

Il presente contributo è stato redatto da Christina Mutter e Beatrice Colcuc in occasione della presentazione di VerbaAlpina nell'ambito dei Seminari di Cultura Digitale dell'Università di Pisa il 4 maggio 2022.

1. Il progetto VerbaAlpina

- VerbaAlpina. Der alpine Kulturraum im Spiegel seiner Mehrsprachigkeit ('VerbaAlpina. L'area culturale alpina riflessa nel suo multilinguismo)
- Atlante linguistico del territorio alpino
- Finanziamento della Deutsche Forschungsgemeinschaft (DFG, Fondazione tedesca per la ricerca) dal 2014 come progetto a lungo termine (prospettiva fino al 2026)
- Combinazione di linguistica e informatica nel quadro delle Digital Humanities
- Cooperazione tra l'Istituto di Filologia Romanza e il Gruppo IT per le scienze umane (ITG) della LMU (Team)
2. VerbaAlpina: Studiare la complessità alpina
Studio del lessico dialettale delle tre famiglie linguistiche della regione alpina: romanza, germanica, slava (Romania alpina, Germania alpina, Slavia alpina). (Mappa interattiva)
2.1 Area di studio: la regione alpina
Area di ricerca di VerbaAlpina
- Limitazione dell'area di studio: Perimetro della Convenzione delle Alpi
- Convenzione delle Alpi: accordo internazionale (1995) tra gli 8 paesi alpini e l'UE per lo sviluppo sostenibile e la protezione delle Alpi
- Superficie di 190.600 km2
- include parti di 6 paesi diversi (D, A, CH, I, F, SLO) e 2 paesi completi (FL, MC)
2.2. Generalità dell'area alpina
- 3 famiglie linguistiche rappresentate da continua dialettali
