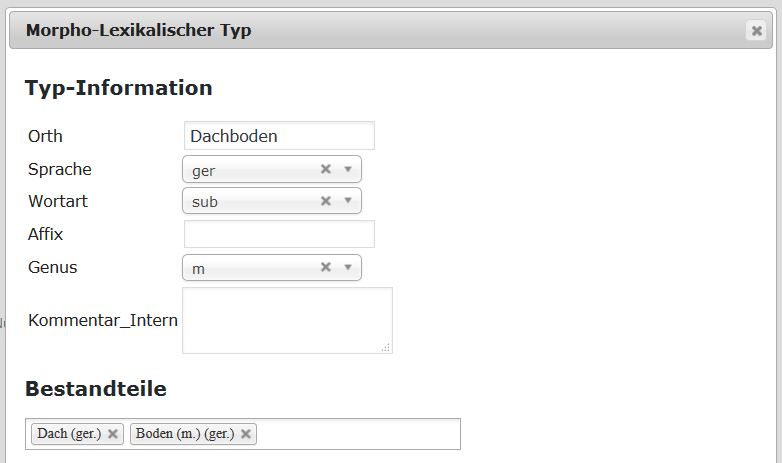
Zur Anlage eines neuen morpho-lexikalischen Typs wählt man "Neuen Typ erstellen" und gelangt so zur Eingabemaske, die man entsprechend ausfüllt. Im Feld "Affix" lässt Platz für die Angabe eines Suffix wie -lein beim Diminutiva. Beim Genus kann hier nur eine Wahl getroffen werden, denn im Falle einer Genusvariation zu einem Lexem muss jeweils ein einzelner morpho-lexikalischer Typ angelegt werden. Dann wird noch die entsprechende Referenzangabe benötigt. Durch Eintippen des Wortes unter "Zugeordnete Referenzen" kann geprüft werden, ob für das Deutsche bereits ein Eintrag existiert. Ist das nicht der Fall, so kann man dies mit der Wahl des Buttons "Neue Referenz anlegen" dies ändern. Falls ein Wort mit unterschiedlichen Genera geführt wird, kann dies hier vermerkt werden, außerdem die Quellenangabe als Link sowie optional ein interner Kommentar.
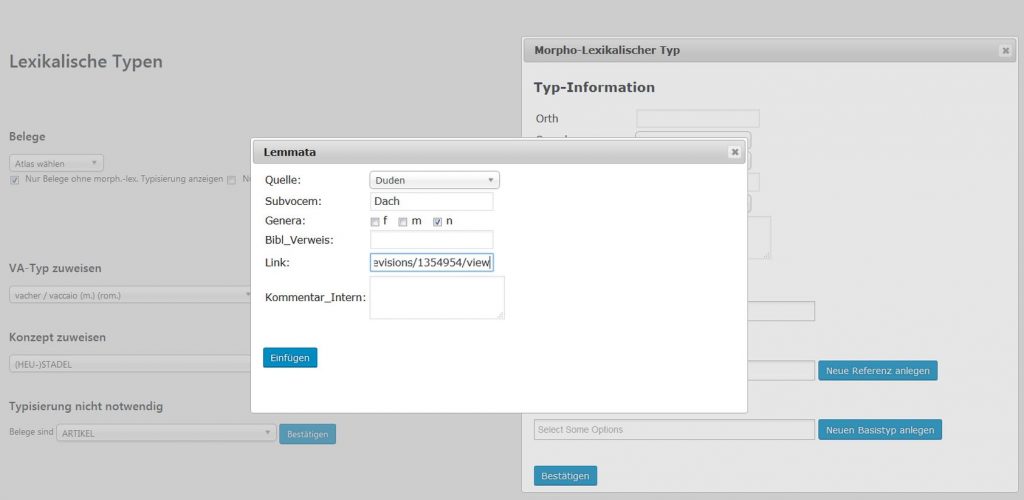
Mit "Einfügen" wird die Referenz in die Datenbank geschrieben. Dem morpho-lexikalischen Typ muss sie aber noch zugwiesen werden. Dies geschieht, wie oben beschrieben, über das Eintippen ins Textfeld und der Wahl der jeweiligen Referenz.
