

Come lavoriamo noi …
Usiamo un certo modo di organizzare i dati. Quello si chiama il modello relazionale. Nella terminologia informatica la parola "relazione" significa semplicemente una tabella. Al punto dove stiamo adesso – voglio dire nella fase della transizione dal mondo analogo al mondo digitale – la sfida consiste nella digitalizzazione di dati pubblicati in un modo analogo, vuol dire in libri come dizionari e atlanti per nominare il genere il più importante per il nostro lavoro. Questa digitalizzazione non consiste soltanto nel uso di un computer, ma richiede un cambio della metodologia.
Cominciamo con un esempio preso dal libro di Roberto Sottile che è dedicato al vocabolario del mondo pascolare nelle Madonie. Suppongo che conoscete bene quel libro e mi sembra superfluo spiegare che esso contiene due capitoli con contenuto reciproco, uno di cui organizzando il lessico pastorale dal punto di vista semasiologico e l'altro dal punto di vista onomasiologico.
Ho scelto un esempio dalla parte onomasiologica per mostrare come arrivare dalla rappresentazione analoga nel libro alla struttura relazionale già menzionata che è necessaria per l'analisi dei dati in un modo veramente digitale.
Roberto Sottile ci ha trasmesso un file Word che è stato creato su un computer del tipo Apple/Macintosh. L'esempio è preso da questo file e precisamente dal campo della lavorazione del latte perché è quello che attualmente sta nel centro del lavoro a VerbaAlpina .
Ecco una schermata / un fermo-immagine del concetto "piccola forma di formaggio" preso dalla parte onomasiologica del libro:

Per il lettore umano i significati delle singole parti dello scritto sono proprio chiari: La prima linea contiene un titolo, indicando che di seguito vengono elencati concetti e significati connessi con questo campo. Nella seconda linea si trova la descrizione del concetto e le linee successive presentano le singole parole che indicano quel concetto. La coerenza semantica delle parole portando lo stesso significato viene sottolineata tramite le lettere nerette. Dopo ogni parola seguono le sigle dei nomi degli abitati in cui viene usata la parola rispettiva.
Dal punto di vista del computer tutte le informazioni appena spiegate e contenute in un modo immanente non sono chiare per niente. Per arrivare alla possibilità di analizzare col computer anche quelle informazioni immanenti ci vuole una modificazione della rappresentazione dei dati. Come già detto una tale possibilità può – ed ormai vorrei sottolineare il *può* perché ci sono anche altri modi di procedere – può essere il modello relazionale. Nel modello relazionale si potrebbe organizzare le informazioni come di seguito. E dico "potrebbe" perché nel dettaglio ci sono sempre parecchi varianti, la scelta di cui dipende dallo scopo della ricerca. Il nostro scopo è chiaro: Vogliamo analizzare i dati in una prospettiva geolinguistica. Allora, ecco come si potrebbe procedere:
| Denominazione | concetto | campo di concetti | luoghi |
| pricintinu | piccola forma di formaggio | FORME DI FORMAGGIO | GA |
| pizzuḍḍa | piccola forma di formaggio | FORME DI FORMAGGIO | GE |
| squadatu | piccola forma di formaggio | FORME DI FORMAGGIO | GA,GE,PS,CA,PO |
| tumazzunìeḍḍu | piccola forma di formaggio | FORME DI FORMAGGIO | GE,CA |
Abbiamo creato una tabella con le denominazioni. Ogni riga della tabella contiene una denominazione. Nelle colonne della tabella si trovano gli attributi delle parole. È da sottolineare che il modello relazionale permette l'illimitata addizione di righe e di colonne.