- Gradi di frammentazione dialettale:
- Romanza: molto frammentata
- Germanica: abbastanza frammentata
- Slava: poco frammentata
- Le zone di distribuzione delle 3 famiglie linguistiche non possono essere limitate a stati specifici
- Romanzo: varietà del continuum assegnabili a diverse lingue (francese, italiano, occitano, francoprovenzale, romancio, ladino e friulano)
- Germanico: varietà alemanne e bavaresi, con alcune isole linguistiche walser e bavaresi antiche (cimbri) sul lato meridionale
- Slavo: dialetti sloveni, usati anche nelle comunità italiane e austriache
I dialetti alpini sono:
- storicamente primari, cioè originati nelle zone in cui sono parlati, solo successivamente sono stati coperti da lingue storicamente secondarie (poi standard)
- usati localmente e all'orale
Lingue standard:
- Uso a livello regionale / statale
- Campo della scrittura, nei mass media
- alfabetizzazione, comunicazione dei cittadini con l'amministrazione, produzione di testi letterari, ecc.
- italiano, francese, tedesco, sloveno
Inoltre, presenza di lingue minori:
- occitano
- francoprovenzale/arpitano
- romancio
- ladino
- friulano
cfr. minoranze linguistiche d'Italia
- due livelli in scambio osmotico: i dialetti assorbono elementi dalle lingue standard e viceversa
- i parlanti di alcune zone alpine parlano non solo una, ma due o tre lingue standard (e altrettanti dialetti)
2.3. Obiettivi di VerbaAlpina