Wie anfangs erwähnt liefern uns die Belege oft keine Genusangaben, weshalb auch ein morpho-lexikalischer Typ ohne Genus angelegt werden muss. Dabei unterscheidet sich dieser nur hinsichtlich der Genusinformation, die hier einfach ausgelassen wird. Selbst in dem Fall, dass die Referenzwörterbücher oder sonstige Literatur nur eine Genusangabe liefern, dann ist trotzdem ein morpho-lexikalischer Typ ohne Genusangabe notwendig.
Die selbe Prozedur ist bei Boden ebenfalls anzuwenden, also zwei morpholexikalische Typen als Maskulinum und ohne Genusangabe mit der Referenz auf den Wörterbucheintrag.
Nachdem diese Schritte erfolgt sind, können nun auch die morpho-lexikalischen Typen zum Kompositum angelegt werden, hier ebenfalls einer mit und einer ohne Genusangabe. Falls vorhanden soll auch hier die Referenz auf einen Wörterbucheintrag erfolgen. Was das Kompositum vom Ein-Wort-Lexem jedoch unterscheidet, ist der Eintrag im Feld "Bestandteile". Hier sollen die morpho-lexikalischen Typen als Wortbestandteile angegeben werden, wobei das Bestimmungswort stets ohne Genus, das Grundwort mit Genusangabe gewählt wird, wenn denn das Kompositum auch ein Genustyp angegeben wurde.
3.3.1. Referenzwörterbücher
Die für VA relevanten Referenzwörterbücher sind folgende:
Für die romanischen Idiome:
Wörter aus dem romanischen Sprachraum werden, sofern möglich, verknüpft mit den Lemmata von:
Für die romanischen Idiome (s. Methodologie-Beitrag Referenzwörterbücher):
- Vocabolario Treccani
- Tesoro della lingua italiana delle origini
- Nuovo De Mauro
- Trésor de la langue française informatisé (TLFi)
- Glossaire des patois valdôtains http://patoisvda.org/gna/index.cfm/moteur-de-recherche.html
- Banca lessicala ladina (BLad; Ladinisch [lld])
- Pledari grond (Rätoromanisch [roh]) und DRG
- LSI und RID
Für die germanischen Idiome:
- Schweizerisches Idiotikon. Schweizerdeutsches Wörterbuch
- Grimm, Jacob und Wilhelm (1854-1961): Deutsches Wörterbuch von Jacob und Wilhelm Grimm, 16 Bde. in 32 Teilbänden, Leipzig (Quellenverzeichnis Leipzig 1971) (DWB)
- Duden (Berücksichtigung aufgrund seiner faktischen Bedeutung und der großen Materialfülle – trotz der Dürftigkeit hinsichtlich der von ihm präsentierten lexikographischen Informationen)
Für die Bestimmung der Etymologie speziell von Basistypen dienen als Referenz:
- Wartburg, Walther von (1922-1967): Französisches Etymologisches Wörterbuch. Eine Darstellung des galloromanischen Sprachschatzes, 25 Bände, Basel (FEW), mit seinen artikelschließenden Kommentare, die oft auch über das Französische und sogar das Romanische hinaus grundlegend sind.
- Kluge
- DELI
- Bezlaj und auch die neuste Ausgabe Snoj. Allgemein für slawische Etymologien s. Berneker
-
Als Referenzform für germanische Basistypen dienen wenn möglich die Lemmata des AWB, denn sie repräsentieren die ältesten belegten Formen.
3.4 Korrektur von Belegen
Wird während der Typisierung deutlich, dass ein Beleg fehlerhaft transkribiert wurde, so lässt sich dies wie folgt korrigieren.
Beim entsprechenden Beleg gelangt man per Klick auf den Button "Korrigiere Beleg" zur ID des Belegs (id_aeusserung).