Dal punto di vista informatico la struttura scelta presenta almeno una offesa contro le regole: i campi dell'ultima colonna non contengono valori cosiddetti "atomici" ma in alcuni casi una concatenazione di valori. Lo svantaggio diventa ovvio se si tenta di assortire i valori secondo l'alfabeto. La soluzione la più facile sarebbe di copiare le righe riguardante e di distribuire i singoli valori sui righe nuove. Ecco il risultato:
| Denominazione | concetto | campo di concetti | luoghi |
| pricintinu | piccola forma di formaggio | FORME DI FORMAGGIO | GA |
| pizzuḍḍa | piccola forma di formaggio | FORME DI FORMAGGIO | GE |
| squadatu | piccola forma di formaggio | FORME DI FORMAGGIO | GA |
| squadatu | piccola forma di formaggio | FORME DI FORMAGGIO | GE |
| squadatu | piccola forma di formaggio | FORME DI FORMAGGIO | PS |
| squadatu | piccola forma di formaggio | FORME DI FORMAGGIO | CA |
| squadatu | piccola forma di formaggio | FORME DI FORMAGGIO | PO |
| tumazzunìeḍḍu | piccola forma di formaggio | FORME DI FORMAGGIO | GE |
| tumazzunìeḍḍu | piccola forma di formaggio | FORME DI FORMAGGIO | CA |
Purtroppo la soluzione del primo problema comporta un nuovo problema: Adesso informazione identica è moltiplicata, vuol dire: la tabella contiene sempre la stessa quantità di informazione ma ormai è diventata più larga. In conseguenza, se per qualsiasi motivo sarebbe necessario cambiare qualcosa, per esempio l'ortografia della denominazione "squadatu", occorre ripetere il cambio in tutti i campi col valore "squadatu". Nel caso che si deve gestire una tabella molto più grande di quella attuale la ridondanza di informazione comporta gravi problemi riguardanti la "performance". Allora ci vuole un'altra modificazione della struttura finora ottenuta. Ormai dobbiamo individuare cosiddetti "entità", vuol dire classi di oggetti nel complesso dei dati rappresentati nella tabella, che sono definiti tramite una gamma di attributi specifici. Per ogni entità ci vuole una tabella propria. Il collegamento logico tra gli elementi salvati nelle tabelle viene elencata attraverso numeri identificativi:
Abbiamo già menzionato la possibilità di arricchire le tabelle di righe e colonne addizionali. Per dare un esempio abbiamo aggiunto colonne supplementari alla tabella 3, marcate col colore blu, in cui si trova la liste dei comuni. Omai sono elencati il nome della comune, i dati necessari per la georeferenziazione, dunque i gradi di longitudine e di latitudine, e infine il numero degli abitanti. Tutto quello che abbiamo fatto finora, nella terminologia informatica, si chiama "normalizzazione" di una banca dati.
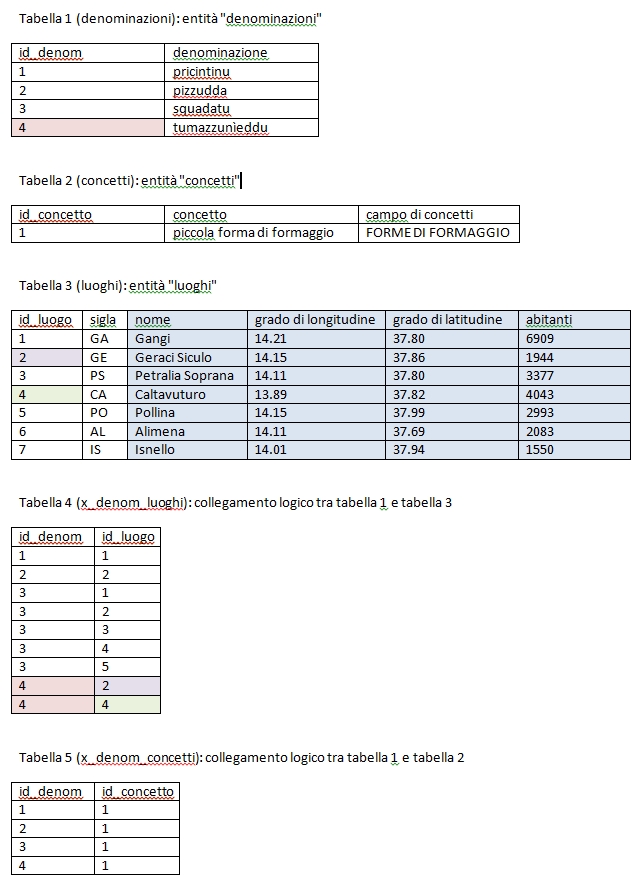
Per calcolare in quali comuni viene usata la denominazione "tumazzunìeḍḍu" per significare il concetto "piccola forma di formaggio" ci vuole combinare i numeri identificativi: La denominazione "tumazzunìeḍḍu" nella tabella 1 porta il numero 4 (marcato in rosso). Nella tabella 4 troviamo due righe con questo numero 4 nel campo chiamato "id_denom". Nelle stesse righe nel campo "id_luogo" accanto si trovano i numeri identificativi dei comuni in cui la denominazione viene usata. Quei numeri infine rimandano alla tabella 2 dove sono elencati i dati riguardanti i comuni. Presento qui i dati combinati in questo modo:

Al più tardi ormai siamo arrivati ad un punto dove la struttura dei dati è diventata così complessa, che abbiamo bisogno del aiuto dalla parte tecnica per gestirla. A ciò esistono sistemi cosiddetti, in inglese, "Database Management Systems", abbreviato DBMS. Il forse più noto di quei sistemi è MySQL.