- documentare aree di parole che spesso attraversano i confini di una delle tre famiglie linguistiche (geolinguistica interlinguistica)
- identificare le caratteristiche (soprattutto lessicali) comuni al di là dei confini individuali dei dialetti e delle lingue
- evidenziare i punti etnolinguistici in comune e le divergenze
- Superare la tradizionale limitazione degli stati-nazione
Esempi: lat. *excocta / butyrum
Cosa rende la regione alpina così interessante come area di studio?
- ampia omogeneità etnografica e topografica (somiglianze geologiche, limitazione a singole forme economiche tradizionali)
- forte eterogeneità linguistica (3 famiglie linguistiche, diverse lingue, grande diversità di dialetti)
- zona di confine di diversi stati
- rete relativamente densa di atlanti linguistici e dizionari
2.4. Domini concettuali
Lessico di:
Fase I: 10/14 -10/17, alpicoltura e lavorazione del latte
Fase II: 11/17-10/20, natura (formazioni paesaggistiche/meteorologia/fauna/flora)
Fase III: 11/20-10/23, vita moderna (ecologia/turismo)
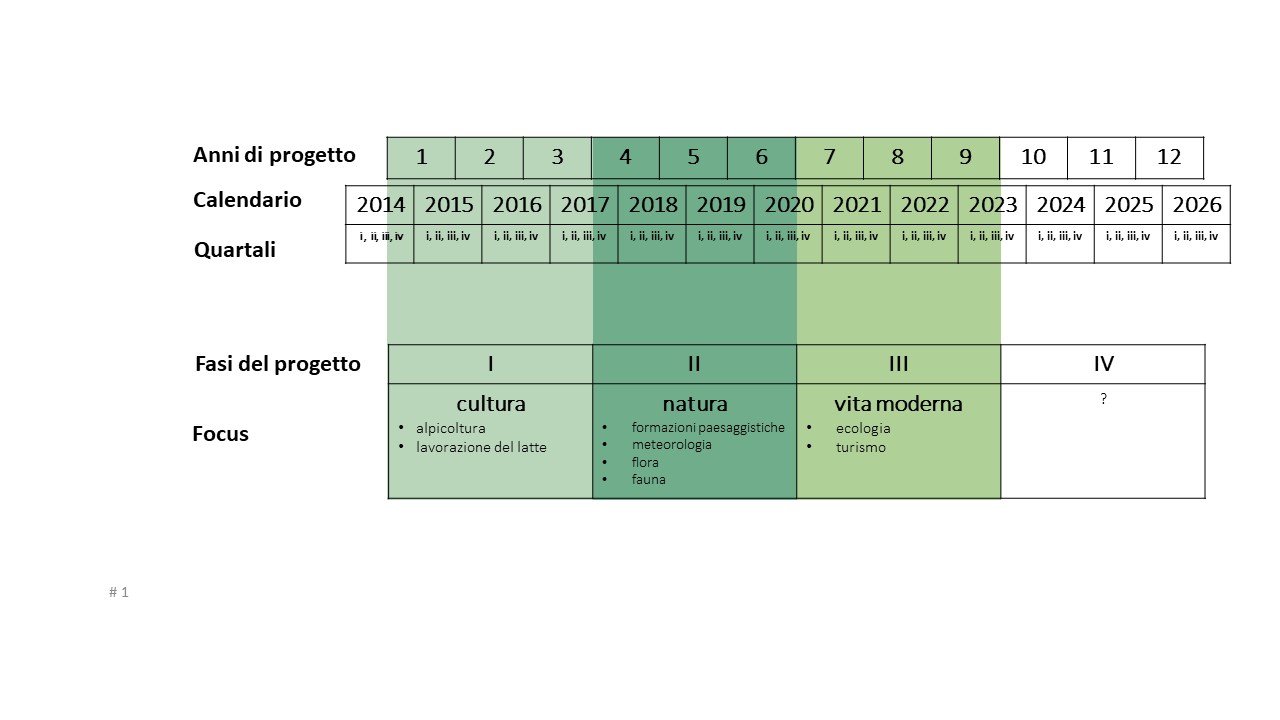
Schema riassuntivo delle fasi progettuali di VerbaAlpina
- I domini concettuali sono selezionati in base alla tradizione dell'etnolinguistica romanza
- etnolinguistica = studio linguistico delle culture europee e non europee
- La ricerca dialettologica nel senso di Cardona (Cardona 1995) è etnolinguistica quando i dati linguistici sono raccolti e analizzati in stretta connessione con la cultura quotidiana dei parlanti