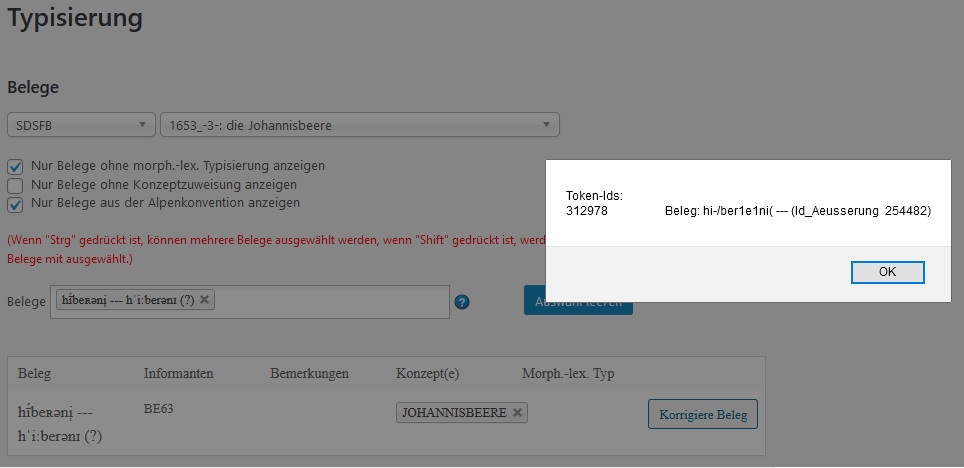
Da die Belege, die bereits über das Typisierungstool abrufbar sind, schon tokenisiert wurden, müssen die Änderungen in zwei Tabellen (aeusserungen, tokens) durchgeführt werden.
SELECT * FROM aeusserungen WHERE id_aeusserung = 254482

In der Spalte Aeusserung kann nun der Beleg korrigiert werden.
Da die Äußerung schon tokenisiert wurden, liegen die einzelnen Bestandteile bereits in der Tabelle tokens.
SELECT * FROM aeusserungen WHERE id_aeusserung = 254482

Ebenso wie in der Tabelle aeusserungen kann man nun in der Spalte Token die selben Änderungen am Token vornehmen. Zusätzlich ist hier aber noch notwendig, dass der String in den Spalten IPA und Original noch dementsprechend angepasst werden. Hierzu finden sich unter den Tools die Programme "Beta -> IPA" und "Beta -> Original", mithilfe derer man sich den String aus der Beta-Transkription generieren lassen kann.
3. Anlegen eines Konzeptes
Unsere Konzepttabelle `konzepte` hat in VerbaAlpina zwei Aufgaben. Zum einen ist sie für die Zusammenführung von verschiedenen Belegen mit gleicher Bedeutung nützlich, zum anderen dienen der Name bzw. die Beschreibung der Konzepte als Grundlage für das Crowdsourcing. Unter diesen beiden Gesichtspunkten ist auch das Anlegen eines neuen Konzepts zu sehen.
Eine vollkommen strikte Roadmap-to-Konzept kann es bei der Fülle verschiedener Themenbereiche nicht geben. Deshalb werden im Folgenden nur ein paar Hinweise gegeben, die bei der Erstellung von Konzepten beachtet werden sollen.
