


Thomas Krefeld (LMU)
1. Wissenschaftskommunikation im Internet
Forschungsmittel sind begrenzt; der Zugang dazu muss also kompetitiv geregelt sein. Wenn Forschung in dieser Hinsicht zwar dem Wettbewerb unterliegt, so ist sie doch in ihrem Wesen vor allem kollaborativ: Denn Fortschritt gibt es nur auf der Grundlage des jeweils bereits verfügbaren Wissens. Im Hinblick auf die Kollaboration – die ja grundsätzlich in Kommunikation fundiert ist – haben sich nun in den letzten 15 Jahren die Rahmenbedingen vollkommen geändert: Es ist innerhalb weniger Jahre eine Gesellschaft entstanden, die explizit als Wissensgesellschaft bezeichnet wird, da sie im Privaten und im Öffentlichen die permanente und ubiquitäre Verfügbarkeit der Neuen Medien und damit einen praktisch unbegrenzten Zugang zum Wissen jeglicher Art voraussetzt.
Diese vollkommene Mediatisierung betrifft aber nicht nur den Wissenskonsum, sondern gleichermaßen die Wissensgenerierung durch Forschung, nicht zuletzt deshalb, weil sie uns eine sehr breite, ortsunabhängige Kooperation ermöglicht. Ins Schlaraffenland sind die Forscher damit freilich nicht gelangt, denn die Option auf Kooperation konkretisiert sich keineswegs automatisch. Sie erfordert vielmehr die Beachtung einiger elementarer Regeln, die seit kurzem mit der Sigle FAIR benannt werden, die von einer wichtigen Initiative lanciert wurde (🔗). Damit werden vier grundlegende ethische Prinzipien für die Wissenschaftskommunikation unter den Bedingungen der Neuen Medien identifiziert. Ihnen zufolge müssen Forschungsdaten
- F_indable (‘auffindbar’),
- A_ccessible (‘zugänglich’),
- I_nteroperable (‘kompatibel’),
- R_eusable (‘nachnutzbar’)
sein (🔗). Die Anforderungen von drei (F, A, R) der vier Prinzipien zielen darauf sowohl human readable als auch machine readable zu sein; sie gelten also sowohl für die Mensch-Maschine-Mensch-Kommunikation als auch für die Maschine-Maschine-Kommunikation. Das vierte Prinzip (I) gilt nur für letztere; es ist jedoch im skizzierten virtuell-medialen Rahmen zentral für den Fortschritt der Forschung und repräsentiert insofern die Unverzichtbarkeit der technologischen Komponente und die Transformation des LESERs zu einem interaktiven NUTZER, der auf einem Kontinuum zwischen hochspezialisierten Experten und völligen Laien abgebildet werden kann und der sich den Daten nicht nur lesenden Auges nähert, sondern womöglich mit der Absicht sie für eigene Forschungszwecke zu nutzen und dafür maschinelle ‘Erntehelfer’ (zum sog. harvesting) einzusetzen.
Die Operationalisierung der FAIR-Prinzipien erfordert ein komplexes Zusammenspiel von Forschern, das heißt de facto von befristeter und deshalb mehr oder weniger prekärer Projektarbeit einerseits und andererseits von Institutionen, die Dauerhaftigkeit in Aussicht stellen können; das sind in allererster Linie die großen Bibliotheken. Die Entwicklung von Prozeduren für diese ganz spezielle Art der Kooperation gehört zu den aktuellen Herausforderungen der Forschung, die mit dem Ausdruck Forschungsdatenmanagement (FDM) bezeichnet werden. Damit sind wichtige Eckpunkte der Wissenschaftskommunikation im Web markiert, die den Horizont dieses Beitrags abstecken.
2. FAIRness in einer web-basierten Forschungsumgebung
Das Projekt VerbaAlpina (VA) versucht die Forschungskommunikation im oben skizzierten Sinne konsequent nach den FAIR-Prinzipien zu gestalten. Dabei ist ihre Anwendung in den folgenden fünf komplementär angelegten und eng miteinander verflochtenen Funktionsbereichen (🔗) zu unterscheiden:
- Dokumentation;
- Publikation;
- Kooperation;
- Datenerhebung durch crowdsourcing;
- Forschungslabor.