- nella tradizione romanza, la ricerca etnolinguistica è stata istituita dall'AIS (Atlante linguistico e tematico dell'Italia e della Svizzera meridionale)
Accesso ai domini concettuali attraverso:
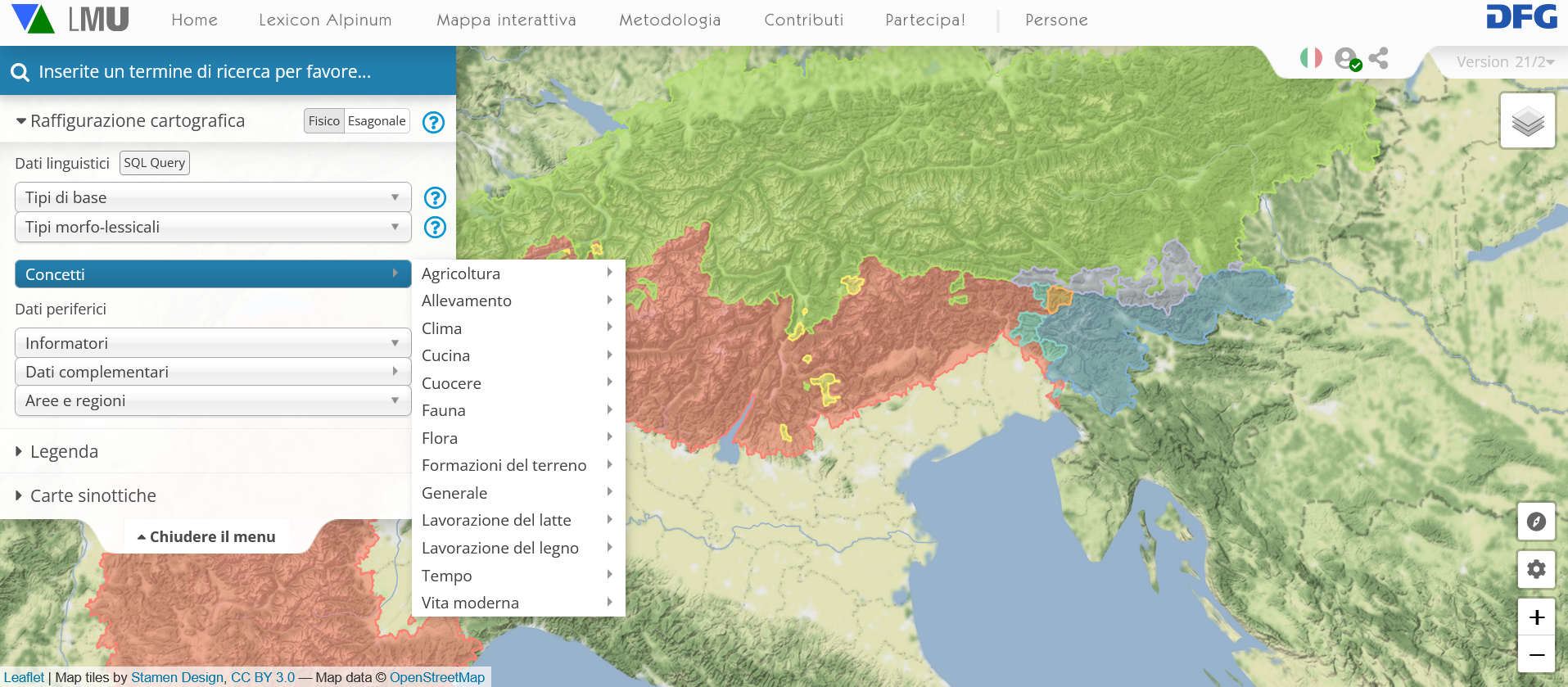
Accesso ai tre domini concettuali attraverso la cartina interattiva
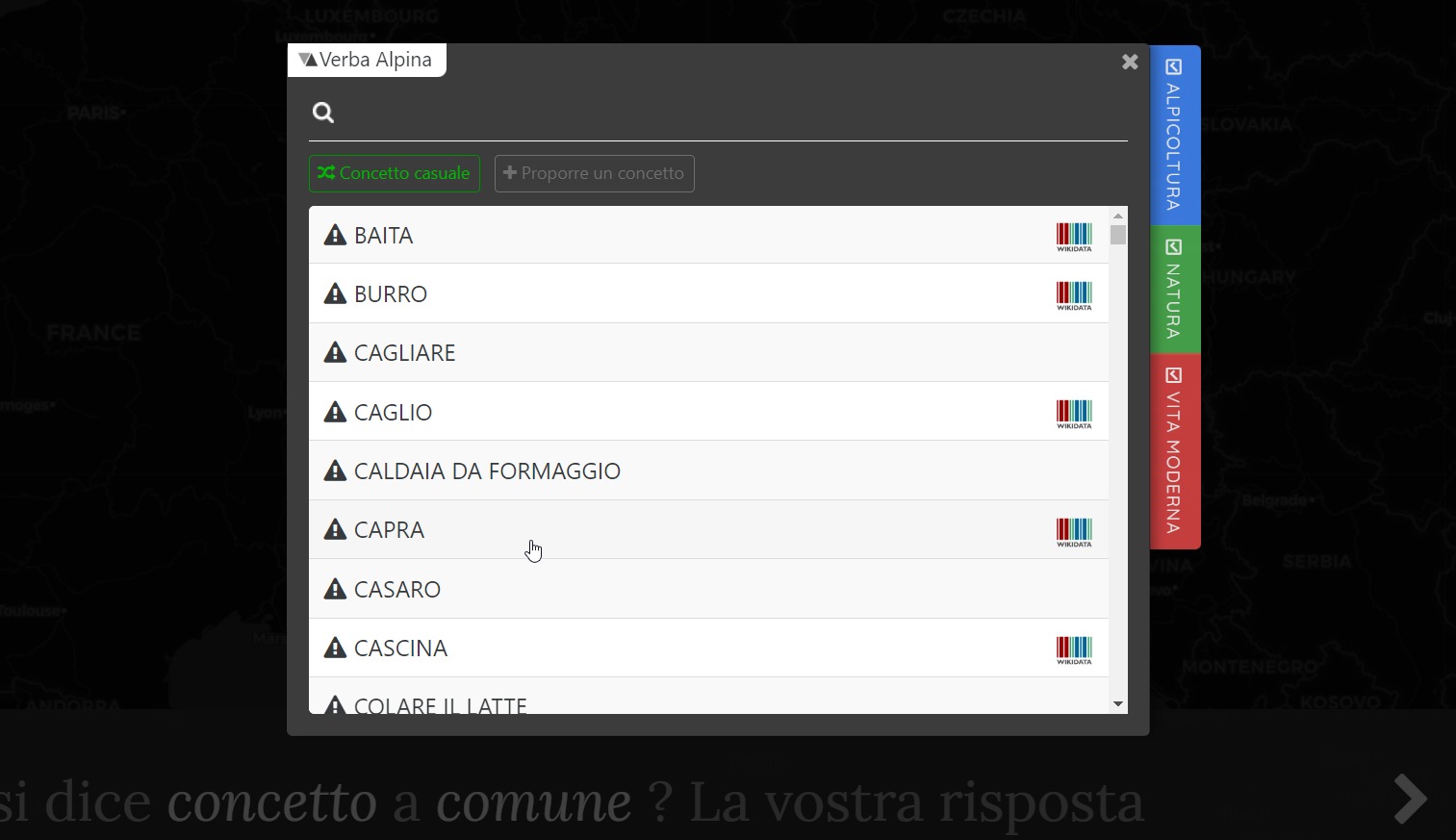
L'accesso ai domini concettuali attraveso la piattaforma di crowdsourcing
3. Dati
3.1. Atlanti e dizionari della regione alpina
La seguente cartina mostra le zone di rilevamento dei singoli atlanti e dizionari che coprono parti dell'area alpina:
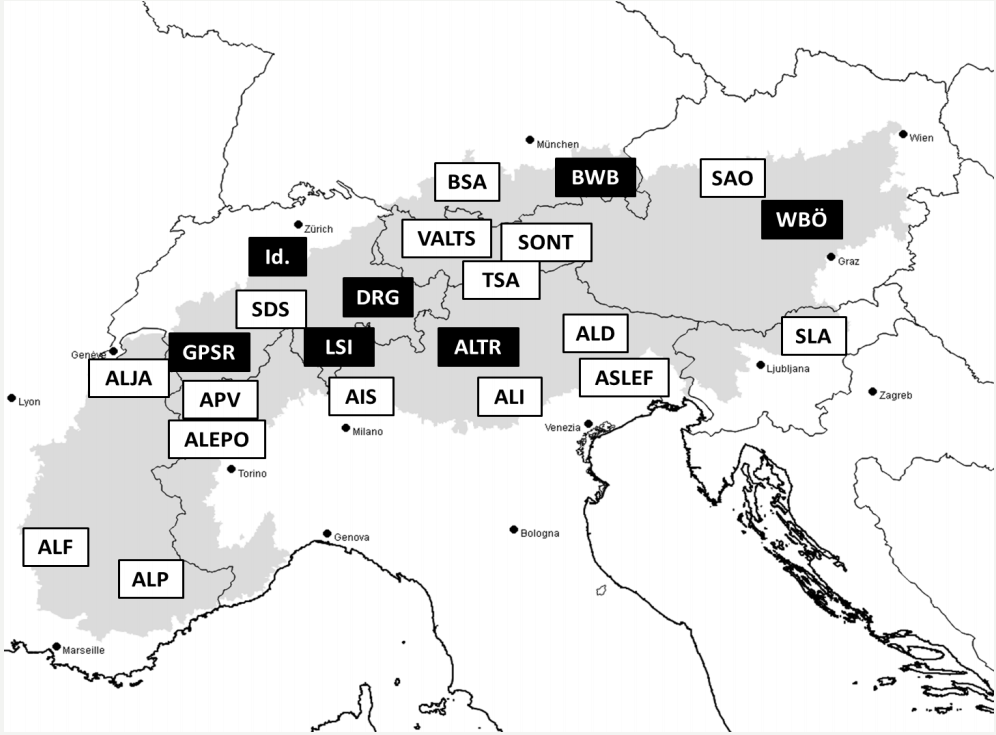
Atlanti linguistici e dizionari nell'area alpina
Atlanti linguistici e dizionari nell'area alpina
3.1.1. Tipologia delle fonti
Gli atlanti linguistici utilizzati da VA come fonti di dati sono caratterizzati dalle seguenti caratteristiche:
- I dati ivi contenuti sono georeferenziabili: i comuni sono considerati come l'unità più piccola di riferimento
- Diverse famiglie linguistiche: romanza, germanica, slava
- Diverse tradizioni di ricerca (romanistica, germanistica, slavistica)
Atlanti linguistici romanzi
- Mappe analitiche: le espressioni sono rese in maniera completa
- Importanza della documentazione
- Creazione di relazioni spaziali tra le fonti è lasciata al lettore
- Sistema di trascrizione: Böhmer-Ascoli
Esempi: AIS map 1401, il fienile; ALF map 1, abeille
Atlanti linguistici germanici
- Mappe sintetiche: le espressioni vengono sintetizzate e rese attraverso dei simboli
