


Stephan Lücke
| Ringrazio Alessia Brancatelli per la traduzione in italiano.1 |
Complementarmente alla necessità di definire i singoli tipi di base a livello qualitativo nella stratigrafia dell'area linguistica alpina – così come precedentemente dimostrato da Thomas Krefeld – è possibile stabilire quantitativamente come tutti i tipi morfo-lessicali diffusi nella regione alpina, benché appartenenti a famiglie linguistiche diverse, facciano riferimento a tipi di base comuni, e come questi presuppongano un qualche tipo di contatto linguistico. Lo stesso vale per tutti i tipi di base preromani o latini che hanno trovato la loro strada nella lingua germanica o nello slavo; non certamente per i tipi di base latini migrati nel romanzo.
Con ''tipo di base'', VerbaAlpina definisce i più antichi tipi morfo-lessicali in cui è possibile riconoscere una precisa radice lessemica. Si prendono quindi sostanzialmente in esame parole latine, parole dal substrato preromano, dal greco, dal celtico, dal germanico o, ancora, dallo slavo. Laddove sia possibile, viene inoltre eseguita un'identificazione delle stesse tramite i dizionari di riferimento del progetto, come ad esempio il dizionario di latino redatto da Karl Ernst Georges.
Per giudicare le possibilità e limiti del analisi dei dati tramite la banca dati di VerbaAlpina ci vuole avere almeno un'idea dell'organizzazione e strutturazione dei dati al interno del database.
VerbaAlpina raccoglie e organizza tutti i dati relativi alla lingua in diverse tabelle, le quali nella loro interezza formano un database su modello relazionale. Una di queste tabelle è dedicata al raggruppamento dei tipi di base. Essa ne documenta, oltre all'aspetto ortografico, anche l'appartenenza linguistica; le tabelle indicheranno in un prossimo futuro l'eventuale presenza dei tipi di base nei dizionari di riferimento.
Come solito nei database a modello relazionale, l'attribuzione dei tipi morfo-lessicali avviene tramite l'assegnazione di numeri di identificazione, i cosiddetti IDs. Nel più semplice dei casi, ad esempio, una tale assegnazione risulterebbe come segue:
La tabella dei tipi di base contiene il lemma "butyru(m) (lat)"
| ID_tipo_di_base | tipo_di_base |
| 128 | butyru(m) (lat) |
Similmente strutturata è la tabella contenente i tipi morfo-lessicali. Anche qui, infatti, ogni lemma viene chiaramente identificato tramite un ID:
| ID_tipo_morfo-lessicale | tipo_morfo-lessicale |
| 591 | beurre / burro |
Nel più semplice dei casi, l'assegnazione di un tipo di base ad un tipo morfo-lessicale avviene tramite l'inserimento dell'ID del tipo di base in uno spazio ad esso dedicato nella tabella dei tipi morfo-lessicali:
| ID_tipo_morfo-lessicale | tipo_morfo-lessicale | ID_tipo_di_base |
| 591 | beurre / burro | 128 |
In particolare nel caso dei composti tedeschi, è possibile che un tipo morfo-lessicale venga associato non ad uno, bensì a due tipi di base. È questo il caso ad esempio della parola composta tedesca Alphütte, la quale da un lato rimanda al tipo di base "alpes" e dall'altro al tipo di base "hutta". In questo caso, la tabella sarà così strutturata:
| ID_tipo_di_base | tipo_di_base |
| 53 | alpes (vor) |
| 48 | hutta (ger) |
| ID_tipo_morfo-lessicale | tipo_morfo-lessicale | ID_tipo_di_base |
| 7 | Alphütte | 53, 48 |
Data la poca praticità dell'inserimento concatenato di entrambi gli IDs dei tipi di base nella tabella dei tipi morfo-lessicali, si rende necessario l'impiego di un'ulteriore ''tabella di mezzo'', in cui venga inserita la combinazione dei due numeri di identificazione:
| ID_tipo_morfo-lessicale | ID_tipo_di_base |
| 7 | 48 |
| 7 | 53 |
Il database opera, infine, una logica combinazione sinottica delle tre tabelle, combinazione che può essere così rappresentata:
| ID_tipo_morfo-lessicale | tipo_morfo-lessicale | ID_tipo_di_base | tipo_di_base |
| 7 | Alphütte | 53 | alpes (vor) |
| 7 | Alphütte | 48 | hutta (ger) |
Proprio come accade con ogni tipo di base, ad ogni tipo morfo-lessicale viene assegnata una lingua. Le rispettive appartenenze linguistiche vengono registrate nelle tabelle come caratteristiche a sé stanti, ma possono anche essere inserite e collegate nelle relazioni sinottiche finora mostrate:
| ID_tipo_di_base | tipo_di_base | lingua_tipo_di_base | ID_tipo_morfo-lessicale | tipo_morfo-lessicale | lingua_tipo_morfo-lessicale |
| 724 | thûmo | goh | 639 | dûmli(n)ge(n) | ger |
| 336 | caldaria | lat | 2400 | chaudière / caldaia | rom |
| 392 | campus | lat | 525 | ciampei | rom |
| 478 | klětь | sla | 1714 | klet | sla |
| 1165 | prīmus | lat | 6519 | prime / primo | rom |
I numeri di identificazione servono solamente per una corretta assegnazione; nella rappresentazione grafica, essi possono anche essere omessi in modo tale da visualizzare l'immagine in modo più chiaro:
| tipo_di_base | lingua_tipo_di_base | tipo_morfo-lessicale | lingua_tipo_morfo-lessicale |
| *þūmōn | ger | dûmli(n)ge(n) | ger |
| caldaria | lat | chaudière / caldaia | rom |
| campus | lat | ciampei | rom |
| klětь | sla | klet | sla |
| prīmus | lat | prime / primo | rom |
In una banca dati così strutturata è, inoltre, possibile effettuare una ricerca mirata dei fenomeni di contatto linguistico. Sebbene i criteri di tale ricerca siano stati precedentemente illustrati da Thomas Krefeld, li esporremo adesso in modo formalizzato alla luce della struttura dei dati finora commentata.
