Die folgenden Ausführungen ergänzen und exemplifizieren die Darlegungen von Thomas Krefeld zum sprachwissenschaftlichen Gesamtkonzept von VerbaAlpina (VA). Wiederholungen können dabei nicht vollständig ausgeschlossen werden. Im Zentrum stehen hier die Aspekte der informatischen Konzeption und der konkreten technischen Umsetzung.
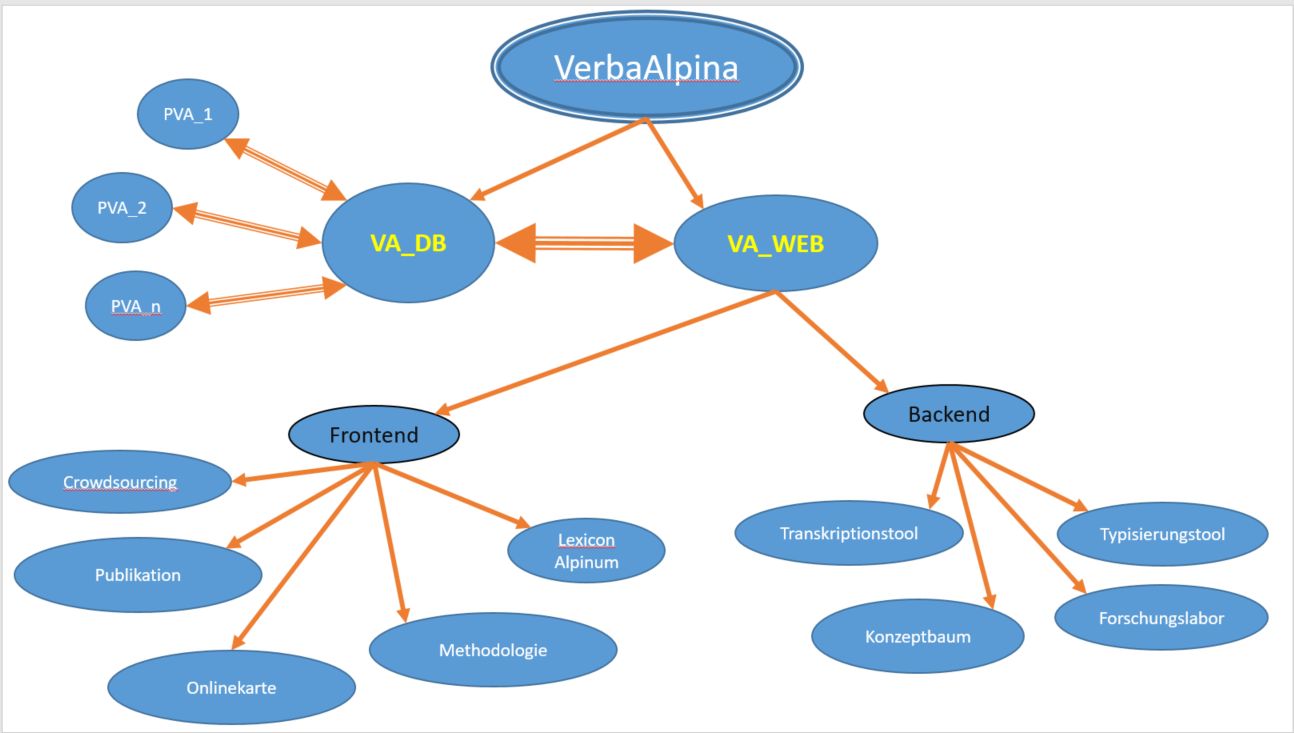
VerbaAlpina gliedert sich aufs Ganze gesehen in zwei große Teilbereiche: Ein Datenbanksystem (VA_DB) und eine Webschnittstelle (VA_WEB) mit einer Reihe von Detailfunktionen, die im Folgenden vorgestellt werden. VerbaAlpina besitzt außerdem eine Reihe von Kooperationspartnern, von denen jeder eine eigene Datenbank (PVA) nutzen kann. Die dort gespeicherten Daten können in den Datenbestand von VA_DB einfließen und umgekehrt.