2.1. FAIRness der Publikation
Das ganze Internet ist nichts Anderes als eine gewaltige Publikationsmaschine; es ist allerdings unbedingt notwendig zu differenzieren, denn es wird durchaus anders und teils auch Anderes als unter den medialen Bedingungen des Drucks publiziert wird. Von VerbaAlpina werden
- semantischer Inhalt (Dialektformen, analytischer wissenschaftlicher Text),
- Metadaten,
- Software und Code
veröffentlicht (🔗).
Produziert wenrden dabei ausnahmslos stabile Daten und Textdateien, da die gesamte Plattform (Benutzeroberfläche und Datenbanken) alle sechs Monate ‘eingefroren’, oder: versioniert wird; zusätzlich besteht jeweils eine aktuelle Arbeitsversion (Version xxx), die noch Änderungen unterliegt und daher nicht zitiert werden sollte (🔗). Die jeweils jüngste Version ersetzt jedoch nicht die vorige, sondern ergänzt sie, denn alle früheren Versionen bleiben erhalten, so dass sämtliche Zitate und Verlinkungen innerhalb des Projekts sowie von außen auf das Projekt stets zugänglich sind.
Es ist weiterhin sichergestellt, dass die Versionen gut auffindbar sind, denn ihnen wird von der UB der LMU ein DOI zugewiesen (http://dx.doi.org/10.5282/verba-alpina); gleichzeitig findet VA als Ganzes damit Eingang in die Biblibliothekskataloge (🔗).
Auf dieselbe Weise lassen sich auch alle thematischen Textbeiträge identifizieren, die auf der Projektseite unter den Reitern Lexicon alpinum, Methodologie und Beiträge publiziert werden; sie erhalten ebenfalls einen DOI und sind daher direkt zitierfähig (vgl. z.B.: Krefeld, T. / Lücke, S.: s.v. “butyru(m)”, in: VA-de 18/2, Lexicon alpinum, http://dx.doi.org/10.5282/verba-alpina?urlappend=%3Fpage_id%3D2374%26db%3D182%23B128).
Eine vergleichbare Funktion leistet der URN, der bei der Deutschen Nationalbibliothek in Frankfurt registriert wird. Schließlich ist auch der gesamte Quellcode von VA mit allen programmierten Tools unter github auffindbar und zugänglich.
Technisch gesehen liegt dem Verfahren ein Export aller VA-Dateien in ein Repositorium der UB zu Grunde (open data lmu) in dem auch Metadaten im Format DataCite zugewiesen werden. Eine große Rolle bei der Ausgestaltung der Metadatenschemata spielen die Normdaten, die eine eindeutige und fein granulierte Identifikation der Forschungsdaten erlauben. VA unterscheidet drei Datenkategorien (oder: Entitäten), für die eigene Identifikatoren vergeben werden, die in Verbindung mit den Daten abrufbar sind: ‘Konzept’, ‘morpholexikalischer Typ’ (s. Typisierung) und ‘Gemeinde’. So ergeben sich sehr spezifizierte Metadaten (vgl. das DataCite Beispiel für das Konzept SENNHÜTTE, das neben dem VA-Identifikator C1 auch die in VA ebenfalls vorhandenen onomasiologischen Identifikatoren des Wikidata-Projekts enthält: Q136689, Q27849269, Q2649726).