Il modello semplice è rappresentato del caso che un tipo di base proveniente da una famiglia linguistica passa ad un'altra famiglia linguistica:
- Tipo di base latino/romanzo ⇒ tipo morfo-lessicale germanico
- Tipo di base latino/romanzo ⇒ tipo morfo-lessicale slavo
- Tipo di base germanico ⇒ tipo morfo-lessicale slavo
- Tipo di base slavo ⇒ tipo morfo-lessicale germanico
- Tipo di base germanico ⇒ tipo morfo-lessicale romanzo
- Tipo di base slavo ⇒ tipo morfo-lessicale romanzo
Nel caso più complesso un tipo di base proveniente da una famiglia linguistica passa a diverse altre famiglie linguistiche:
- Tipo di base latino/romanzo ⇒ tipo morfo-lessicale germanico e slavo
- Tipo di base latino/romanzo ⇒ tipo morfo-lessicale romanzo e germanico e ancora slavo
Per l'identificazione di questi schemi nella banca dati a modello relazionale, si formula la condizione per la quale i campi `lingua_tipo_di_base` e `lingua_tipo_morfo-lessicale` devono presentare dei valori precisi. La lingua del database SQL è l'inglese; per la ricerca di tipi di base latini passati al germanico, ad esempio, si scriverà quindi:
... where lingua_tipo_di_base = 'lat' and lingua_tipo_morfo-lessicale = 'ger'
Il risultato sarà il seguente (questo è solo un ritaglio):
| tipo_di_base | lingua_tipo_di_base | tipo_morfo-lessicale | lingua_tipo_morfo-lessicale |
| *brŏcca | lat | Britschger | ger |
| unguere | lat | Anke | ger |
| cūpella | lat | Kübel | ger |
| caseu(m) | lat | Käsestängel | ger |
| camera | lat | Milchkammer | ger |
| butyru(m) | lat | Butter | ger |
| unguere | lat | Ankentutel | ger |
| ... | ... | ... | ... |
È chiaramente possibile effettuare ulteriori calcoli sui risultati ottenuti. Si può, ad esempio, calcolare la frequenza con cui i tipi di base latini vengono rappresentati dai tipi morfo-lessicali germanici, i quali sono assegnati ad uno specifico dominio concettuale. Analisi statistiche di questo tipo vengono attualmente proposte come argomento di tirocinio universitario all'Istituto di Statistica dell'Università di Monaco di Baviera (LMU).
Per identificare i casi più complessi in cui un tipo di base ha trovato la propria strada in diverse altre famiglie linguistiche, è necessario raggruppare i dati per tipo di base, e concatenare i tipi morfo-lessicali alla propria appartenenza linguistica:

Il risultato che vedete è preso, come gli esempi seguenti, direttamenta dalla banca dati e viene aggiornato automaticamente nel caso di una modificazione dei dati nel database.
È da sottolineare, che gli esempi illustrati possono talvolta presentare errori dovuti alle incorrette identificazioni dei tipi di base, errori i quali verranno eliminati man mano che si lavorerà sui dati. L'idea fondamentale, al momento, è quella di presentare la metodologia adoperata dal progetto.