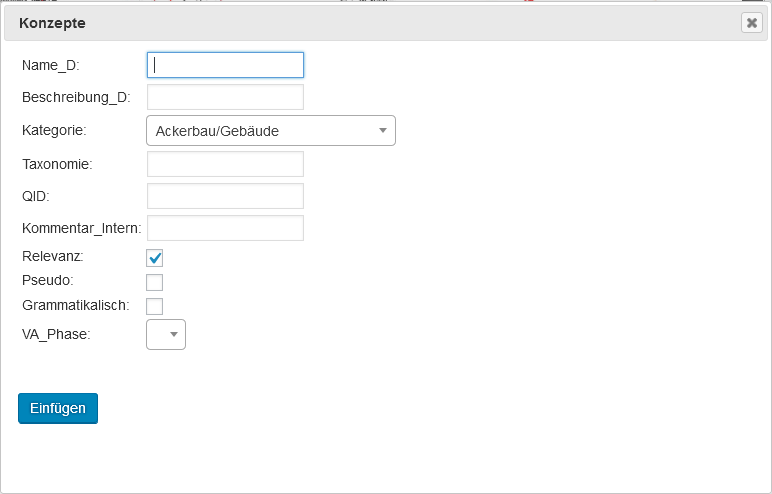
Eingabeformular bei der Anlage von Konzepten
Name_(DIFRSE)/Beschreibung_(DIFRSE):
Möchte man bei der Transkription oder der Typisierung Belege mit einem bestimmten Konzept verknüpfen, so sucht man zuerst, ob dieses Konzept schon angelegt wurde. Hier lohnt es sich, mehrere Suchanfragen zu starten, denn nicht immer ist das Konzept unter dem ersten Wort verzeichnet, das einem in den Sinn kommt. Folgendes Beispiel soll dies näher erläutern. Im Bayerischen Sprachatlas findet sich z.B. ein Stimulus "Weibl. Zuchttier nach dem Werfen (bei Schweinen)" (BSA 0381). Hier könnte man natürlich nach Begriffen wie "Zuchttier" suchen, es wird sich jedoch bald zeigen, dass diese Suche keine Treffer bringt. Auf der Suche nach "Schwein" könnte es zuerst den Anschein haben, dass dieses Konzept nicht existiert und würde es nahelegen, dieses anzulegen. Eventuell wurde aber das Kozept als "SAU" angelegt, ohne dieses näher zu beschreiben. Oft ist es der Fall, dass fälschlicherweise ein einzelner Begriff im Feld 'Beschreibung_D' steht, obwohl dieser im Feld 'Name_D' stehen sollte. Im Falle von Sau sollte also im Feld 'Name_d' "SAU" und in 'Beschreibung_D' "SCHWEIN, WEIBLICH" stehen. An solch ein bereits bestehnde Konzept sollte sich beim Anlegen von ähnlichen Konzepten orientiert werden, d.h. die Differenzierung des Konzepts findet am Ende des Beschreibungs-Textes statt, während der vordere Teil allgemeiner gehalten wird, z.B. "SCHWEIN, WEIBLICH, GESCHLECHTSREIF" oder "SCHWEIN, WEIBLICH, NACH DEM WERFEN" usw. Als Faustregel könnte man sagen: je ähnlicher sich Konzepte in der Realität sind, umso ähnlicher sollten auch die Konzeptbeschreibungen sein. Ein anderes Beispiel: "GEFÄSS ZUM TRANSPORT AUF DEM RÜCKEN FÜR MILCH AUS HOLZ" ist Teil des Konzepts "GEFÄSS ZUM TRANSPORT AUF DEM RÜCKEN" und dieses ist wiederum Teil des Konzepts "GEFÄSS ZUM TRANSPORT". Dass diese Konzeptbeschreibungen nicht schön aussehen und auch nicht den normalen Sprachgebrauch widerspiegeln, ist hier nicht schlimm. Grundsätzlich sollte in Name-Feld als auch im Beschreibung-Feld etwas eingetragen werden, oft ist dies aber nicht möglich, da das Konzept so komplex ist oder es in der Standardsprache kein entsprechendes Wort gibt. Für die deutschsprachigen Konzepte verwendet ihr bitte Großbuchstaben, Kommata und Umlaute, nicht aber das große scharfe S "ẞ". Seid Ihr Euch unsicher, sammelt Eure Problemfälle und teilt sie uns mit.
Kategorie:
Bei der Auswahl der Kategorie sucht die aus, die am besten passt. Solltet ihr Euch unsicher sein, dann gilt auch hier, wie beim Aufbau der Konzeptbeschreibung, wieder: nachschauen, ob ähnliche Konzepte schon existieren. Den Begriff "Ähnlichkeit" kann man dabei sehr weit gefasst sehen. Müsst ihr z.B. das Konzept für einen Körperteil der Kuh anlegen, in der Tabelle wurde aber noch kein einziges Körperteil der Kuh erfasst, könnt ihr dann ggf. ja bei anderen Tieren schauen, ob dort schon etwas Ähnliches eingetragen wurde, z.B. "HORN DER KUH" vgl. "HORN DER ZIEGE".