Ecco come si presentano le tabelle nel sistema MySQL:
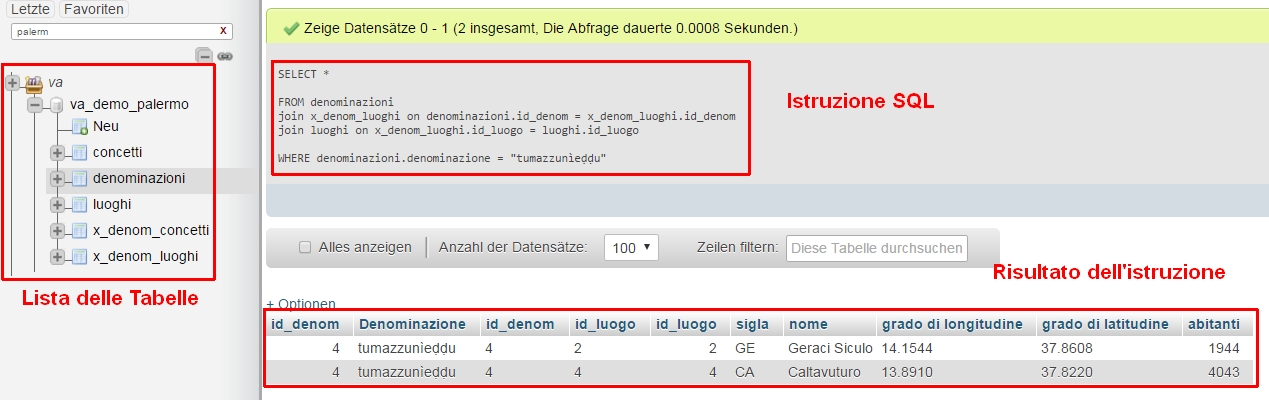
Sulla parte superiore della schermata si vede un esempio della lingua formale/artificiale, chiamata SQL (Structured Query Language) e costruita in particolare per la gestione di dati in struttura relazionale. Sulla parte sinistra della schermata si trova la lista delle tabelle che abbiamo creati. E, finalmente sul fondo della schermata si vede il risultato dell'istruzione SQL.
Abbiamo preparato qualche altro esempio di istruzioni SQL (archivio scaricabile), solo per dare un idea della capacità. Nella lista vengono elencati gli istruzioni SQL e il risultato rispettivo:
/* crea una lista dei luoghi che indica la quantità dei denominazioni
usati per significare il concetto "piccola forma di formaggio" */
SELECT
luoghi.nome,
count(*) as quantità,
group_concat(denominazioni.Denominazione) as `denominazioni`
FROM denominazioni
join x_denom_luoghi on denominazioni.id_denom = x_denom_luoghi.id_denom
join luoghi on x_denom_luoghi.id_luogo = luoghi.id_luogo
group by luoghi.sigla
order by quantità DESC
;
Risultato:

/* trova i luoghi in cui si usano più di una denominazione sola
per significare il concetto "piccola forma di formaggio" */
SELECT
luoghi.nome,
count(*) as quantità,
group_concat(denominazioni.Denominazione) as `denominazioni`
FROM denominazioni
join x_denom_luoghi on denominazioni.id_denom = x_denom_luoghi.id_denom
join luoghi on x_denom_luoghi.id_luogo = luoghi.id_luogo
group by luoghi.sigla
having quantità > 1
;
Risultato:
/* crea una lista di denominazioni simile a quella
che si trova nel libro di Roberto Sottile */
select
concat(
sq.campo,
'\n\n',
sq.concetto,
'\n',
group_concat(denominazioni separator '\n')
) as `testo scorrevole, non strutturato`
from
(
SELECT
concetti.`campo di concetti` as campo,
concetti.concetto,
concat(
denominazioni.Denominazione,
' ',
GROUP_CONCAT(luoghi.sigla)
) as denominazioni
FROM denominazioni
join x_denom_luoghi on denominazioni.id_denom = x_denom_luoghi.id_denom
join luoghi on x_denom_luoghi.id_luogo = luoghi.id_luogo
join x_denom_concetti on denominazioni.id_denom = x_denom_concetti.id_denom
join concetti on x_denom_concetti.id_concetto = concetti.id_concetto
group by denominazioni.Denominazione
) as sq
group by sq.campo, sq.concetto
;
Risultato:

/* crea un documento KML usabile ad esempio col programma Google Earth */
SET SESSION group_concat_max_len = 1000000;
select
concat(
'
