

Gerdi-Fragebogen zu VerbAlpina (Februar 2018)
- Abläufe:
Daten-/Serverinfrastruktur: Die Daten von VerbaAlpina werden modularisiert und versioniert verwaltet. Die sprachlichen Kerndaten liegen auf einem geclusterten MySQL-Server (= Modul VA_DB). Darauf aufsetzend arbeitet eine mit WordPress realisierte GeRDI-VA-DataSources-270618-1638-16Webschnittstelle (VA_WEB), die u.a. eine Seite zur interaktiven kartographischen Visualisierung der in VA_DB gehaltenen Daten erlaubt.
Datenmanagementpläne: ja, aber nicht in standardisierter Form (vgl. https://www.forschungsdaten.info/themen/planen-und-strukturieren/datenmanagementplan/; entsprechende Dokumentationen sind in der Rubrik Methodologie abgelegt.
Freigabe: Der Zugriff auf die Datenbankschnittstellen VAP ist ausschließlich Kooperationspartnern von VerbaAlpina erlaubt und unterliegt einer CC BY-SA- bzw. der ODC-ODbL-Lizenz
- Daten:
Größe: 1,5 GB (Modul VA_DB; Stand Feb. 2018), 30 GB in 33315 Dateien (Modul VA_WEB; Stand Feb. 2018)
Formate: relationales Datenformat;
Typen: ??
Ursprung: Teils strukturierte Erfassung retrodigitalisierter Sprachatlanten und Wörterbücher, teils Crowd, teils Projektpartner
Software: ??
Schnittstellen: VAP_ling_[language] (Sprachdaten), VAP_geo_[language] (ergänzende georeferenzierte Daten wie z.B. Fundorte von lateinischen Inschriften) (in jeweils 5 Sprachen)
Datenschutz: [Persönlichkeitsrechte? Urheberrechte?]
Speicher: Storage mit Plattenarrays; regelmäßige Backups über TSM ins LRZ
- Metadaten:
Arten: s. Attribute der VAP-Schnittstellen
Speicherung: gemeinsam mit Primärdaten in VAP-Schnittstellen
Standards: proprietär; Standards werden durch individuell erzeugte Schnittstellen bedient (wie jetzt z.B. GeRDI: Datacite -> OAI-PMH -> Harvester)
Datenschutz: s.oben
Schnittstellen: ??
- Datenauswertung:
Programme: – (ggf. zukünftig R oder SQL)
Aufbereitung: ??
Visualisierung: Online-Karte (Javascript, Google API)
VA@GeRDI (27. Juni 2018)
Tagesordnung
TOP 1: Roadmap (TW/HN)
TOP 2: Usecases Datenkorrelation (TW/HN)
TOP 3: Bericht über Kontakte zu UBs (LMU, Erlangen) (SL)
TOP 4: Kooperation GeRDI – UZH (TK)
TOP 1: Roadmap (TW/HN)
GeRDI arbeitet in Releases, die ungefähr alle drei Monate
herausgegeben werden sollen. Das wäre eine mögliche Roadmap (bis zum
Ende von GeRDI Phase 1, in Phase 2 können ggf. neue Milestones
vereinbart werden):
Release 0.3 (Herbst 2018):
"Minimal viable product" -> Verba Alpina Daten sind im GeRDI-Index
(ohne die Knowledge Base und mit Bounding Boxes)
Mögliche Data Provider für die Datenkorrelation wurden
identifiziert (GeRDI-VA-DataSources)
- Bis zu Release 0.3 soll ein praxistaugliches Metadatenmodell implementiert werden ("minimal viable product"). Die Entwicklung soll in enger Abstimmung mit der UB erfolgen.
- Mit welchen Daten die VA-Daten kombiniert werden sollen, soll bis Herbst 2018 ausdiskutiert sein.
- Metadatenproviding für GeRDI-Index kann später auch über die UB laufen; bezüglich der sustainability wäre es ein Gewinn, wenn sich die UB als Zwischeninstanz einschalten würde (denkbar wäre: VA liefert an --> UB e-humanities --> UB e-humanities bereitet die Daten auf --> liefert sie dann an GeRDI).
UB e-humanities Projekt
- Das e-humanities Projekt führt vertiefte Inhaltsanalysen durch und verknüpft die Daten mit Normdaten. Geplant ist, die Daten dann an GeRDI zu liefern.