Attualmente, vuol dire fine giugno 2018, sono in tutto 14 i tipi di base esistenti in tutte le tre famiglie linguistiche; 32 sono quelli presenti nell'area linguistica romanza e germanica, 28 quelli presenti in romanzo e slavo, 7 quelli in germanico e slavo. Vi sono inoltre 32 tipi di base passati o nel germanico o nello slavo. La tabella qui in fondo presenta i valori attuali, presi direttamente dalla banca dati:
La struttura relazionale dei dati nel database assieme con la lingua SQL permette di eseguire analisi veramente complessi, almeno dal punto di vista informatico. L'esempio seguente mostra per ogni atlante linguistico le quantità dei tipi di base che sono connessi con tipi morfologici presenti in più di una famiglia linguistica (per il codice SQL vedi l'appendice):
Il modello dei dati utilizzato finora da VerbaAlpina presenta, tuttavia, delle debolezze. Ad oggi è solo possibile associare un tipo morfo-lessicale ad uno specifico tipo di base: si vedano ad esempio il tipo morfo-lessicale germanico "Käser" e il tipo romanzo "casera". La mappa sottostante mostra l'espansione dei tipi Käser (in verde) e casera (in giallo):
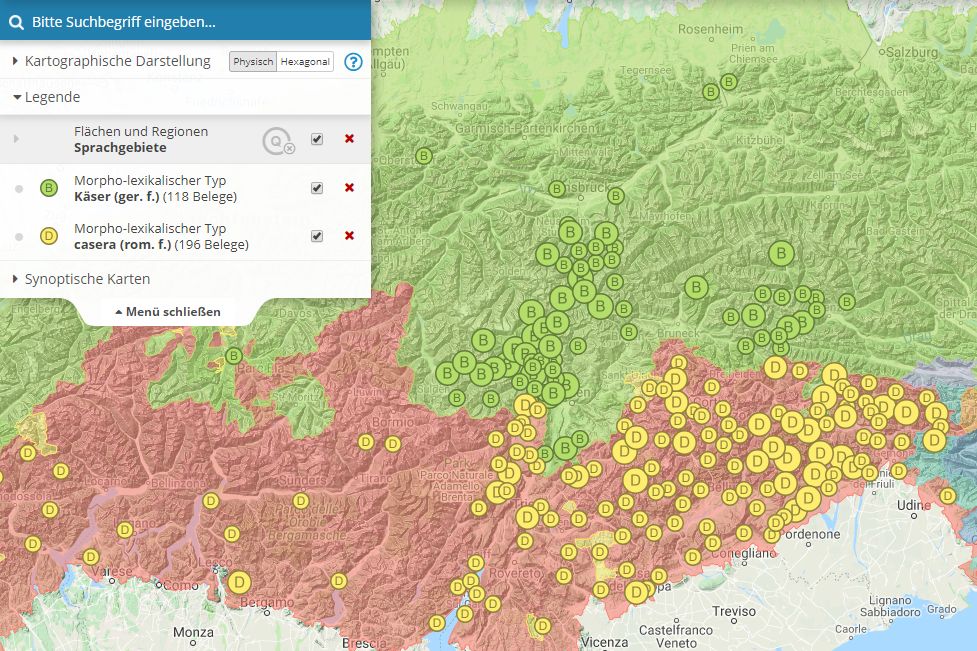
Diffusione dei tipi morfo-lessicali casera e Käser. La cartina online è accessibile sotto https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=xxx&tk=1591
Entrambi i tipi sono derivati senza dubbio dal latino casearius, a sua volta ricollegabile a caseus. Sorge, dunque, spontaneo chiedersi quale tipo di base si debba scegliere: casearius o caseus? Al momento, entrambi i tipi morfo-lessicali sono ricollegabili al tipo di base caseus, fatto che li lega anche ad altri tipi morfo-lessicali, quali ad esempio il tedesco Käse. Ciò si traduce in una certa asimmetria, dal momento che esiste una relazione più stretta tra Kaser e casera che tra Kaser e Käse. Ora, se assegnassimo Kaser e casera al tipo di base casearia, la connessione con Käse andrebbe chiaramente persa. Come comportarsi, dunque, in questo caso? Una possibilità sarebbe quella di differenziare ulteriormente la mappatura dei tipi di base nello schema dei dati, in modo tale da documentare la relazione tra il latino casearius e caseus.