Dieser Export gewährleistet die Zugänglichkeit und Nachnutzbarkeit der Daten nach dem Auslaufen der Projektförderung. Der Datenexport erfolgt über eine API-Schnittstelle (vgl. API Dokumentation), die im Internet öffentlich zugänglich ist und daher auch für die Vergabe anderer Metadatenschemata, z.B. gemäß CLARIN-D, benutzt werden kann. Einen groben Überblick des im Entstehen begriffenen Forschungsdatenmanagements (Stand vom 11.3.2019) gibt das folgende Schema:
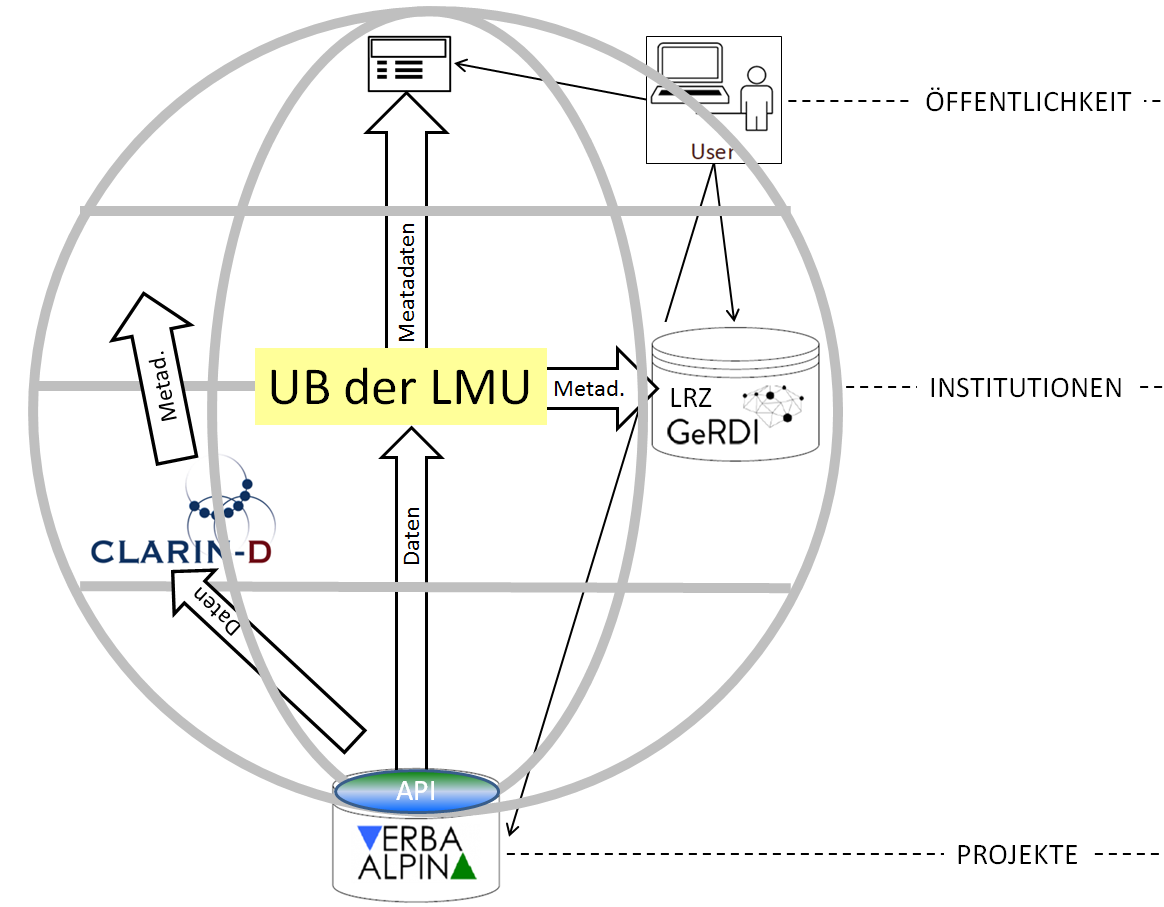
Forschungsdatenmanagement zwischen Projekten, Institutionen und Öffentlichkeit
Im Hinblick auf die Auffindbarkeit und Zugänglichkeit sind noch zwei grundsätzliche Bemerkungen angebracht:
- Da bislang in der Wissenschaftsgemeinde weder ein Standard-Metadatenschema verbindlich festgelegt noch die Frage geklärt ist, welche Institutionen über deren Einhaltung und die dauerhafte Bewahrung von Daten und Metadaten wachen sollen, hat sich VA zum einen für ein flexibles Schnittstellenkonzept entschieden, das die Nutzung im Grunde beliebiger Metadatenschemata erlaubt. Außerdem beteiligt sich VA an zwei aktuell laufenden Forschungsprojekten, die sich mit dieser Problematik auseinandersetzen: der Initiative (GeRDI) des LRZ und dem von der Bayerischen Staatsregierung geförderten Projekts e-humanities – interdisziplinär. Im Projekt GeRDI sollen Daten ganz unterschiedlicher Disziplinen über Metadaten verknüpft werden, indem gemeinsame Attribute festgelegt werden (was z.B. im Fall von Geo- und Chronoreferenzierungen sehr einfach und häufig auch sinnvoll ist).