- Frau Kümmet wertet derzeit die Entitäten der ITG-Projekte aus. Diese sollen mit Wikidata verknüpft werden. Es ist jedoch noch nicht klar, ob sich alle Entitäten mit Wikidata abbilden lassen.
Release 0.4 (Winter 2018/19)
Geo-Granularität verbessert (Merging der Polygone für einen besseren
Informationsgehalt).
Anbindung der Data Provider für die Datenkorrelation in den GeRDI-Index.
Release 0.5 (Frühling 2019)
Erste Tests des Daten-Stagings (automatischer Bezug der VA-Daten mit
den Daten anderer Data-Provider) "so automatisch wie möglich"
Automatischer Bezug der Daten
- Bis Release 0.5 sollen alle Daten von VA und Daten aus anderen Quellen auf die Plattform von GeRDI gebracht werden. Man hat eine erste Idee, wie automatisierbar dieser Prozess ist.
Release 0.6 (Sommer 2019)
Anbindung Knowledge Base an VerbaAlpina-Metadaten
Analyse der gestagten Daten auf LRZ-Rechnern
- Es soll geprüft werden, welche Aufbereitung der Daten möglich ist.
- Die Daten sollen mit einer logischen Einheit referieren.
- Es soll festgelegt werden, wie genau die Datenanalyse ablaufen soll (welche Analyseschritte etc.).
Release 0.7 (Herbst 2019)
Puffer für Unvorhergesehenes
- Im Herbst 2019 endet GeRDI Phase I.
- Bis dahin soll ein Anwendungsfall von VA über die GeRDI-Plattform zum Laufen gebracht worden sein.
- Bei Verlängerung von GeRDi soll mit den Communities aus Phase I auch in Phase II weiter zusammengearbeitet werden. Bei fehlender Anschlussfinanzierung von GeRDI ist vorstellbar, dass das LRZ und die UB als Ansprechpartner dienen und dass das e-humanities Projekt der UB die von GeRDI entwickelten Funktionalitäten übernimmt.
Methodik GeRDI
- GeRDI nutzt existierende Metadaten-Harvesting-Modelle
- gearbeitet wird mit DataCite als Standard und OAI-PMH-Protokoll (pleonastisch); damit soll bis Release 0.3 die erste laufbare Version produziert werden
- wenn DataCite technisch nicht funktioniert, wird darauf entsprechend reagiert
- laut TW bietet DataCite alles, um die Daten zugreifbar und interseparabel zu machen
- im Endeffekt soll anhand von Usecases festgestellt werden, welche Anforderungen ein Metadatenstandard erfüllen muss und ob DataCite dafür ausreicht
- bei Version 0.2/0.3 soll deshalb geschaut werden, ob die Funktionalitäten von DataCite ausreichen; wenn nicht, wird man sich nach entsprechenden Alternativen umschauen (Standard selbst kreieren oder einen bestehenden Standard entsprechend anpassen) und kann, wenn nötig, dann immer noch nachsteuern
- geplant ist das Mapping von DataCite zu Dublin Core (= Mindeststandard, es gibt aber bessere Metadatenstandards)
Allgemeines
- ab 18/1 sollen Metadatenannotationen auf SQL-Abfragen losgeschickt werden, Datenbasis: Schnittstelle vap_ling_xx
- Die Daten sind dann redundant verfügbar und automatisch beziehbar
- Usecases sind möglich, wie z.B. die Ausgabe bestimmter Diffusionsmuster für bestimmte Gemeinden
- die entscheidenden Kategorien sind: Gemeinden, Konzepte, Morph-Typen, Zeit; jeder einzelne Morph-Typ ist ansprechbar; wenn eine Wissensdatenbank dazukommt, können andere, z.B. große Online-Wörterbücher, auch daran anknüpfen
- auch der umgekehrte Fall ist denkbar, d.h. Metadaten aus GeRDI fließen in VA und nicht umgekeht; Daten aus 3 Bereichen stehen zur Verfügung: Statistik-Behörden, Transportdaten und Geophysikdaten
TOP 2: Usecases Datenkorrelation (TW/HN)
- Nachnamen => Korreliert die Parzellierung der Typen mit der geographischen Distribution von Nachnamen?
- Demographie-Daten => Welche Zusammenhänge gibt es zu Nivellierungen?