- Le relazioni spaziali sono riprodotte sulla mappa
- Sistema di trascrizione: Theutonista
Esempi:
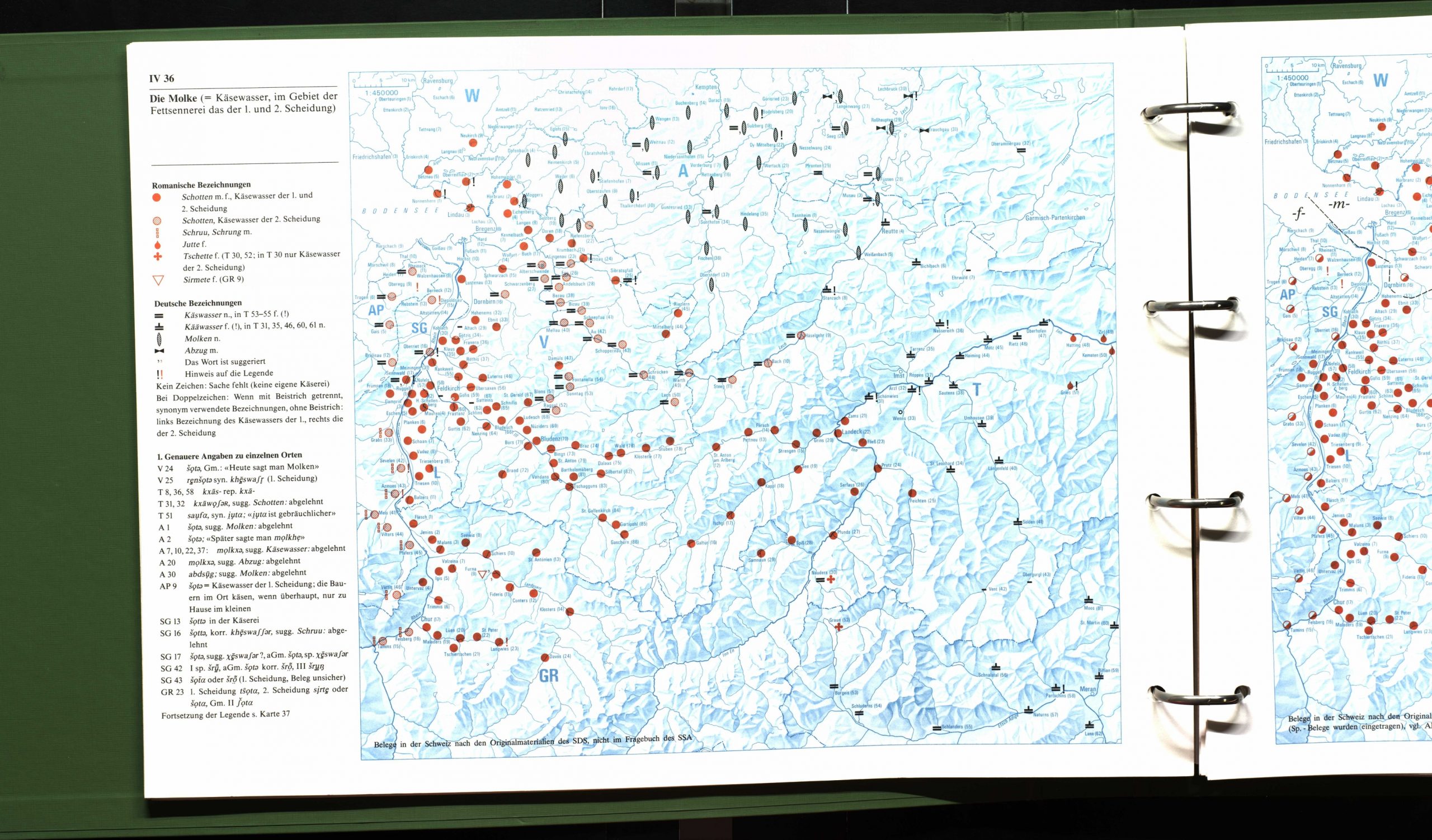
VALTS IV, 36 1, Molke (Käsewasser) ('siero')
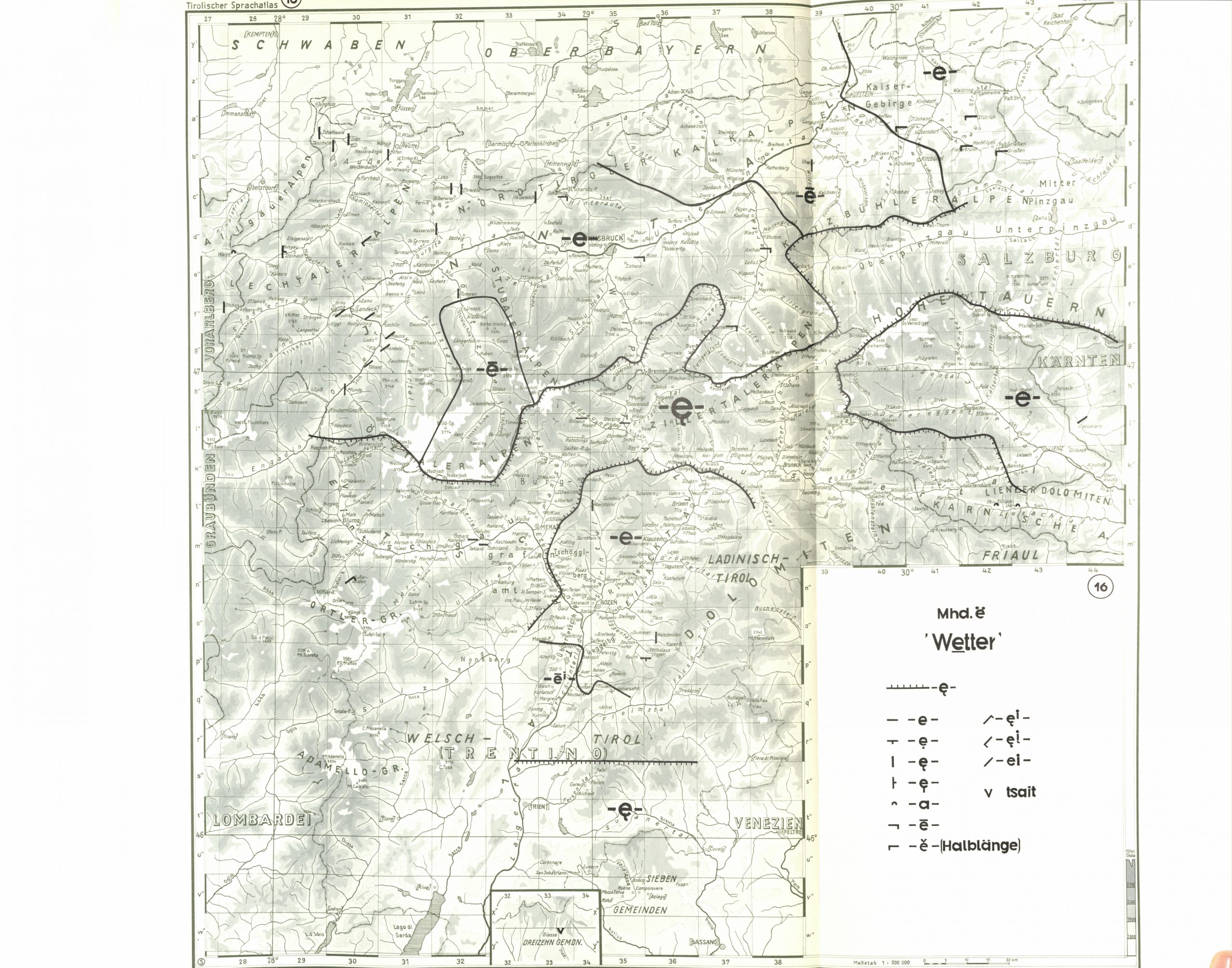
TSA, Karte 16, das Wetter (il meteo)
SLA: Atlante linguistico sloveno
vedi atlanti germanici
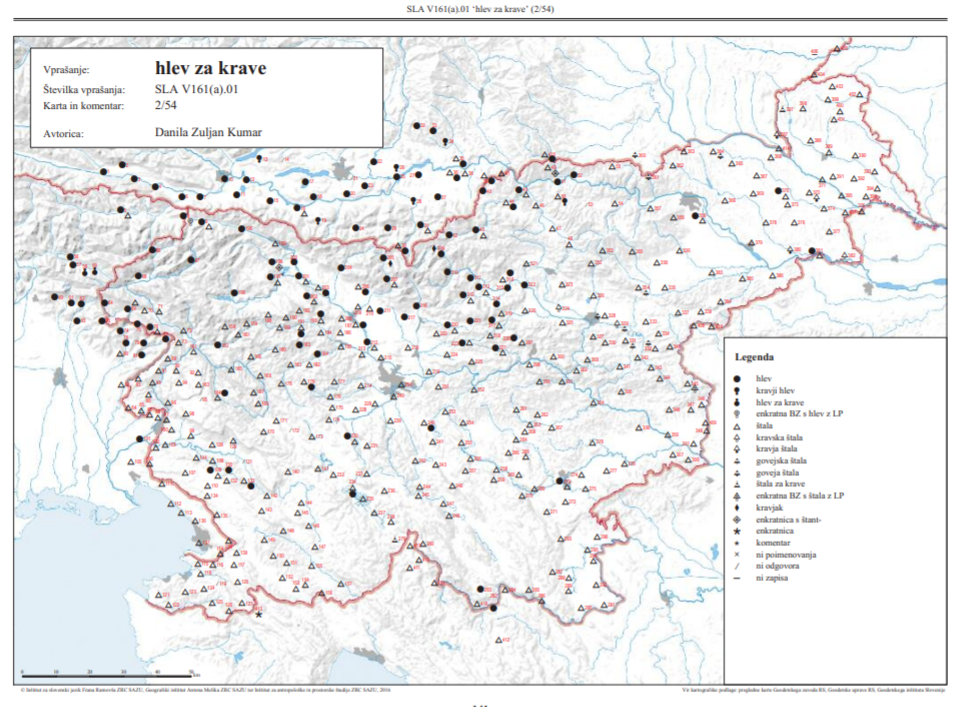
SLA, Karte 55, hlev za krave 'la stalla'
4. Diverse focus di interesse
-
BSA (Bayerischer Sprachatlas) / ALD-I e ALD-II (Atlant linguistich dl ladin dolomitich y di dialec vejins; Atlante linguistico del ladino dolomitico e dei dialetti adiacenti) non contengono nessuna mappa (o pochissime) relative a concetti fondamentali come CASARO, MUNGERE, CAGLIO, PASTORE ecc.
-
L'AIS (Sprach- und Sachatlas Italiens und der Südschweiz), invece, contiene molte carte su concetti etnografici e anche disegni di oggetti tipici alpini come la cartina1206, la zangola.
3.2. Crowdsourcing
Definizione:
"Crowdsourcing ist eine interaktive Form der Leistungserbringung, die kollaborativ oder wettbewerbsorientiert organisiert ist und eine große Anzahl extrinsisch oder intrinsisch motivierter Akteure unterschiedlichen Wissensstands unter Verwendung moderner IuK-Systeme auf Basis des Web 2.0 einbezieht." (Traduzione italiana: Il crowdsourcing è una forma interattiva di fornitura di servizi organizzata in modo collaborativo o competitivo che coinvolge un gran numero di attori motivati estrinsecamente o intrinsecamente di diversi livelli di conoscenza che utilizzano i moderni sistemi informatici basati sul Web 2.0) Martin/Lessmann/Voß 2008