- Abgesehen von den Metadaten, die auf die spezifischen Projektdaten referenzieren, ist es im Sinn von Auffindbarkeit und technischer Interoperabilität unbedingt ratsam, Identifikatoren und Normdaten zu verwenden, die außerhalb des Projekts etabliert sind. VA verwendet daher seit kurzem die Identifikatoren der sogenannten Wikidata-Datenobjekte. Sie liefern Referenzen für außersprachliche Realitäten und Konzepte und damit einen gemeinsamen Bezugsrahmen für viele unterschiedliche Sprachen; so gibt es derzeit (14.12.2018) Wikipedia-Artikel in 133 Sprachen über das Milchprodukt Butter. Die sehr unterschiedlichen Artikel werden verknüpft, indem sie alle auf den eindeutigen Identifikator des entsprechenden Wikidata-Datenobjekts referenzieren (Q34172). Eine Suchmaschine, die danach sucht, ist also in der Lage, alle zugehörigen 133 Bezeichnungen zu finden – und so demnächst auch die in VA dokumentierten, zahlreichen Dialektformen (1926 Belege). Ein ähnliches System für Bezeichnungstypen, d.h. für Wörter (L-ID), ist im Aufbau (und sollte unbedingt auch auf morpho-syntaktische Kategorien ausgeweitet werden).
2.2. FAIRness der Dokumentation
VA dokumentiert Dialektbelege der drei großen europäischen Sprachfamilien, die sich in ethnolinguistischer Hinsicht als spezifisch alpin erweisen.
Das Material wurde in einen systematisch strukturierten Datenbestand überführt und nach sprachlichen (‘morpho-lexikalische Typen’, ‘Basistypen’) und außersprachlichen (‘Konzepte’) Kritierien annotiert; neben dem maschinenlesbaren Zugang über die oben erwähnte API-Schnittstelle gibt es einen menschenlesbaren Zugang, der in sehr anschaulicher Weise über eine interaktive Karte erfolgt; die dafür momentan noch genutzte Google Maps-Karte wird in Kürze durch eine bereits weitestgehend entwickelte Karte mit verbesserter Funktionalität auf der Grundlage von Open Street Maps ersetzt (🔗 ).
Die genannten Kategorien der Datenstrukturierung fungieren an der Kartenoberfläche als Filter. Bereits auf dieser nutzerfreundlichen, insbesondere laientauglichen Oberfläche wurde eine ebenso einfache wie elementare Funktion der reusability implementiert, denn es ist möglich, alle Karten, die man sich anzeigen lässt, in exakt der angezeigten Form (mit der entsprechenden Zoomstufe, jeweils geöffneten Fenstern usw.) mit anderen zu teilen oder sie in Publikationen usw. einzubauen, denn durch Klicken auf einen 'share button' wird für die jeweils aktuell angezeigte Karte eine versendbare URL erzeugt; so führt der folgende Link zu einer Karte aller in VA vorhandenen dialektalen Bezeichnungen (derzeit 1748 Belege) von BUTTER.