VA_DB
VerbaAlpina basiert im Kern auf einer MySQL-Datenbank, um die herum sich verschiedene Module und Funktionalitäten gruppieren.
Eine MySQL-Datenbank ist eine sog. relationale Datenbank, was, stark vereinfacht gesprochen, bedeutet, dass die dort abgelegten Daten in Tabellengestalt organisiert sind. Die Datenstrukturierung erfolgt nach ganz bestimmten Regeln, die vom sog. relationalen Datenmodell vorgegeben sind. Dieses besagt im wesentlichen, dass alle Daten, die in einer Tabelle versammelt werden, Vertreter ein und derselben "Objektklasse" – ein und derselben "Entität" – sein müssen. Dies hat zur Folge bzw. gleichermaßen zur Voraussetzung, dass alle in einer Tabelle gespeicherten Daten identische Eigenschaftskategorien aufweisen müssen. So wären beispielsweise in einer Tabelle, in der Informationen über Autos gespeichert werden sollen, Eigenschaftskategorien wie "Farbe" oder "Höchstgeschwindigkeit" sinnvoll. Eine Liste mit Personen in dieser Tabelle unterbringen zu wollen, wäre nicht möglich bzw. sinnlos. Sie müsste in einer eigenen Tabelle abgelegt werden, die Eigenschaftskategorien wie "Geburtsort", "Geschlecht" oder "Wohnort" aufweisen würde. Es gibt noch eine Reihe weiterer Regeln, die bei der Anlage einer relationalen Datenbanktabelle beachtet werden müssen bzw. beachtet werden sollten. Dazu gehört z.B. das Gebot, dass eine Tabelle keine Redundanzen enthalten darf oder dass in einem Feld einer Tabelle jeweils nur "atomare" Werte und keine Wertelisten abgelegt werden dürfen. Die schrittweise Anpassung einer Datenstruktur an das Idealbild des relationalen Datenmodells nennt man "Normalisierung".
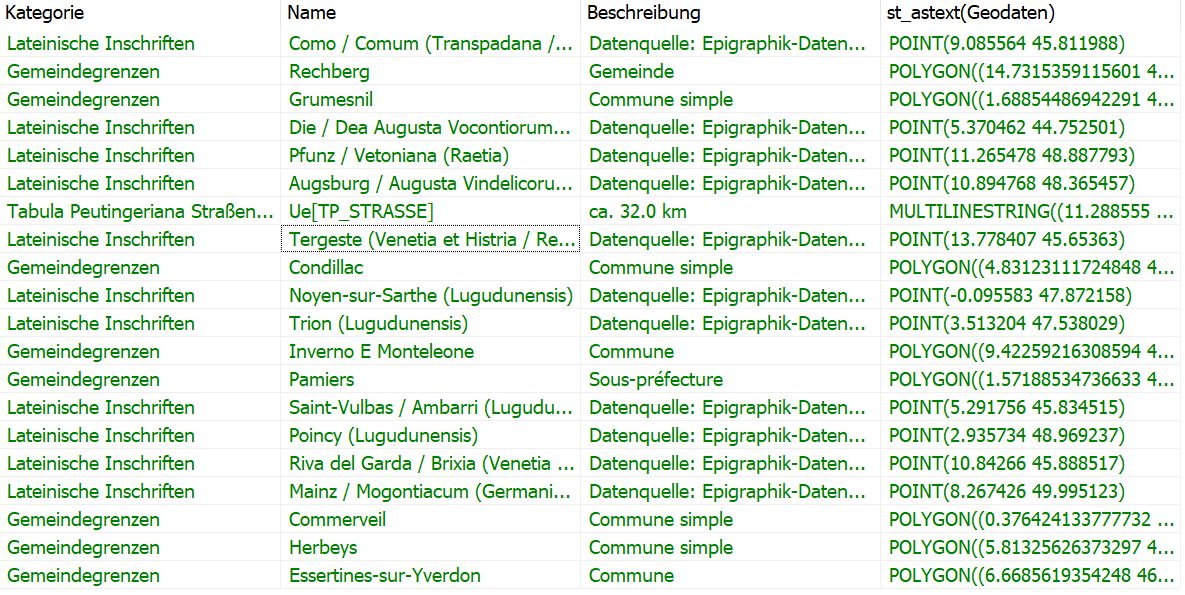
Die von VerbaAlpina gesammelten Daten werden also getreu den eben skizzierten Regeln in den Tabellen einer MySQL-Datenbank abgelegt. Die Strukturierung der Daten folgt dabei dem vom Projekt verfolgten Hauptinteresse: Welche Konzepte werden oder wurden zu welcher Zeit an welchem Ort mit welchen Wörtern bezeichnet? Dieser Satz gibt die Kategorien der zentralen Datenstruktur vor. In Gestalt einer relationalen Tabelle stellt sich der Untersuchungsgegenstand demnach folgendermaßen dar:
| Konzept |
Bezeichnung |