- Crowdsourcing di VerbaAlpina: i parlanti di un dialetto alpino vengono contattati direttamente e chiamati a fornire parole dialettali
- Parallelamente alle fonti di dati stampati o digitali (vedi sopra), VerbaAlpina raccoglie nuovi dati provenienti dai parlanti di un dialetto alpino attraverso lo strumento di crowdsourcing
Obiettivi del crowdsourcing (Link alla piattaforma):
- bilanciare le incoerenze tra le fonti già disponibili
- eliminare le lacune o le imprecisioni
- marcare termini obsoleti come tali
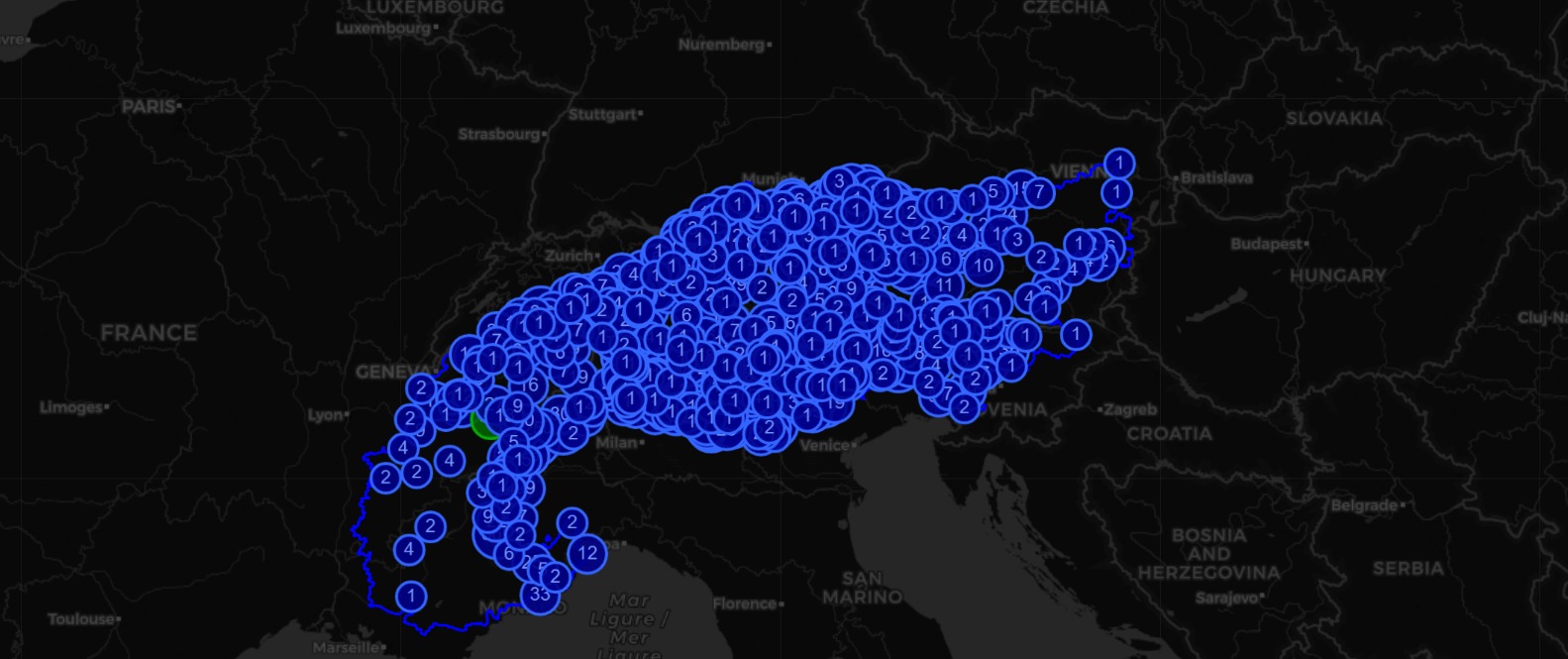
Visualizzazione dei contributi crowd
- simboli rotondi blu: luoghi dai quali VerbaAlpina ha registrato parole dialettali provenienti da crowd, la cifra indica il numero delle parole ricevute
- Statistica Live
3.3. Riassunto
- Eterogeneità dei dati
- Scopo: struttura
- Principio: semplificare il confronto tra i dati e le fonti
4. Elaborazione dei dati
Tre fasi principali, ma:
Problema: acquisizione di dati specificamente da atlanti linguistici
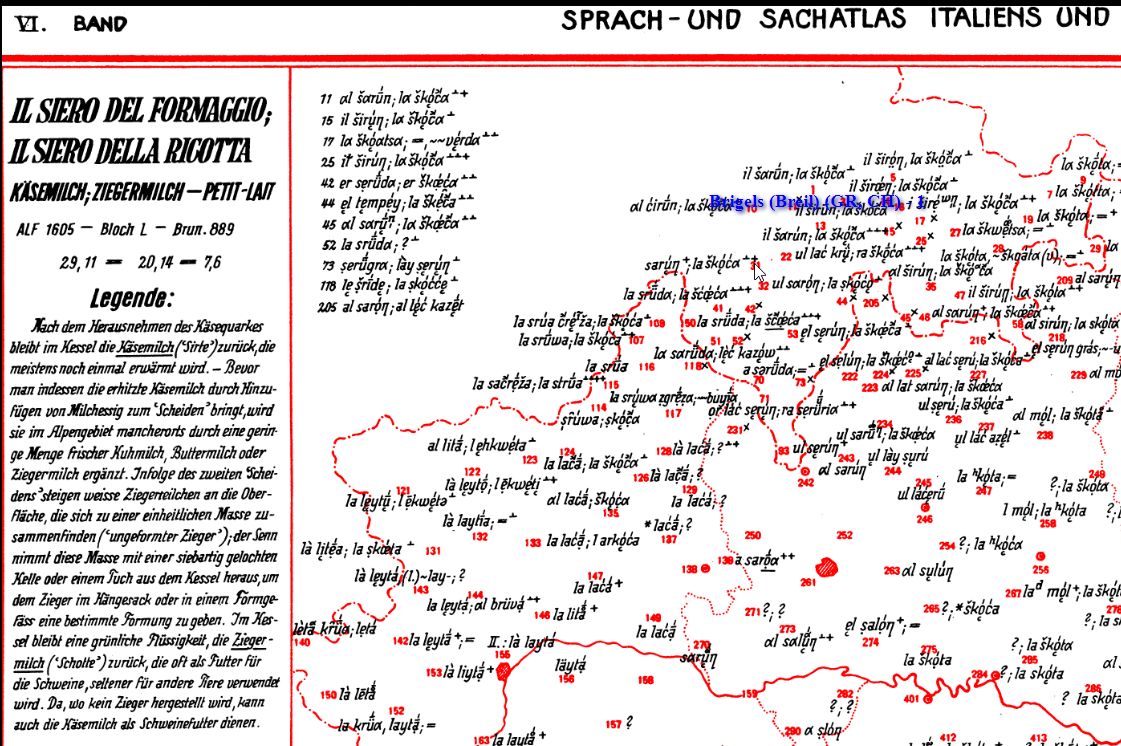
Sistemi di trascrizione usati negli atlanti linguistici (per esempio AIS: Böhmer-Ascoli) non sono sempre codificati in Unicode (quindi non è sempre possibile rilevare con OCR)
Soluzione:
4.1. Trascrizione
- Prima fase dell'omogeneizzazione dei dati
- VerbaAlpina utilizza il BetaCode (sistema di trascrizione elaborato dal Thesaurus Linguae Graecae).