Taxonomie:
Das Feld "Taxonomie" ist bei der Erfassung von botanischen Konzepten oder der Tierwelt wichtig. Hier soll einfach der botanische Name z.B. Vaccinium myrtillus für 'Heidelbeere'oder der wissenschaftliche Name für das Tier wie Passer domesticus für 'Haussperling' eingetragen werden.
QID:
Im Feld "QID" sucht ihr nach der QID, die dem Konzept in Wikidata zugeordnet ist. Dazu geht ihr am besten auf die Wikipediaseite selbst und wählt beim Artikel links "Wikidata-Datenobjekt". Die ID findet ihr dann gleich hinter der meist englischen Bezeichnung der Sache.
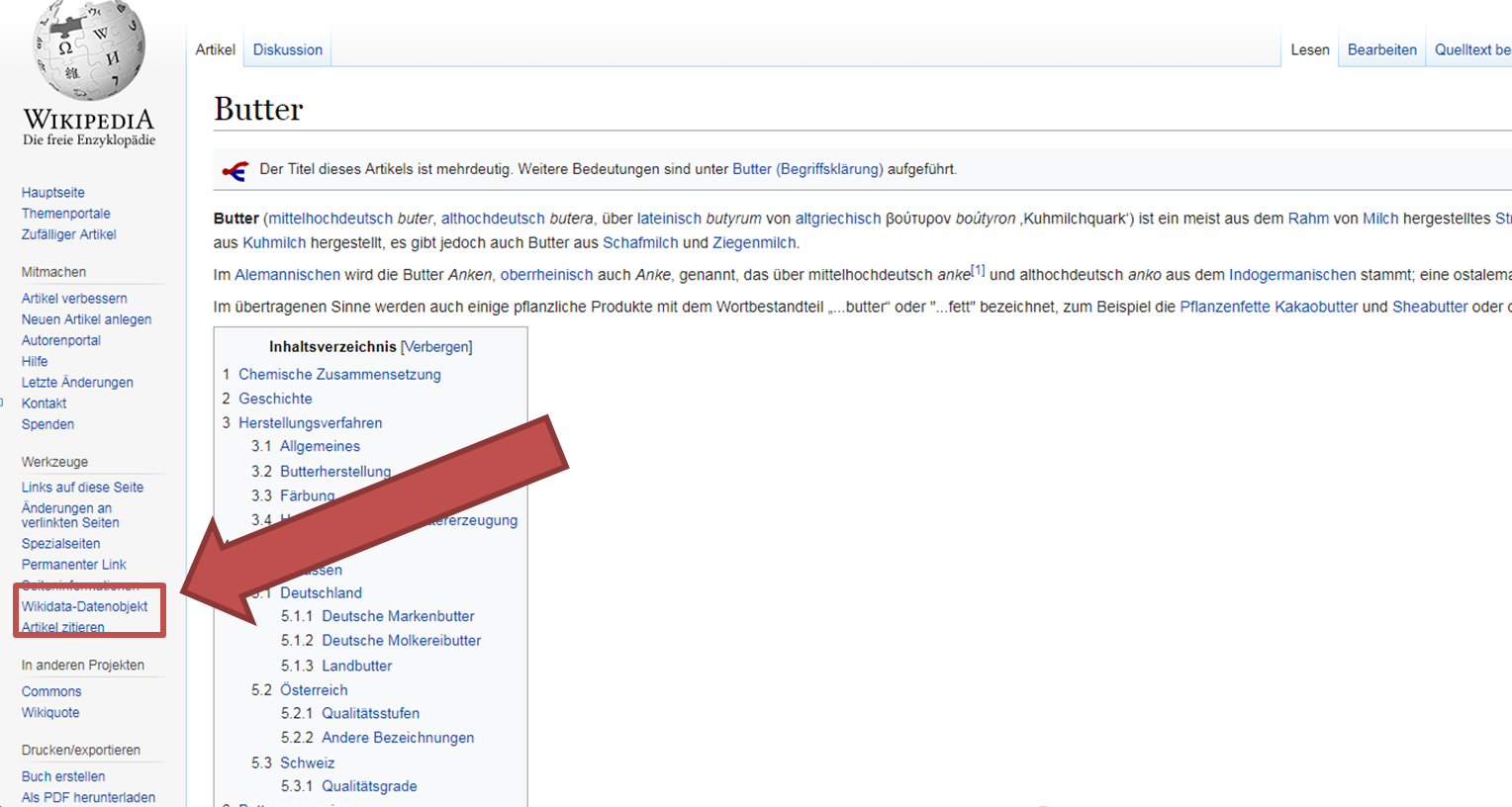
Beispiel Wikidata-Datenobjekt