Il confine tra le aree di diffusione dei due tipi morfo-lessicali corre esattamente lungo il confine tra il germanico (in verde) e il romanzo (in rosso). Vi sono anche altre aree, come quella slava, come pure una serie di zone di transizione ed enclavi, al momento dominate dal multilinguismo. La distinzione tra appartenenze linguistiche nel database di VerbaAlpina si realizza in termini comunali. Essa è stata finora effettuata in modo più o meno intuitivo; a breve, però, la distinzione si orienterà verso l'appartenenza linguistica degli informanti, le cui attestazioni provengono da un comune: non appena gli informanti da famiglie linguistiche diverse verranno assegnati ad uno specifico comune, esso riceverà lo status di ''multilingue''. Ecco quindi una soluzione trasparente e duratura per la determinazione del monolinguismo o del multilinguismo. Attraverso la cronoreferenziazione dei dati operata da VerbaAlpina, è inoltre possibile – almeno teoricamente – documentare e visualizzare i cambiamenti riguardanti i confini linguistici. È tuttavia chiaro che il valore informativo ottenuto tramite l'analisi dei dati dipenderà dalla densità e dall'omogeneità dei dati raccolti.
Vorremmo qui cogliere l'occasione per accennare ai nuovi sviluppi nel progetto di VerbaAlpina.
Oltre alle categorie già disponibili nel Menu della carta interattiva online, è, infatti, da poco tempo possibile visualizzare anche i dati provenienti da SQL-queries individuali:
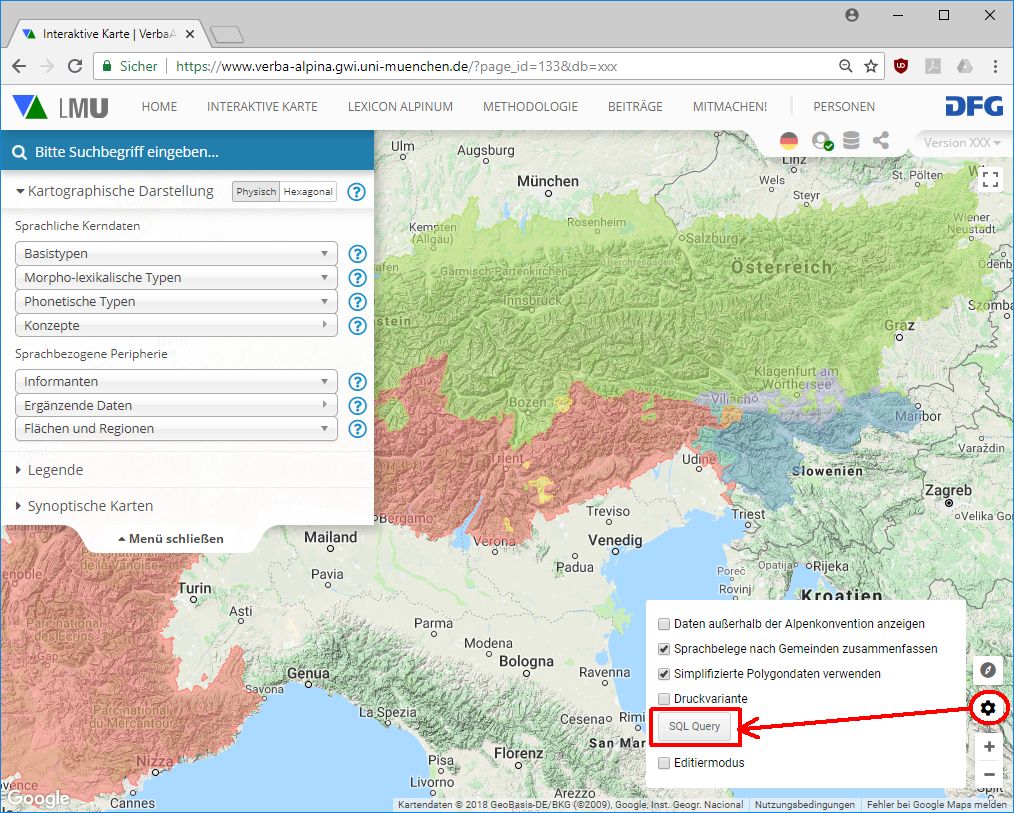
Procedura di inserimento informazioni da SQL Query
Vediamo ad esempio la mappatura dei tipi morfo-lessicali ricollegabili ai tipi di base diffusi sia in territorio linguistico germanico che in quello slavo. Dopo il click su "SQL-Query" si incolla il filtro desiderato, usando la sintassi SQL, nel modulo:
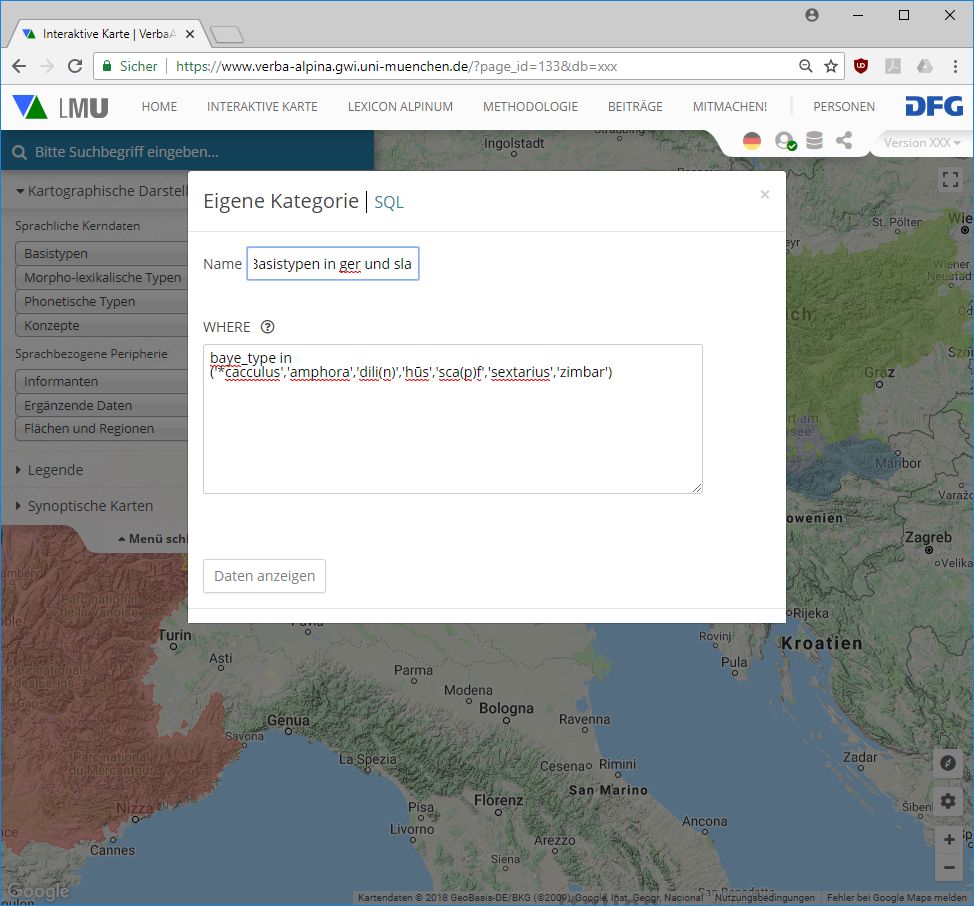
Dopo il click su "Daten anzeigen" (visualizzare dati) viene creata la cartina con i simboli:
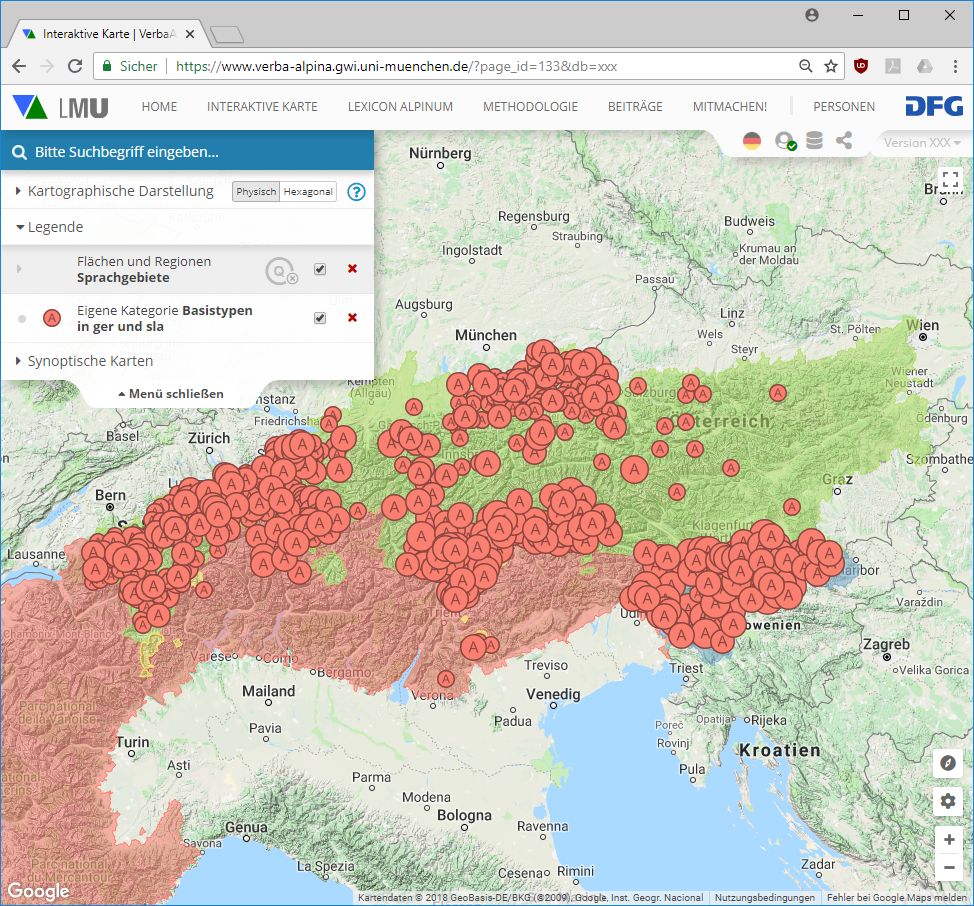
Rappresentazione qualitativa della distribuzione dei tipi morfo-lessicali, alla base dei quali sono presenti dei tipi di base diffusi sia in ambito linguistico germanico che slavo. (Link della mappa: https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=xxx&tk=1533)
La sovrapposizione sinottica delle aree delle famiglie linguistiche e della diffusione dei tipi di base dà origine a innumerevoli pattern, i quali però non sono necessariamente tassativi. È dunque sensato creare nuove mappe, modificando i vari parametri, alla ricerca di modelli significativi. Tuttavia, alcuni tentativi di mappatura si scontrano con i confini naturali. È questo il caso del tentativo di mappatura della diffusione dei tipi morfo-lessicali presenti sia in area linguistica romanza che germanica, in cui il sistema è messo duramente alla prova. Una corrispondente mappatura su base comunale (per la quale sono presenti le attestazioni) comprenderebbe 1400 simboli in totale. I vantaggi di una simile mappatura con