- geophysikalische Daten => Stichworte: "Baumgrenze", Flora und Fauna-Daten; hier fehlt eine genaue Fragestellung.
- Daten, die Verhältnis von Einheimischen zu nicht-Einheimischen beschreiben (Übernachtungszahlen, Verkehrswege, Transportsysteme) => Korelliert dies mit Nivellierungen?
TOP 3: Bericht über Kontakte zu UBs (LMU, Erlangen) (SL), TOP 4: Kooperation GeRDI – UZH (TK)
- da geisteswissenschaftliche Projekte derzeit allgemein aufgefordert werden, Metadaten anzulegen, ist ein einheitliches Metadatenmodell anzustreben, damit die Daten kompatibel sind
- TK wäre deshalb dafür, Kontakt zu anderen aufzunehmen (UZH/UBs)
- TW plädiert dafür, zunächst einen konkreten technischen Vorschlag zu machen und diesen in eine Version zu bringen, die präsentabel ist, bevor man mit anderen in Kontakt tritt
VA@GeRDI (09. Juli 2018) – Treffen zum Thema "Data Provider"
Teilnehmer: Krefeld, Lücke, Nguyen, Weber
Ort: ITG
Zeit: 12:30-13:30
VA ist interessiert an Daten aus folgenden Kategorien:
- Demographie
- Infrastruktur (Internet-Erschließung und -Nutzung, Verkehrswege [Straßen, Eisenbahn, Flughäfen], Tourismus)
- geophysikalische Daten (Klima, Wetter, Bodengüte)
- Wirtschaft (Verbreitung bestimmter Wirtschaftsformen, z.B. Almwirtschaft, Holzwirtschaft etc.)
Alle Daten sollten mit Chronoreferenzierung versehen sein und möglichst mehrere Zeitschnitte enthalten (Diachronie).
Als Data Provider wird zunächst Eurostat (http://ec.europa.eu/eurostat/data/databaseausgewertet. Erst wenn gewünschte Daten von dort nicht zu beziehen sind, wird auf nationale Datenquellen zurückgegriffen.
Im ersten Anlauf werden zunächst nur Daten zur Demographie erfasst.
Anregung1: MA-Arbeit zur algorithmischen Strukturierung der Daten des Idiotikons (https://digital.idiotikon.ch/idtkn/id12.htm#!page/120031/mode/1up) am LRZ?
Anregung2: Integration der von FZ im Rahmen seiner Diss erzeugten Daten aus dem REW (http://www.nbn-resolving.de/urn:nbn:de:bvb:355-ubr07799-0) in GeRDI?
Das nächste VA@GeRDI-Treffen findet statt, sobald entweder das Ziel von release 0.3 ("Minimal viable product" -> VA-Daten im GeRDI-Index) erreicht ist oder demographische Daten im Gerdi-Index aufgenommen sind. Herr Nguyen und Herr Weber melden sich bei VA.
Teilnehmer: Kümmet, Lücke, Mutter, Nguyen, Weber, Zacherl
Ort: Medienlabor, Raum 3010, Schellingstraße 33
Zeit: 14:00-16:00 Uhr
Tagesordnung
TOP 1: Aktueller Stand: Metadaten, Harvester
TOP 2: Statusbericht GeRDI 0.2 und 0.3
TOP 3: Nächste Planungen GeRDI 0.4
TOP 4: Vorbereitungen Community Workshop
TOP 5: VA-Datenexport
TOP 1: Aktueller Stand: Metadaten, Harvester
GeRDI-Dienste
- die Dienste "Harvest", "Search" und "Bookmark" sind in GeRDI zentral, der Harvest-Dienst ist für die Nutzer nicht sichtbar
- GeRDI bezieht sich hinsichtlich des Forschungsdaten-Lebenszyklus auf das Modell UK data life cycle (Quelle: UK Data Service https://www.ukdataservice.ac.uk/manage-data/lifecycle), beinhaltet die folgenden Schritte: creating data --> processing data --> analysing data --> preserving data --> giving access to data --> re-using data
- VA würde gerne auf das Modell, das GeRDI zugrunde legt, referieren können; zu diesem Zweck soll das Modell irgendwo zentral abgelegt werden
Workflows
- bislang gibt es in GeRDI zwei Suchmöglichkeiten: einfache Suche + erweiterte Suche
- weitere Funktionen: Suchbereich einschränken; Daten speichern, bearbeiten, visualisieren; bookmark (speichert Daten als Lesezeichen zur späteren Ansicht)
- beide Suchmöglichkeiten sollen von Beginn an angeboten werden
- Auswahl an Filtermöglichkeiten soll sich an den Elementen von DataCite orientieren
- Datensätze von VA sollen georeferenziert dargestellt werden, Möglichkeit zu georeferenzierter Suche ist aber wichtiger als georeferenzierte Visualisierung, die bereits durch VA selbst geleistet wird
- an sprachunabhängiger Suche wird gearbeitet (Suche nach "Butter" findet "Butter", "burro", "beurre" ...)