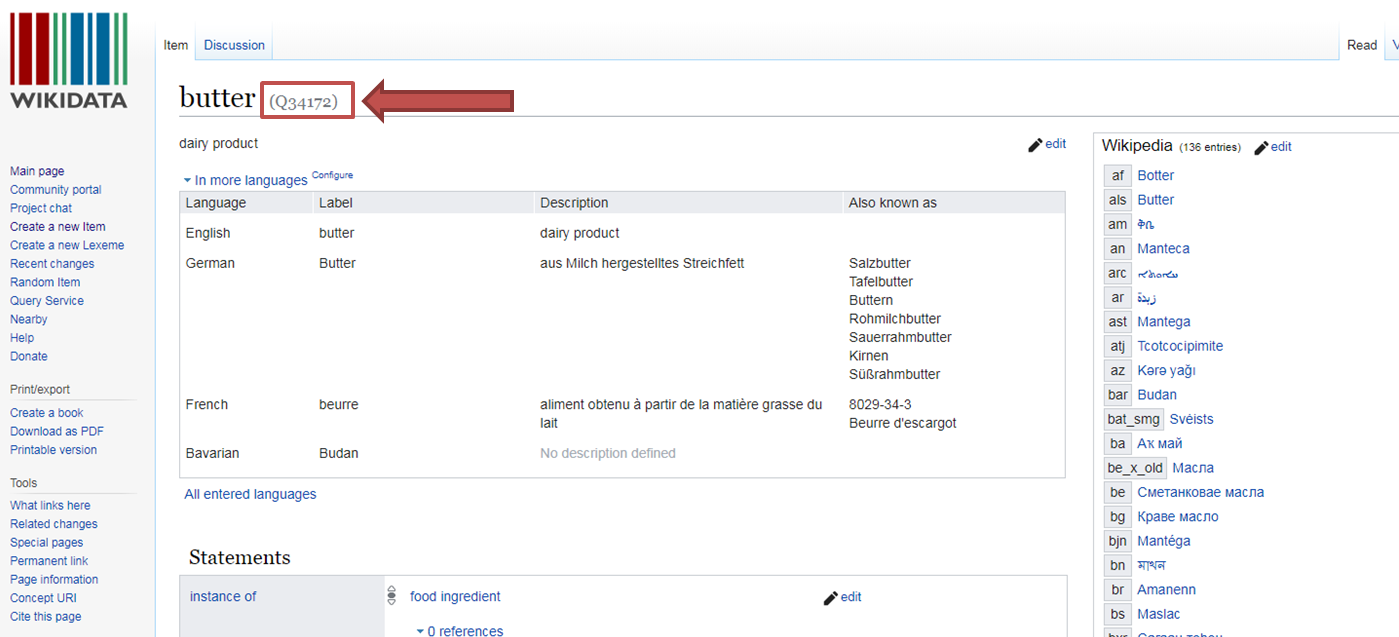
Stelle des Q-IDs in Wikidata
Da es zu Tätigkeiten in der Regel allerdings keine Wikipedia-Artikel gibt, empfiehlt es sich, die ID direkt über das Wikidata-Portal zu suchen. Tendenziell sind mehr QIDs über den englischen Begriff zu finden, z.B. "drinking".
Kommentar_Intern:
Bei "Kommentar_Intern" solltet Ihr einen kurzen Vermerk schreiben, was der Anlass war, dass Ihr das Konzept angelegt habt. Hier reicht wirklich nur eine kurze Notiz, die z.B. auf eine Karte im Atlas Bezug nimmt wie "AIS 223" oder, falls der Vorschlag für das Konzept von einem Crowder stammt "Vorschlag von Crowder: crowder".