Das vorhandene Sprachmaterial stammt aus zwei Quellen: Ein kleinerer Teil des Materials, das VA anbietet wurde durch das Projekt selbst im Crowdsourcing-Verfahren (s.u. 2.4.) erhoben. Der größte Teil wurde jedoch aus gedruckten oder für den Druck vorgesehenen Arbeiten gewonnen, so finden sich auch Formen, die uns im Rahmen von Partnerschaftsabkommen aus noch nicht abgeschlossenen Projekten zur Verfügung gestellt wurden (vgl. zum Beispiel das Punktnetz des Sprachatlas von Oberösterreich). Berücksichtigt wird auch Wörterbuchmaterial, unter der Bedingung, dass die sprachlichen Belege georeferenzierbar sind; das ist bei guten Dialektwörterbüchern wie zum Beispiel dem DRG oder dem VSI der Fall. De facto ist jede Quelle auch chronoreferenzierbar, aber diese Funktion wurde noch nicht implementiert.
Durch die Retrodigitalisierung und den Webauftritt werden zahlreiche, in teils schwer zugänglichen Publikationen ‘schlafende’ Dialektausdrücke leicht auffindbar (F), zugänglich (A), interoperabel (I) und in allgemein kompatibler Weise nachnutzbar (R) gemacht; denn alle verfügbaren Formen erhalten einen persistenten Identifikator und werden in Kürze auch über einen Digital Object Identifier (DOI) ansprechbar sein. Hier ein Beispiel aus dem Sprach- und Sachatlas Italiens und der Südschweiz, AIS (1928-1940).
VA produziert also gewissermaßen FAIRen Output; allerdings sind die allermeisten Quellen, der Input, von FAIRness meilenweit entfernt; die Gründe dafür sind teils technischer, teils aber auch juristischer, letztlich: kommerzieller Art. In der Regel sind Sprachatlanten ausschließlich als physisches Druckwerk zugänglich; nur sehr wenige bieten wenigstens die elementarste Stufe der Digitalisierung, d.h. digitale Photos (scans) an, wie z.B. der AIS in Gestalt des NavigAIS oder der SDS im Hinblick auf das Orginalmaterial. Kein einziger älterer Atlas wurde bislang in Form eines strukturierten Korpus aufbereitet, das auch den Export der Daten gestattet. Immerhin konnte eine solche Lösung auf der Basis einer Kooperationsvereinbarung für den ALD gefunden werden; dem Druck dieses Atlas’ von Hans Goebl lag ein digitales Format zu Grunde, das zwar wegen fehlender Identifikatoren der Inhalte nicht interoperabel war, sich aber nach bestimmten Adaptationen als maschinenlesbar und entsprechend nachnutzbar erwies; alle Bezeichnungen relevanter Konzepte erscheinen daher in VerbaAlpina (vgl. das ALD-Ortsnetz und dieses Beispiel).
| Findable | Accessible | Interoperable | Reusable | ||||
| menschl. | masch. | menschl. | masch. | masch. | menschl. | masch. | |
| ALI | - | - | - | - | - | - | - |
| SDS | + | + | + | - | - | + | - |
| AIS | + | + | + | - | - | + | - |
| ALD | + | + | + | - | - | + | + |
| VA | + | + | + | + | + | + | + |
Anders, deutlich komplexer erscheint die Lage im Bezug auf georeferenzierbare Wörterbücher; die seit kurzem verfügbare Online Version des DRG ist so eingerichtet, dass jedes Lemma dank eines Identifikators als digitales Objekt zugänglich ist (A), so zum Beispiel bargia ‘Schopf’; ein maschineller Export ist jedoch nicht vorgesehen. Andere, wie der Niev Vocabulari sursilvan online bieten selbst diese Möglichkeit nicht an, so dass an Interoperabilität nicht zu denken ist.