un così elevato numero di simboli, risulterebbero comunque molto limitati. Una rappresentazione a livello quantificativo (opzione possibile sulla carta interattiva di VerbaAlpina), potrebbe invece offrire una buona visione di insieme. La seguente mappa offre una visione quantificativa della carta qualificativa basata su unità amministrative di media dimensione (le cosiddette regioni rientranti nel NUTS-3) presente sopra. La colorazione delle singole regioni si basa sul numero dei punti d'attestazione al loro interno:
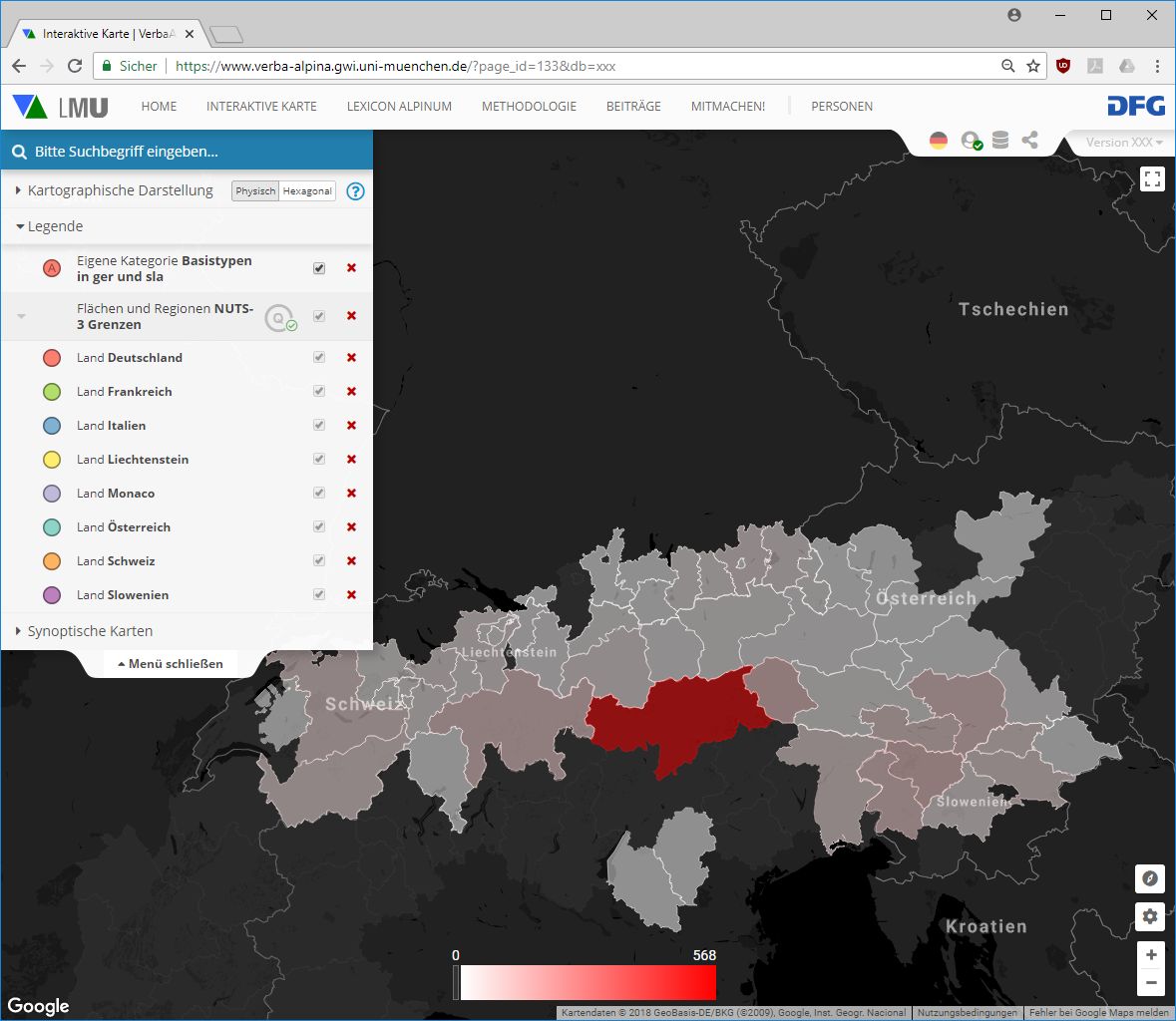
Rappresentazione quantitativa della distribuzione dei tipi morfo-lessicali, alla base dei quali sono presenti dei tipi di base diffusi sia in ambito linguistico germanico che slavo. (Link della mappa: https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=xxx&tk=1531)
Accanto alla rappresentazione cartografica dei risultati dell'analisi, il database offre anche la possibilità di analizzare i dati a livello aritmetico-statistico. Ci si domanda allora, ad esempio, se precisi domini concettuali siano soprattutto spesso collegati ai tipi morfo-lessicali diffusi oltre i confini delle famiglie linguistiche.
Analisi statistiche di questo tipo sono già possibili con la base dati nel database di VerbaAlpina: se al momento è necessaria la conoscenza del linguaggio di SQL Query, in futuro saranno disponibili strumenti statistici specifici, come ad esempio il rinomato e largamente diffuso programma statistico ''R''.
VerbaAlpina collabora, inoltre, con gli sviluppatori della piattaforma MAX, attualmente in fase di sviluppo in cooperazione con il dipartimento di Storia dell'arte e di quello di Statistica dell'Università di Monaco di Baviera (LMU).
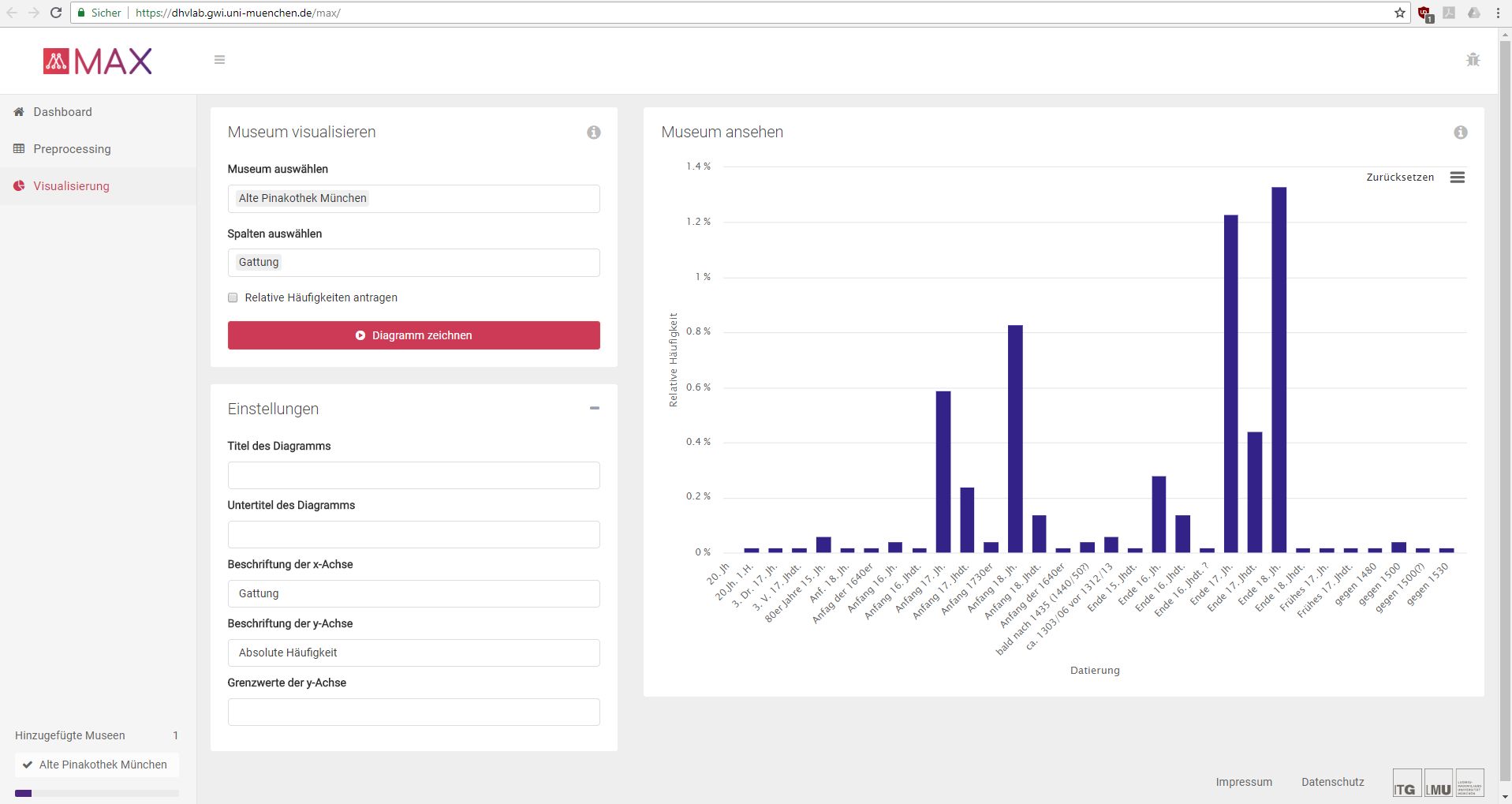
Screenshot dallo strumento di analisi statistica MAX (https://dhvlab.gwi.uni-muenchen.de/max/)
MAX è principalmente uno strumento di analisi statistica riguardante le collezioni museali. Il sistema è, tuttavia, strutturato in modo tale che tutte le raccolte di dati a modello relazionale possano essere esaminate tramite metodi statistici. VerbaAlpina creerà presto un'area limitata ai partner di cooperazione del progetto: qui sarà possibile analizzare statisticamente e visualizzare cartograficamente sia i dati raccolti da VerbaAlpina che i dati personali (oltre ad una combinazione di entrambi). VerbaAlpina denomina quest'area limitata come ''Laboratorio di ricerca''. Una caratteristica essenziale di questo laboratorio di ricerca sarà la possibilità di condividere dati, visualizzazioni e analisi, proprio come ci si aspetterebbe da numerosi servizi presenti su Internet, come Google e Facebook. Le funzionalità di analisi dei dati statistici sviluppate nell'ambito del progetto MAX saranno presto integrate nel laboratorio di ricerca di VerbaAlpina.