wann |
wo |
| RAHM |
Rom |
1962-2003 |
Sennwald |
| SENNHÜTTE |
Sennhaus |
1985-2004 |
Hohenems |
| DREHBUTTERFASS |
Ankenkübel |
1962-2003 |
Mollis |
| ZIEGENHIRT |
chevrier / capraio |
2005 |
Romeno |
| ALMHÜTTE |
Käser |
1965, 1969, 1971 |
Laces###D:Latsch |
| BIESTMILCH |
Biestmilch |
2017 |
Ebenau |
| SCHEUNE |
feniera |
1975, 1979, 1986 |
Reillanne |
| BUTTER |
rance / rancido |
1928-1940 |
Ramosch |
| BAUERNHOF |
kmetija |
2011ff. |
Železniki |
| EIMER |
lambar |
2011ff. |
Dobrova-Polhov Gradec |
Die Tabelle wirft sofort Fragen auf, deren Antworten wiederum an einer geeigneten Stelle innerhalb des vorgegebenen relationalen Datenmodells untergebracht werden müssen. So wäre z.B. zu fragen, aus welcher Quelle die entsprechende Information stammt. Im Fall von VerbaAlpina sind dies, zumindest bislang, überwiegend Sprachatlanten, z.T. auch Wörterbücher mit georeferenziertem Inhalt, daneben aber auch Daten, die über das Internet gesammelt wurden. Eine weitere Frage wäre, wo die genannten Ortschaften genau liegen, vielleicht auch wieviele Einwohner sie haben usw. All diese Daten würden also entweder in neue Spalten der vorliegenden Tabelle oder auch, nötigenfalls, in neue Tabellen eingetragen werden. Im Fall der genannten Ortschaften bietet es sich schon deswegen an, sie in einer neuen Tabelle zu speichern, weil die meisten der Ortschaften in der Tabelle mit den Sprachbelegen mehrfach auftreten. Informationen zur geographischen Lage oder Einwohnerzahl müssten andernfalls in der Sprachdatentabelle mehrfach gespeichert werden, was dem Gebot der Redundanzvermeidung widersprechen würde.
Ein relationales Datenbankmanagementsystem wie MySQL erlaubt die problemlose Verknüpfung der auf verschiedene Tabellen verteilten, aber dennoch zusammengehörigen Daten.
Die Erfassung und Strukturierung der von VerbaAlpina bearbeiteten Daten wird auf diese Weise sehr schnell sehr komplex. Aktuell (Mai 2018) besteht die Datenbank von VerbaAlpina (VA_DB) aus
- 128 Tabellen, die um
- 12 sog. Views (virtuelle Tabellen)
- 21 Funktionen und
- 35 Prozesse
ergänzt werden. Eine Reihe dieser Datenbankobjekte haben jedoch eine rein technische Funktion oder sind temporär.