- Regole di trascrizione: ad ogni carattere specifico di ogni atlante corrisponde uno o più caratteri ASCII
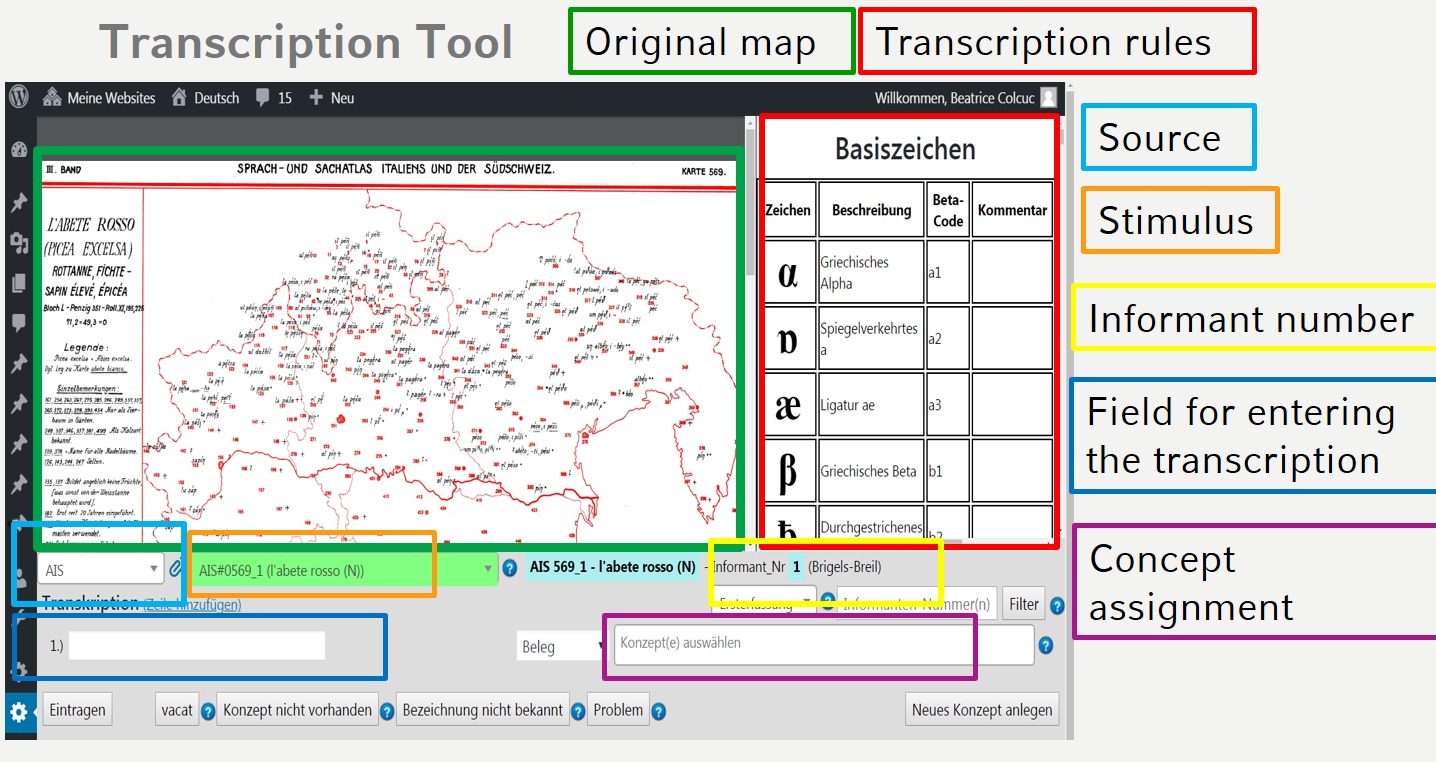
Sistema di trascrizione di VerbaAlpina
- Dati crowd non vengono trascritti
La tabella seguente mostra i dati nella tabella Aeusserungen (espressioni, parole grezze)

4.2. Tokenizzazione
- I dati linguistici trascritti (oppure i dati dal crowd) vengono segmentati in token
- I token vengono convertiti in IPA
Il processo di tokenizzazione funziona come segue:
| Forma in Beta Code | Forma in IPA | CONCETTO |
| una1 mu:g/a1 da1 va/c)/ | unɑ myʤɑ dɑ vˡaʨ | MANDRIA DI MUCCHE |
| Tokenizzazione | ||
| una1 | unɑ | ARTICOLO |
| mu:g/a1 | myʤɑ | MANDRIA |
| da1 | dɑ | PREPOSIZIONE |
| va/c)/ | v ˡaʨ | MUCCA |
- Tool per la tokenizzazione (Id_stimulus 1550)
4.3. Tipizzazione
- Uno dei compiti centrali di VerbaAlpina
- Raggruppamento di attestazioni linguistiche secondo le caratteristiche linguistiche
- Scopo della tipizzazione: strutturare la varietà delle varianti linguistiche in modo gestibile
- Definizione di "tipo morfo-lessicale": classe di espressioni linguistiche / rappresentante di un gruppo di varianti fonetiche
- Le attestazioni linguistiche che condividono le seguenti proprietà, sono raggruppate sotto lo stesso tipo morfo-lessicale:
-
- Famiglia linguistica
- Categoria grammaticale
- Affissazione
- Genere
- Tipo di base lessicale
| Token | kˈaːvra | kabrˈuŋ | kavrˈɛt | kawrˈɛt |
| Famiglia linguistica | roa | roa | roa | roa |
| Categoria grammaticale | sub | sub | sub | sub |
| Affisso | - | + | + | + |
| Genere | f | m | m | m |
| Tipo morfo-lessicale | capra | caprone | capretto | capretto |
| Tipo di base | lat. capra | lat. capra | lat. capra | lat. capra |
- La forma di un tipo morfo-lessicale è rappresentata dai lemmi dei dizionari di riferimento:
- Gruppo germanico/slavo: solo una lingua standardizzata (tedesco e sloveno)
- Gruppo romanzo: tutti i tipi morfo-lessicale sono rappresentati dalle forme standard francesi e italiane, se disponibili (beurre/burro; lait/latte ecc.); altrimenti, si prende solo una delle due forme (italiano O francese), come nel caso di ricotta; se non esiste una variante del tipo in nessuna delle due lingue romanze di riferimento, si usa la voce di un dizionario dialettale (BLad, LSI ecc.);
- Nel caso non siano disponibili voci adatte nei dizionari di riferimento, VerbaAlpina propone un tipo morfo-lessicale proprio.
- Tipo di base: la prima forma storicamente attestata di quel tipo ((≅ etimo, ma l'etimo si riferisce allo strato linguistico immediatamente precedente)
5. Accesso ai dati
5.1. Mappa interattiva
- Diversi filtri, diverse possibilità di visualizzazione
- Ricerca semasiologica: dai tipi di base / tipi morfo-lessicali ai CONCETTI (esempio 1: mappa ai CONCETTI del tipo morfo-lessicale gallina (roa); esempio 2: mappa al tipo di base lat. *cappellus)
- Ricerca onomasiologica: dal CONCETTO ai tipi morfo-lessicali / tipi di base (esempio: mappa delle realizzazioni del concetto ERLE
- Dati extralinguistici: Iscrizioni, toponomastica, infrastrutture, ecc. (esempio: Mappa dei toponimi germanici in Italia)
5.2. LexiconAlpinum
- Elenco in ordine alfabetico di tipi morfo-lessicali, tipi di base e concetti raccolti da VerbaAlpina
- Commenti linguistici: in caso di informazioni insufficienti nei dizionari di riferimento o per concetti centrali come FORMAGGIO, BURRO, CASCINA DI MONTAGNA, ecc.