Grazie per la Vostra cortese attenzione.
Appendice: Elenco degli SQL-Statements
-- Combinazione di tipo di base e tipo morfo-lessicale
select * from basistypen a
join vtbl_morph_basistyp b using(id_basistyp)
join morph_typen c using (id_morph_typ)
;
-- Tipi morfo-lessicali associati a più di un tipo di base
select
group_concat(distinct c.Orth) as Morphtyp,
group_concat(a.Orth) as Basistypen
from basistypen a
join vtbl_morph_basistyp b using(id_basistyp)
join morph_typen c using (id_morph_typ)
group by id_morph_typ
having count(*) > 1
;
-- Tipo di base butyru(m) e tipo morfo-lessicale beurre / burro select a.ID_Basistyp, concat(a.Orth, ' (', a.Sprache, ')') as Basistyp, c.ID_morph_Typ as ID_Morphtyp, c.Orth from basistypen a join vtbl_morph_basistyp b using(id_basistyp) join morph_typen c using (id_morph_typ) where c.Orth like '%burro%' limit 1 ;
-- Esempio di rappresentazione combinata di Tipi di base e -- tipi morfo-lessicali unitamente alla rispettiva assegnazione linguistica select -- a.ID_Basistyp, a.Orth as Basistyp, a.Sprache as Sprache_Basistyp, -- c.ID_morph_Typ as ID_Morphtyp, c.Orth as Morphtyp, c.Sprache as Sprache_Morphtyp from basistypen a join vtbl_morph_basistyp b using(id_basistyp) join morph_typen c using (id_morph_typ) where a.Orth in ('caldaria','klětь','prīmus','*þūmōn','campus') group by a.Orth -- order by rand() -- limit 5 ;
-- Quantità di Tipi di base presenti in più famiglie linguistiche select morphtyp_sprachen, count(*) as Anzahl from (select a.Orth as Basistyp, a.Sprache as Basistyp_Sprache, group_concat(distinct c.Orth, ' (', c.Sprache, ')' order by c.Sprache, c.Orth separator ' | ') as Morphtypen, group_concat(distinct c.Sprache order by c.Sprache) as Morphtyp_Sprachen from basistypen a join vtbl_morph_basistyp b using(id_basistyp) join morph_typen c using(id_morph_typ) group by a.Orth, a.Sprache having group_concat(distinct c.Sprache) like '%,%' -- order by -- char_length(group_concat(distinct c.Sprache)) desc, -- group_concat(distinct c.Sprache) ) sq group by morphtyp_sprachen ;
-- Tipi di base preromani e latini passati al germanico o allo slavo select a.Orth as Basistyp, a.Sprache as Sprache_Basistyp, group_concat(distinct c.Sprache) as Sprache_Morphtyp, c.Orth as Morphtyp from basistypen a join vtbl_morph_basistyp b using(Id_Basistyp) join morph_typen c using(ID_morph_Typ) where a.Sprache like 'lat' or a.Sprache like 'vor' group by a.Orth having group_concat(distinct c.Sprache) not like '%rom%' and group_concat(distinct c.Sprache) not like '%,%' ;