VA_Phase:
Zuletzt solltet Ihr noch die Nummer der jeweiligen Konzeptphase unter "VA_Phase" eintragen.
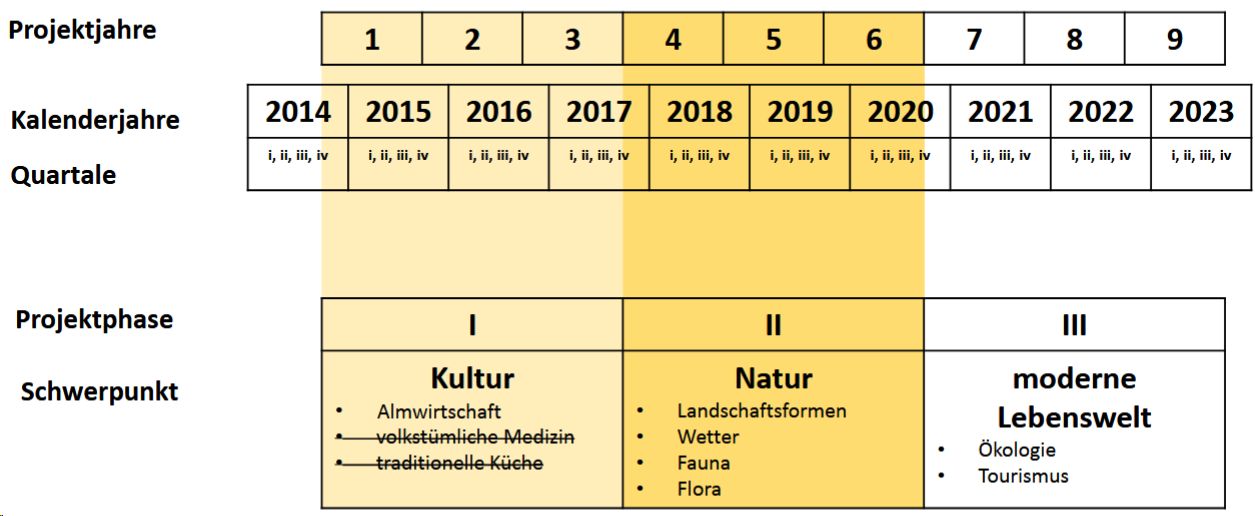
Projektphasen in VerbaAlpina
4. Datenbank
Die Datenbank muss nicht immer verwendet werden und der Zugang dazu wird nicht immer benötigt. Allerdings ist der Zugang zu ihr sehr nützlich, deshalb Datenbank-Zugang beantragen (bei den Informatikern) und den immer parat halten.
Bei manchen Aufträgen ist es notwendig, direkt in die Datenbank zu schauen. Die dafür notwendigen Abfragen werden in der Regel von den wissenschaftlichen Mitarbeitern bereitgestellt und erläutert.
5. Nachhaltigkeit
- Datenversionierung
- Backups und Archivierung
- Dokumentation in der Rubrik "Methodologie"
- Aufnahme in Kataloge der DNB
6. Technisches bzw. Organisatorisches
Um von Zuhause aus zu arbeiten, muss man eine VPN am Laptop installieren; Informationen und Anleitungen findet man unter folgendem Link: https://www.lrz.de/services/netz/mobil/vpn/anyconnect/ [Zugriff am 21/08/2019]
Im Büro arbeiten: Ein Rechner steht im VA-Büro zur Verfügung. Am besten trägt man sich in die Liste ein, damit die Arbeitszeiten sich nicht überschneiden. Gerade zu Beginn von neuen Aufgaben, empfiehlt es sich, dass ihr euch mit den wissenschaftlichen Mitarbeitern abspricht, weil in dieser Phase noch Fragen auftreten können.
Kommunikation: Am Besten alles kommunizieren, was gerade eure Beschäftigung ist usw.; das hat in erster Linie einen planungstechnischen Hintergrund, damit wir die nächsten Aufgaben vorbereiten können.