- Varie opzioni tramite icone:
- Visualizzare i dati sulla mappa interattiva
- Citare la voce (attraverso il link diretto)
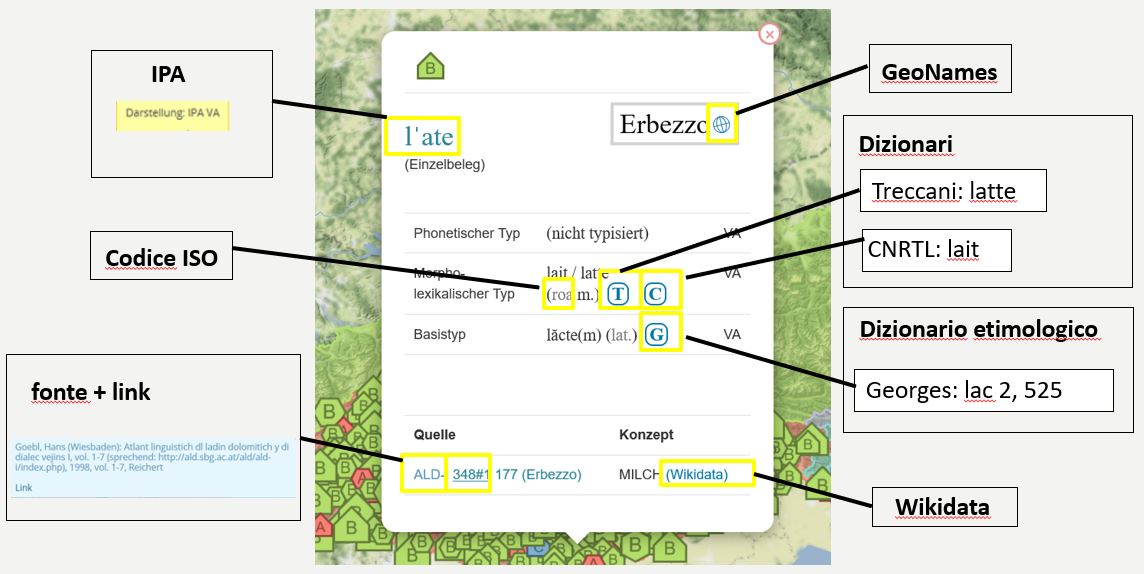
- Cliccando su "dati" si accede a tutte le informazioni raccolte nella finestra informativa della mappa interattiva (link agli articoli corrispondenti nei dizionari di riferimento, link all'elemento Wikidata, ecc.)
- Obiettivo: contestualizzare lessicograficamente ed enciclopedicamente il materiale VA
- Esempio: Anke (gem m.)
5.3. API
- API: "application programming interface" ‚interfaccia di programmazione di un'applicazione'
- API di VerbaAlpina
6. I principi FAIR
Dati di ricerca devono essere FAIR:
- F_indable (ritrovabile)
- A_ccessible (accessibile)
- I_nteroperable (interoperabile)
- R_eusable (riutilizzabile)
--> principi postulati da Wilkinson 2016 come principi guida per la gestione di dati scientifici
Dati di ricerca sono...
F_indable --> tramite cataloghi di biblioteche e aggregatori di dati
A_ccessible --> tramite licenze open access
I_nteroperable --> attraverso la compatibilità dei database e la loro interconnessione
R_eusable --> risulta da F, A, I
6.1. Cosa fa il progetto VerbaAlpina per rendere i suoi dati FAIR
F_indable
Cooperazione con la Biblioteca Universitaria dell'Università di Monaco (i dati di VerbaAlpina sono disponibili su UB Discover, versione 19/1 + 19/2) e i due progetti che si occupano della gestione dei dati di ricerca "e-humanities-interdisziplinär" (fino al 2021) e "GeRDI" (Generic Research Data Infrastructure) (fino al 2019)
A_ccessible
Licenza Creative Commons (compatibile con open access e open source) per tutti i dati gestiti da VerbaAlpina (fino alla versione 18/1: CC BY SA 3.0, dalla versione 18/2: CC BY SA 4.0)
I_nteroperable
- attraverso una granulazione fine dei dati tramite
- elaborazione strutturata dei dati (trascrizione, tokenizzazione, tipizzazione)
- assegnazione di dati normativi (Q-ID, L-ID, GND, GeoNames ecc.)
- arricchimento con metadati in formato DataCite e CIDOC CRM
- assegnazione di identificatori persistenti (per esempio DOI, Digital Object Identifiers) - accesso a dati primari e metadati (tramite mappa interattiva, Lexicon Alpinum, API)
R_eusable
risulta da F, A, I
- i requisiti di F, A, R mirano a essere sia human readable (leggibili dall'uomo) che machine readable (leggibili dalla macchina) --> si applicano alla comunicazione uomo-macchina-uomo e alla comunicazione macchina-macchina
- I --> si applica solo alla comunicazione macchina-macchina, MA: è fondamentale per il progresso della ricerca
6.1.1. Interoperabilità: Assegnazione di dati normativi
Dati normativi creati da VerbaAlpina
Per le 3 entità principali
- tipi morfo-lessicali: L
- concetti: C
- comuni: A
Per esempio:
L1435, „babeurre (m.) (roa.)“
C612, „ALMHÜTTE“ (baita)
A60171, „Sils in Engadin/Segl“
Identificatori persistenti di istituzioni esterne (basi di conoscenza (knowledge bases), banche dati che contengono dati normativi, dizionari di riferimento)
- Q-IDs di Wikidata (per concetti), in parte anche L-IDs di Wikidata (per tipi morfo-lessicali)
- in parte i cosiddetti GND della Biblioteca Nazionale Tedesca (per i concetti) (Gemeinsame Normdatei, file standard comune)
- GeoNames di www.geonames.org (per comuni)
- Codici ISO 639-3 (per lingue)
- Identificatori di dizionari di riferimento (per tipi morfo-lessicali + tipi di base)
- DOIs (Digital Object Identifiers, assegnato ad ogni singolo dato)
Bibliographie
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7
- Cardona 1995 = Cardona, Giorgio Raimondo (1995): La foresta di piume. Manuale di etnoscienza, Roma, Bari, Laterza
- Martin/Lessmann/Voß 2008 = Martin, Nicole/ Lessmann, Stefan/ Voß, Stefan (2008): Crowdsourcing: Systematisierung praktischer Ausprägungen und verwandter Konzepte, Berlin, in: Bichler, Martin: Multikonferenz Wirtschaftsinformatik 2008, GITO-Verlag. Link
- Wilkinson 2016 = Wilkinson, M. D. et al. (2016): The FAIR Guiding Principles for scientific data management and stewardship, in: Scientific Data 3:160018. Link