- Material muss downloadbar und veränderbar sein
- für VA wäre wichtig: Auffindbarkeit, feine Granulierung und luzide Beschreibung des Materials (ähnlich https://data.ub.uni-muenchen.de/110/)
- Auswahl des Materials soll sich an Metadaten orientieren, die in DataCite vorliegen; zunächst sollen Daten ausgewählt werden, die sich bezüglich Georeferenz decken; danach soll der Nutzer die Möglichkeit erhalten, die Daten in gesonderter Umgebung (mit Python/R etc.) zu entpacken/explorieren/statistisch auszuwerten. – Ähnliches leistet bereits https://www.max.gwi.uni-muenchen.de/
- Format der Daten: CSV, evtl. auch XML
- Partnerprojekte von GeRDI müssen bestimmte Metadaten mitteilen: Georeferenzierung, Chronoreferenzierung, Zuordnung zu groben Bereichen
- Mögliche Gestaltung der Suchanfragen: Zeiteinschränkung, Ortseinschränkung, Schlagwort
Metadatenschema
- Bislang nur das Standard-Set des DataCite-Schemas implementiert
- Metadatenschemata von verschiedenen Disziplinen werden zunächst angeschaut und dann auf entsprechende Töpfe verteilt: DataCite, Extension, Disziplin-spezifisch etc.
- die gelieferten Metadaten sollen einem gewissen Standard entsprechen
- Grundlage soll das Formular zur Vergabe von DataCite sein; erst wenn bestimmte Felder ausgefüllt sind, sind Metdaten akzeptabel
TOP 2: Statusbericht GeRDI 0.2 und 0.3
GeRDI 0.2:
- weitere Repositorien wurden eingebunden
- weitere Filterfunktionen wurden implementiert
GeRDI 0.3:
- v.a. Verbindung von Oberfläche mit Backend steht im Mittelpunkt
TOP 3: Nächste Planungen GeRDI 0.4
- kontrolliertes Vokabular für Verwendung in Metadatenschemata wie DataCite
- Suche und Filterung anhand disziplin-spezifischer Metadaten
- weitere Repositorien einbinden
- Download der Suchergebnisse auf lokale Festplatte
- Aufbau eines Jupyter-Hubs (-> für nachgelagerte Analyse von Projektdaten ähnlich https://www.max.gwi.uni-muenchen.de/)
TOP 4: Vorbereitungen Community Workshop
Für den Community Workshop sind soweit alle Vorbereitungen bereits getroffen.