Die Organisation der Sprachdaten im relationalen Datenformat hat gegenüber der herkömmlichen Repräsentation in Sprachatlanten und Wörterbüchern entscheidende Vorteile. Während Sprachatlanten jeweils nur die onomasiologische Perspektive bedienen, also die Frage beantworten können, mit welchen Wörtern ein ausgewähltes Konzept bezeichnet wird, und Wörter umgekehrt ausschließlich darüber Auskunft geben, welche Konzepte von einer ausgewählten Vokabel bezeichnet werden können (semasiologische Perspektive), vereint das relationale Datenmodell beide Möglichkeiten in einem System.
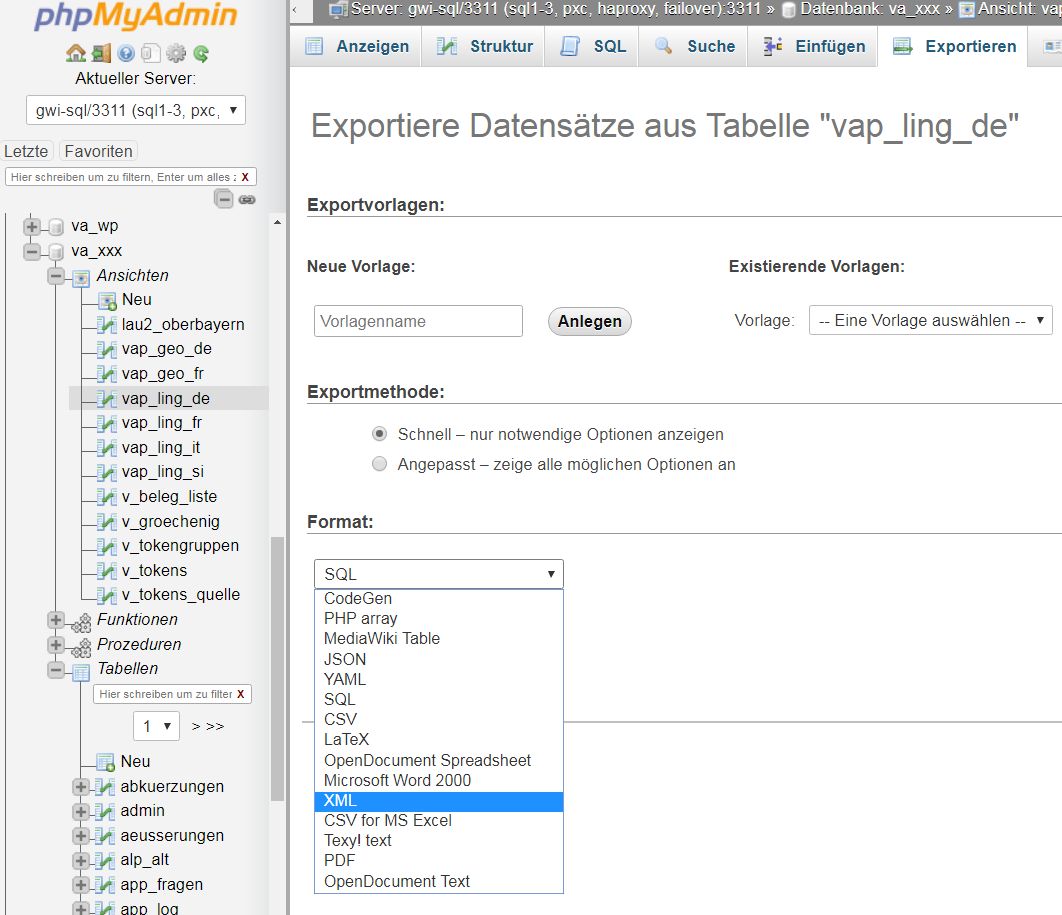
Neben dem relationalen Datenformat existiert noch eine Reihe weiterer Datenformate wie z.B. XML, JSON oder Graphen (= Strukturen mit Knoten und Kanten). Für welches dieser Formate man sich entscheidet, liegt zum einen an den Eigenheiten des abzubildenden Gegenstands daneben aber durchaus auch an persönlichen Vorlieben. Grundsätzlich gilt, dass einmal strukturierte Daten, die in einem bestimmten Datenformat vorliegen, in andere Datenformate transformiert werden können. So ist es z.B. möglich, die Tabellen einer MySQL-Datenbank im XML-Format auszugeben. Die speziell