-- Tipi morfo-lessicali connessi col tipo di base "baita"
select
a.Basistyp,
a.Typ,
a.Sprache_Typ,
a.Wortart,
a.Affix,
a.Genus
from vap_ling_de a
where
a.Basistyp like 'baita' collate utf8mb4_general_ci
and a.Art_Typ like 'morph_typ' collate utf8mb4_general_ci
and a.Typ not like '% %' collate utf8mb4_general_ci
group by
a.Typ,
a.Sprache_Typ,
a.Wortart,
a.Affix,
a.Genus
;
-- Tutti i tipi di base associati ai tipi morfo-lessicali in più
-- famiglie linguistiche
select
a.Basistyp,
group_concat(distinct a.Sprache_Typ) as Sprachfamilien,
group_concat(distinct concat_ws(',',a.Typ, a.Sprache_Typ, a.Wortart, a.Affix, a.Genus) separator ' | ') as Morphtypen
from vap_ling_de a
where
a.Art_Typ like 'morph_typ'
and a.Basistyp is not null
group by a.Basistyp
having sprachfamilien like '%,%'
;
-- tipi di base associati ai tipi morfo-lessicali in più famiglie linguistiche -- raggruppati per famiglie linguistiche select count(*) as Anzahl, sprachfamilien, group_concat(base_type order by base_type separator ', ') as basistypen from (select a.base_type, group_concat(distinct a.type_lang order by a.type_lang) as Sprachfamilien -- group_concat(distinct concat_ws(',',a.Typ, a.Sprache_Typ, a.Wortart, a.Affix, a.Genus) separator ' | ') as Morphtypen from z_ling a where a.Type_kind like 'L' and a.Base_type is not null group by a.id_base_type having sprachfamilien like '%,%') sq group by sprachfamilien order by Anzahl ;
-- Tipi di base presenti in più di una famiglia linguistica, -- raggruppati per dominio concettuale select kategorie, count(*) as Anzahl, group_concat(base_type separator ', ') as Basistypen from (select distinct c.kategorie, a.Base_Type from z_ling a join konzepte b on a.Id_Concept = b.Id_Konzept join konzepte_kategorien c on b.Id_Kategorie = c.id_kategorie where a.Base_type in (select distinct a.base_type from z_ling a where a.Type_Kind like 'L' and a.Base_type is not null group by a.Base_type having group_concat(distinct a.Type_Lang) like '%,%') ) sq group by sq.Kategorie ;
-- Tabella "Pivot", fornendo un quadro riassuntivo delle quantità dei tipi di base -- che sono connessi con tipi morfologici presenti in più di una famiglia linguistica -- raggruppati per atlanti linguistici select aa.quelle, ifnull(bb.Anzahl,0) as `rom/ger/sla`, ifnull(cc.Anzahl,0) as `rom/ger`, ifnull(dd.Anzahl,0) as `ger/sla`, ifnull(ee.Anzahl,0) as `rom/sla` from -- table aa: lista delle fonti (select distinct substring_index(Instance_Source,'#',1) as Quelle from z_ling) aa left join -- table bb: rom,ger,sla (select quelle, sprachen, count(*) as Anzahl from (select *, count(*) from (select id_base_type, group_concat(distinct