TOP 5: VA-Datenexport
- Daten sollen feingranuliert in 4erlei Gestalt an die UB ausgegeben werden: morpholexikalische Typen, Konzepte, Ortschaften, Einzelbelege
- für jeden einzelnen Datensatz wird eine einzelne Datei erzeugt, die jeweils mit einem Buchstaben (A= Ortschaften, C=Konzepte, L=morpholexikalische Typen) und einer Identifikationsnummer versehen wird
- für jeden einzelnen Datensatz wird ein DataCite-Metadatensatz erzeugt; auf diesem Wege landen die Metadaten (nach einem Mapping ins MARC-Format) auch im Bibliothekskatalog (OPAC)
- VA spricht sich für die Etablierung von Normdaten (GND) für morpholexikalische Typen aus; Teil der GND ist die ID, die auf genau einen Datensatz verweist; analog soll dies auch für Konzepte erfolgen
- eine DOI erhalten: morpholexikalische Typen, Konzepte, Ortschaften, Einzelbelege und der gesamte Datensatz (VA_DUMP)
- die genaue Granularität der Daten muss noch diskutiert werden; evtl. gibt es zum Thema "Data granularity" eine Empfehlung von Interessensgruppen der RDA (Research Data Alliance https://www.rd-alliance.org/); Herr Weber schlägt vor, dort mal nachzufragen
- spätestens ab November soll GeRDI die OAI-PMH-Schnittstelle von Open Data LMU ansprechen können
Second community workshop GeRDI (16. Mai 2019, Berlin)
Ort: DFN-Verein e.V., Alexanderplatz 1, 10178 Berlin
Zeit: 10:00 – 16:00 Uhr
Allgemeines
- Start von GeRDI II ist für Ende dieses Jahr/Anfang nächstes Jahr geplant
- Verlängerungsantrag wurde bereits eingereicht
- bisher implementierte Funktionen von GeRDI: Search, Bookmark, Store (Jupyter Hub storage) --> aktuell wird an den Funktionen "Process" und "Analyze" gearbeitet (entsprechend dem research data life cycle model)
- Ziel ist es, insgesamt 15 Repositorien einzubinden (derzeit sind es 12)
- die angestrebte Menge an Metadaten, die integriert werden sollen, wurde bereits überschritten (geplant waren 700.000, derzeit sind es bereits 875.000 metadata records)
- Ziele für die nächste Projektphase: stakeholders + community building, services based on federation, disciplinary metadata, Europe-wide visibility of research data from Germany (FAIR), consideration of the NFDI (= Nationale Forschungsdateninfrastruktur)
Sessions
(Session A) fand parallel zu Session B) und Session C) parallel zu Session D) statt, CM besuchte Session B) und D) )
A) Data workflows & data pipelines
Using the research data life cycle as a model, we will demonstrate how researchers can use GeRDI services to support their individual data handling strategies.
We would like to understand if this workflows and APIs can be formulated in a generic way covering a wider range of research disciplines or – alternatively – if "data pipelines" should model discipline-specific data handling strategies. By thinking together with you about specific use cases we will create design sketches for possible new GeRDI functions.
B) Extending GeRDI Metadata Schema with disciplinary metadata elements
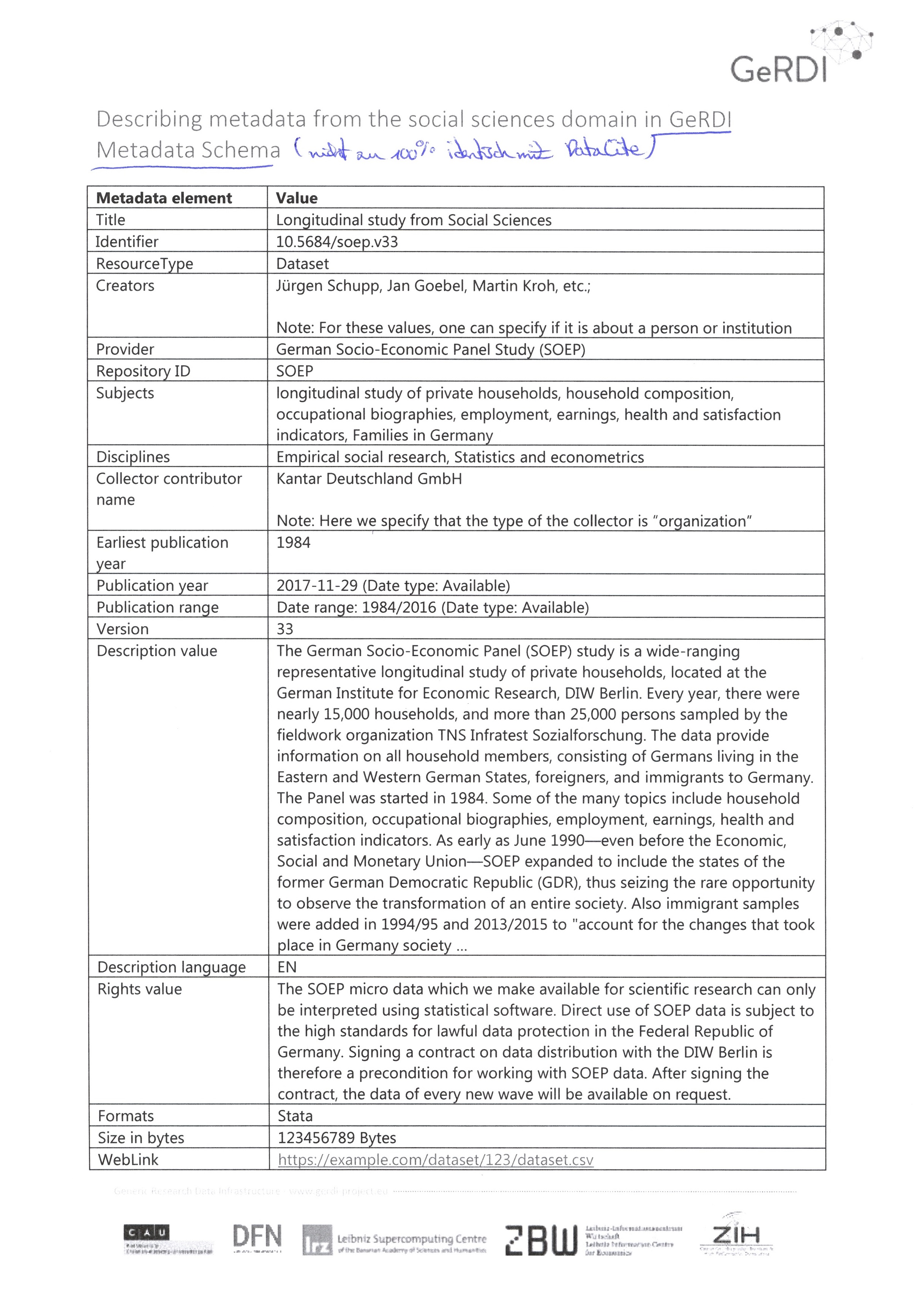