für MySQL-Datenbanken entwickelte generische Webschnittstelle PhpMyAdmin (PMA) bietet für dieses und andere Datenformate vorgefertigte Exportroutinen. Im folgenden Beispiel werden gefilterte Daten aus der Tabelle vap_ling_de in eine XML-Datei exportiert. Das entsprechende Dialogfeld von PMA sieht folgendermaßen aus:
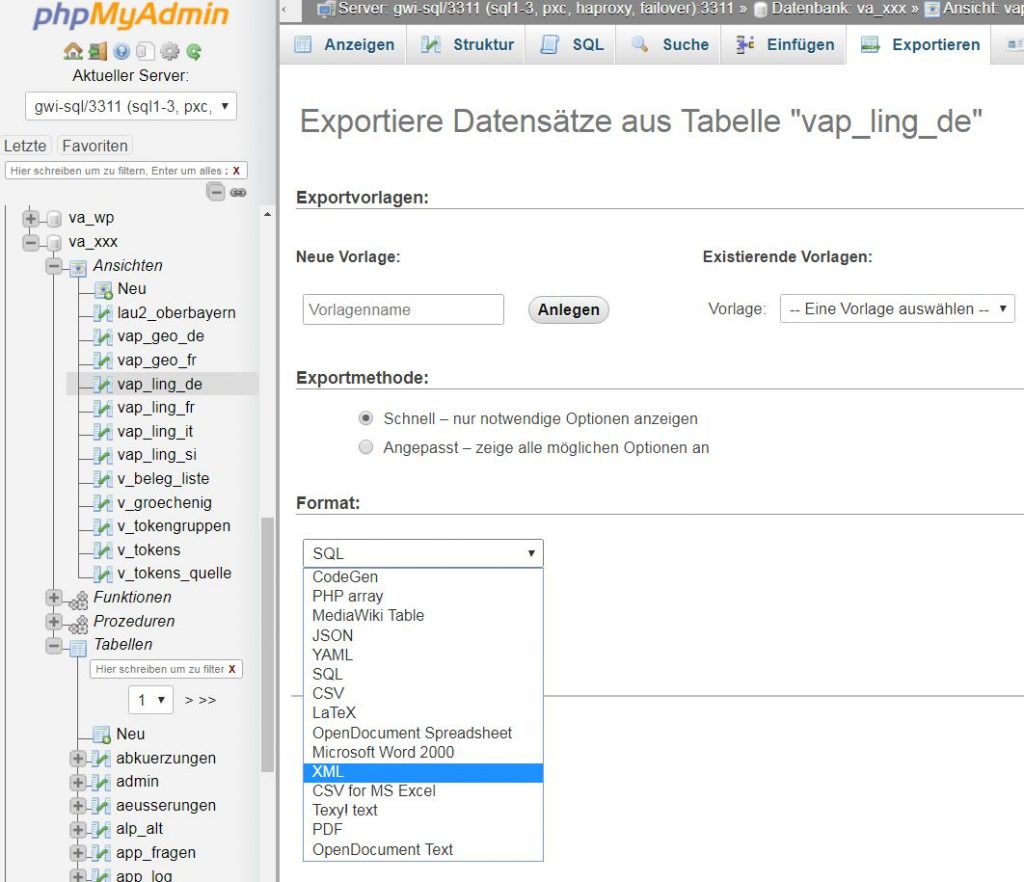
Die Auswahlliste zeigt die verschiedenen Formate, in die die Daten exportiert werden können. Nach Auswahl von XML wird vom Browser eine Datei heruntergeladen, die die Daten im gewünschten Format enthalten. Hier ein Ausschnitt der XML-Datei:
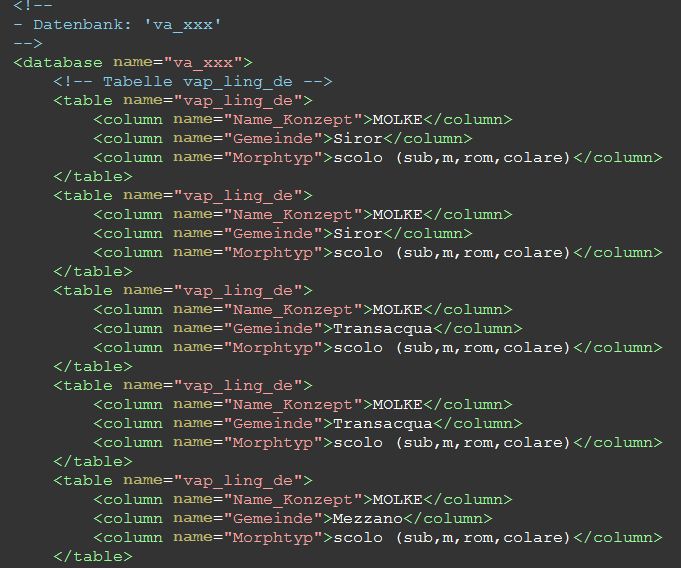
Das vorliegende Format ist generisch und mag im Einzelfall nicht den spezifischen Erfordernissen entsprechen. Mit etwas erweiterten technischen Kenntnissen lassen sich jedoch im Grunde beliebige Datenformate erzeugen und exportieren.
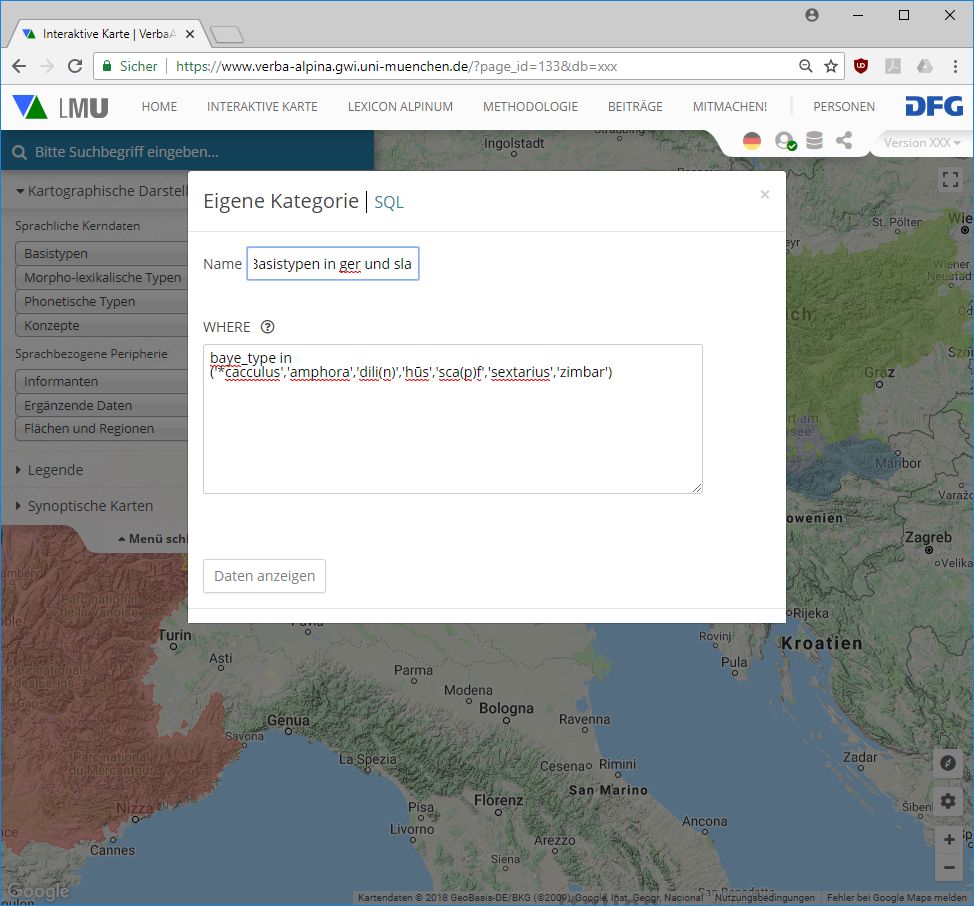
Ein wichtiger Grund, warum sich VerbaAlpina für das relationale Datenformat entschieden hat, ist die Tatsache, dass dergestalt strukturiertes Datenmaterial nach den Regeln der relationalen Algebra analysiert werden kann. Für entsprechende Operationen sowie generell für