a.Type_Lang order by a.Type_Lang) as Sprachen, a.Base_Type from z_ling a join basistypen b on a.Id_Base_Type = b.ID_Basistyp where a.Type_Kind = 'L' group by a.id_base_type having group_concat(distinct a.Type_Lang order by a.Type_Lang) like '%,%' ) a join (select id_base_type, substring_index(b.Instance_Source,'#',1) as Quelle from z_ling b ) b using(id_base_type) group by b.quelle, id_base_type ) c where sprachen like 'rom,ger,sla' group by quelle, sprachen order by length(sprachen) desc ) bb on aa.quelle = bb.quelle left join -- table cc: rom,ger (select quelle, sprachen, count(*) as Anzahl from (select *, count(*) from (select id_base_type, group_concat(distinct a.Type_Lang order by a.Type_Lang) as Sprachen, a.Base_Type from z_ling a join basistypen b on a.Id_Base_Type = b.ID_Basistyp where a.Type_Kind = 'L' group by a.id_base_type having group_concat(distinct a.Type_Lang order by a.Type_Lang) like '%,%' ) a join (select id_base_type, substring_index(b.Instance_Source,'#',1) as Quelle from z_ling b ) b using(id_base_type) group by b.quelle, id_base_type ) c where sprachen like 'rom,ger' group by quelle, sprachen order by length(sprachen) desc ) cc on aa.quelle = cc.quelle left join -- table dd: ger,sla (select quelle, sprachen, count(*) as Anzahl from (select *, count(*) from (select id_base_type, group_concat(distinct a.Type_Lang order by a.Type_Lang) as Sprachen, a.Base_Type from z_ling a join basistypen b on a.Id_Base_Type = b.ID_Basistyp where a.Type_Kind = 'L' group by a.id_base_type having group_concat(distinct a.Type_Lang order by a.Type_Lang) like '%,%' ) a join (select id_base_type, substring_index(b.Instance_Source,'#',1) as Quelle from z_ling b ) b using(id_base_type) group by b.quelle, id_base_type ) c where sprachen like 'ger,sla' group by quelle, sprachen order by length(sprachen) desc ) dd on aa.quelle = dd.quelle left join -- table ee: rom,sla (select quelle, sprachen, count(*) as Anzahl from (select *, count(*) from (select id_base_type, group_concat(distinct a.Type_Lang order by a.Type_Lang) as Sprachen, a.Base_Type from z_ling a join basistypen b on a.Id_Base_Type = b.ID_Basistyp where a.Type_Kind = 'L' group by a.id_base_type having group_concat(distinct a.Type_Lang order by a.Type_Lang) like '%,%' ) a join (select id_base_type, substring_index(b.Instance_Source,'#',1) as Quelle from z_ling b ) b using(id_base_type) group by b.quelle, id_base_type ) c where sprachen like 'rom,sla' group by quelle, sprachen order by length(sprachen) desc ) ee on aa.quelle = ee.quelle order by quelle ;
Il testo è stato modificato dopo la traduzione. Degli sbagli eventuali sono responsabile io stesso. ↩