<?xml version="1.0" encoding="UTF-8"?>
<kml xmlns="http://www.opengis.net/kml/2.2" xmlns:gx="http://www.google.com/kml/ext/2.2" xmlns:kml="http://www.opengis.net/kml/2.2" xmlns:atom="http://www.w3.org/2005/Atom">
<Document>
<name>',sq.concetto,'.kml</name>
<Style id="s_ylw-pushpin">
<IconStyle>
<scale>1.1</scale>
<Icon>
<href>http://maps.google.com/mapfiles/kml/pushpin/ylw-pushpin.png</href>
</Icon>
<hotSpot x="20" y="2" xunits="pixels" yunits="pixels"/>
</IconStyle>
</Style>
<StyleMap id="m_ylw-pushpin">
<Pair>
<key>normal</key>
<styleUrl>#s_ylw-pushpin</styleUrl>
</Pair>
<Pair>
<key>highlight</key>
<styleUrl>#s_ylw-pushpin_hl</styleUrl>
</Pair>
</StyleMap>
<Style id="s_ylw-pushpin_hl">
<IconStyle>
<scale>1.3</scale>
<Icon>
<href>http://maps.google.com/mapfiles/kml/pushpin/ylw-pushpin.png</href>
</Icon>
<hotSpot x="20" y="2" xunits="pixels" yunits="pixels"/>
</IconStyle>
</Style>',
group_concat(XML separator '\n'),
'</Document>
</kml>'
) as `KML`
from
(
SELECT
concetti.`campo di concetti` as campo,
concetti.concetto,
concat(
'<Placemark>
<name>', luoghi.nome, '</name>
<description>',GROUP_CONCAT(denominazioni.Denominazione),'</description>
<LookAt>
<longitude>',luoghi.`grado di longitudine`,'</longitude>
<latitude>',luoghi.`grado di latitudine`,'4</latitude>
<altitude>0</altitude>
<heading>3.792984664259817</heading>
<tilt>0</tilt>
<range>30917.97286332985</range>
<gx:altitudeMode>relativeToSeaFloor</gx:altitudeMode>
</LookAt>
<styleUrl>#m_ylw-pushpin</styleUrl>
<Point>
<gx:drawOrder>1</gx:drawOrder>
<coordinates>',luoghi.`grado di longitudine`,',',luoghi.`grado di latitudine`,',0</coordinates>
</Point>
</Placemark>'
) as XML
FROM denominazioni
join x_denom_luoghi on denominazioni.id_denom = x_denom_luoghi.id_denom
join luoghi on x_denom_luoghi.id_luogo = luoghi.id_luogo
join x_denom_concetti on denominazioni.id_denom = x_denom_concetti.id_denom
join concetti on x_denom_concetti.id_concetto = concetti.id_concetto
group by luoghi.sigla
) as sq
group by sq.campo, sq.concetto
;
Risultato:
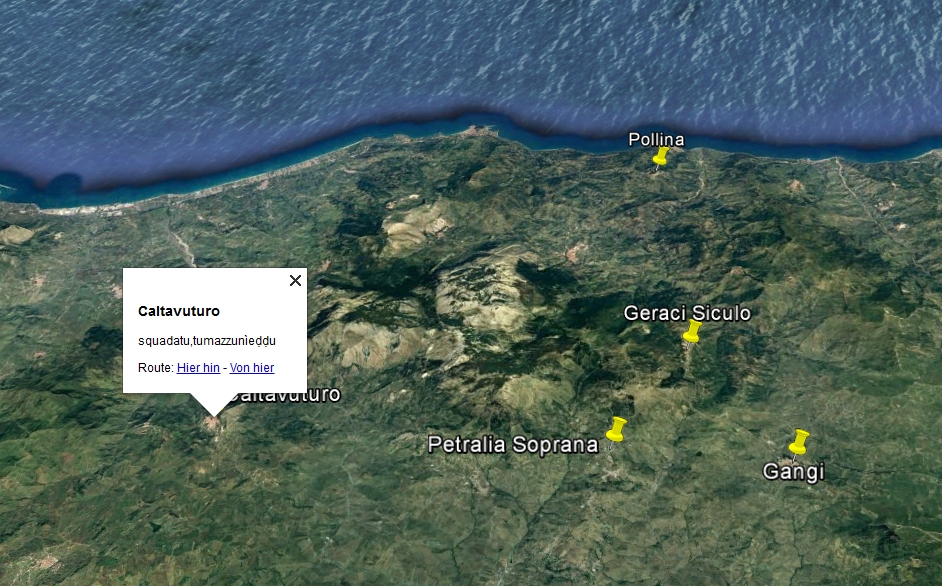
archivio KML, usabile per esempio col programma Google Earth. La schermata qui sotto mostra la superficie di Google Earth dopo l'apertura del file KML:
Parte pratica
Finora abbiamo presentato teoricamente la nostra metodologia. Ma siamo in un Workshop ed ormai passiamo al lavoro pratico che faremo insieme durante le due o tre ore seguenti. E rimaniamo sempre al vocabolario pascolare delle Madonie e al libro di Roberto Sottile.