die Verwaltung relationaler Datenbestände steht eine spezielle formale Sprache, die sog. Structured Query Language, kurz SQL, zur Verfügung. Ihre Syntax basiert auf der englischen Umgangssprache und ist relativ leicht zu erlernen. Grundlegend sind die Konzepte der Selektion und der Projektion. Mit Selektion ist die Auswahl von Zeilen, die bestimmte Kriterien erfüllen, gemeint, Projektion bezeichnet demgegenüber die Auswahl von Spalten. Sämtliche mit der Sprache SQL ausführbaren Operationen basieren letztlich auf den Regeln der relationalen Algebra.
Um nun mit Hilfe von SQL sämtliche Vokabeln aus dem Datenbestand herauszufiltern, die ein ganz bestimmtes Konzept bezeichnen, muss ein entsprechender Filter formuliert werden. Da bei diesem Vorgang Zeilen, und keine Spalten, ausgewählt werden, handelt es sich um eine Selektion. Das Beispiel geht davon aus, dass die Daten in einer Tabelle mit Namen "Belege" abgelegt wurden. Eine entsprechende Tabelle ist in der Datenbank von VerbaAlpina nicht vorhanden. Die konkrete Syntax lautet dann wie folgt:
select *
from Belege
where konzept = "SENNHÜTTE"
;
Ergebnis:
| Konzept |
Typ |
wann |
wo |
| SENNHÜTTE |
Sennhaus |
1985-2004 |