This session will address disciplinary metadata elements. Participants will discover the current state of the GeRDI Metadata Schema and how it is used in different GeRDI services. In an exemplary mapping demonstration the participants will be exposed to the process of extending the metadata schema. In a discussion we will try to identify high-priority metadata elements from participating communities. Other discussion topics include the usage of controlled vocabularies and the re-use of metadata elements across communities.
C) How to design: Submit service
During this session we will work together on design the new GeRDI service. We will go through discussing the existing use case, extend and value them. Then will bring our idea to paper discuss them and find the possible solutions for the future implementation. We eager to find out, how such service could be supported through GeRDI, which use cases, are most important and what challenges there are. To get the result we will dive into the different techniques of design thinking method.
D) Improving data quality in research data infrastructures
This session will address the term data quality and its relevance in research. Participants will explore criteria describing and measuring data quality that datasets can be effectively compared and ranked. Learn common criteria and how the scientific domains differ in their quality requirements for data. In a discussion, we will analyze the incentives to motivate data creators as well as the interventions needed to increase the quality of datasets. In the end, the elaborated measures will be assessed and recommendations for research data infrastructures will be made.
Zu Session B): high-priority metadata


- aufgeteilt auf die verschiedenen Disziplinen (Humanities, Life sciences, Natural Sciences) sollte jede Community bezogen auf ihre einzelnen use cases die jeweiligen high-priority Metadaten nennen (für VA: concepts, morpho-lexical types, single attestations, municipalities)
- es wurde geschaut, über welche Metadaten die Daten der einzelnen Communities am besten miteinander verknüpft werden können
- wahrscheinlichster Verknüpfungspunkt der Metadaten der einzelnen Communities ist die Georeferenz der Metadaten, da dieses Metadatum überall vorkommt
Zu Session D): data quality (of metadata)
Frage: Woran kann Datenqualität festgemacht/gemessen werden?
Folgende Punkte wurden erarbeitet:
- availability of metadata
- metadata completeness
- granularity
- trust in the source of data
- definition of data quality depends on research question
- description in natural languages
- responsibility within community
- community building
Fazit:
- fast unmöglich, generisch zu definieren, woran Datenqualität festgemacht werden kann (außer den FAIR-Kriterien)
- am Community workshop kam man zu dem Schluss, dass man das offen lässt und stattdessen der Community die Möglichkeit gibt, fehlende Metadaten nachzutragen
- laut Prof. Klaus Tochtermann sollen zudem die Empfehlungen für Datenqualität des RFII (= Rat für Forschungsdateninfrastruktur, NFDI ist daraus entstanden) befolgt werden