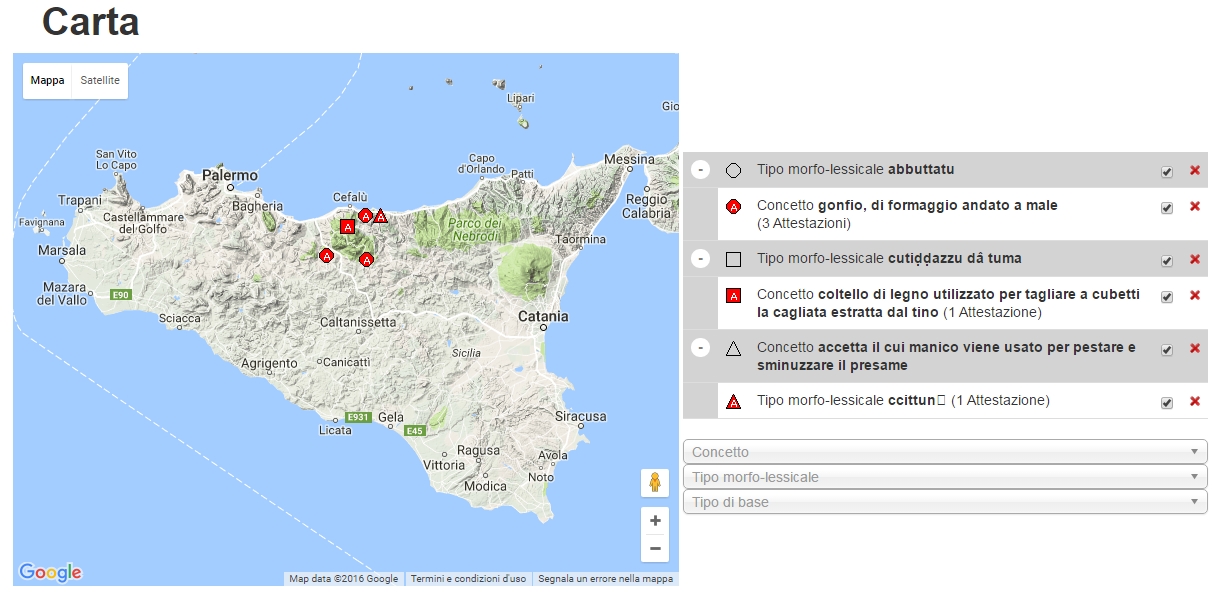
Siamo riusciti di estrare dal Word-File tutti i tipi morfologici del lessico e li abbiamo inserito in una banca dati molto simile a quella di cui abbiamo parlato finora. Ci siamo ristretti al campo della produzione del formaggio. Nella banca dati adesso si trovano 512 tipi morfologici. Sono anche registrati gli informazioni sulla provenienza e sul significato. Questi dati sono gia disponibili su una cartina online che è accessibile al indirizzo http://www.als-online.gwi.uni-muenchen.de/carta/:
Purtroppo i tipi phonetici trascritti nel alfabeto fonetico internazionale (IPA) nel word-file sono, diciamo, "danneggiati" in un modo che non sono leggibili. Per questo è necessario digitare i tipi fonetici nella banca dati a mano usando il sistema X-SAMPA che permette digitare i singoli segni del IPA usando esclusivamente segni disponibili su una tastiera europea. Un elenco del sistema X-SAMPA si trova qui: https://commons.wikimedia.org/wiki/X-SAMPA?uselang=it
Diamo un esempio come procedere. Ecco il tipo lessicale "scacciuni" dal lessico di Roberto Sottile:

Al inizio del primo paragrafo si trova il lemma, vuol dire il tipo lessicale. Dopo il lemma sono elencati i tipi fonetici rappresentanti quel tipo lessicale. Le sigle indicano le comuni in cui i tipi fonetici relativi sono attestati.
Sistema didattico: http://dhvlab.gwi.uni-muenchen.de/mgmt/labuser/signup
Accesso al sistema banca dati: http://dhvlab.gwi.uni-muenchen.de/sql
Documentazione X-SAMPA: https://commons.wikimedia.org/wiki/X-SAMPA?uselang=it