2.3. FAIRness der Kooperation
VA wird von zahlreichen Partner-Projekten unterstützt; das große Potential dieser Kooperation ist selbstverständlich und bedarf eigentlich keiner Erwähnung. Dennoch soll die konstruktive Perspektive der mehrfachen und komplementären Nachnutzung kompatibler Partnerprojekte an einem Beispiel illustriert werden: Im Rahmen des Archivio lessicale dei dialetti trentini (ALTR) wurden fünf gedruckte Dialektwörterbücher unterschiedlicher Talschaften (aus der Zeit zwischen 1955 und 1984) in einer Datenbank zusammengeführt. Dank einer Projektpartnerschaft konnte VA die relevanten Ausdrücke konvertieren und importieren, so dass sie nun im Kontext aller Alpendialekte kartographisch dargestellt werden können; vgl. die folgende Bezeichnung eines Geräts zum Buttern: smalzaia).
Als interoperabel in der Kooperation hat sich auch die Projektarchitektur und die entsprechende Software bereits erweisen; so konnte probeweise das sizilianische Regional- und Spezialwörterbuch von Sottile 2002 ohne Schwierigkeiten nachgenutzt und als Atlas dargestellt werden (vgl. Atlante linguistico della Sicilia online ); seit dem Herbst 2018 greift auch der im Entstehen begriffene Atlas des Pikardischen in Nordfrankreich und Belgien auf die Konzeption und Technologie von VA zurück (vgl. Verba Picardia).
2.4. FAIRness im Crowdsourcing
Crowdsourcing-Verfahren richten sich in allererster Linie, wenngleich nicht ausschließlich, an Laien; sie setzen deshalb eine intuitiv leichte Auffindbarkeit und Zugänglichkeit zentraler Datenbereiche für menschliche Nutzer voraus. Die Daten werden durch die Art der Erhebung in ein strukturiertes und interoperables Format gebracht, das Nachnutzung gestattet. VA nutzt crowdsourcing in doppelter Weise: Zunächst wurde ein ästhetisch ansprechendes und einfach zu bedienendes Tool zur Datenerhebung programmiert (Mitmachen!); dafür wurde auch ein Tutorial auf Youtube gepostet. Ferner wurde soeben ein Zooniverse-Auftritt eingerichtet, um die für Retrodigitalisierung erforderliche Transkriptionsarbeit wenigstens teilweise an die Crowd weiterzugeben (🔗). Auch dafür ist Interoperabilität der VA-Datenbasis die Voraussetzung.
Das Erhebungstool wurde durch populärwissenschaftliche Vorträge in der Erwachsenenfortbildung einschlägiger Berufsgruppen (am 20.4.2018, 26.2.2018, 7.10.2017) beworben und fand daneben auch ein schönes massenmediales Echo. Die Auswertung ist interessant, denn es zeigt sich, dass vorallem Projektberichte im Internet relevant sind, da dort über einen Link ein direkter, sozusagen intramedialer Zugang angeboten werden kann: Das mit Abstand stärkste Echo fand deshalb ein Post auf der Internetseite des Bayerischen Rundfunks (am 27.4.2018); insgesamt wurden durch die 955 ‘Crowder’ bislang 11486 Dialektformen (Stand: 12.3.2019) beigesteuert (🔗).
Bibliographie
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7
- ALD = Eintrag nicht gefunden
- ALI = Bartoli, Matteo / Massobrio, Lorenzo / Pellis, Ugo (1995ff.): Atlante linguistico italiano, Roma, Ist. Poligrafico e Zecca dello Stato
- DRG = De Planta, Robert/ Melcher, Florian/ Pult, Chasper/ Giger, Felix (1938ff.): Dicziunari Rumantsch grischun, Chur, Inst. dal Dicziunari Rumantsch Grischun. Link
- SDS = Baumgartner, Heinrich/ Handschuh, Doris/ Hotzenköcherle, Rudolf (1962-2003): Sprachatlas der Deutschen Schweiz, Bern, vol. 1-9, Francke
- Sottile 2002 = Sottile, Roberto (2002): Lessico dei pastori delle Madonie, Palermo, Centro di studi filologici e linguistici siciliani. Link
- VA = Krefeld, Thomas | Lücke, Stefan: VerbaAlpina, München, Ludwig-Maximilians-Universität München. Link
- VSI = Sganzini, Silvio (1952ff): Vocabolario dei dialetti della Svizzera italiana, Lugano, Tipografia la Commerciale