Lustenau |
| SENNHÜTTE |
cascina |
1928-1940 |
Bivio |
| SENNHÜTTE |
cabotte |
1928-1940 |
Borgomaro |
| SENNHÜTTE |
casero |
1974-1986 |
Forni Avoltri |
| SENNHÜTTE |
baita |
1928-1940 |
Colico |
| SENNHÜTTE |
Käser |
2017 |
Schmirn |
| SENNHÜTTE |
cascharia |
1928-1940 |
Soglio (Graubünden) |
| SENNHÜTTE |
Schwaige |
2017 |
Villandro###D:Villanders |
| SENNHÜTTE |
casa |
1928-1940 |
Lanzada |
| SENNHÜTTE |
Alp(e) |
1962-2003 |
Davos |
| SENNHÜTTE |
Sennhütte |
1985-2004 |
Alberschwende |
| SENNHÜTTE |
casone |
1928-1940 |
Antrona Schieranco |
Um umgekehrt die verschiedenen Bedeutungen des italienischen Wortes malga zu ermitteln, formuliert man:
select *
from Belege
where Bezeichnung = "malga"
;
Ergebnis:
| Konzept |
Typ |
wann |
wo |
| ALM |
malga |
2012 |
Moena |
| ALMHÜTTE |
Malga |
1965, 1969, 1971 |
Salorno###D:Salurn |
| HERDE |
malga |
1928-1940 |
Ardez |
| HIRTENHÜTTE |
malga |
1974-1986 |
Ravascletto |
| KUHHERDE |
malga |
1928-1940 |
Albosaggia |
| SENNHÜTTE |
malga |
1928-1940 |
Rabbi |
Die Möglichkeiten von SQL sind schier grenzenlos, und es kann hier nur darum gehen, durch wenige Beispiele eine ungefähre Vorstellung zu vermitteln.
Das folgende Beispiel illustriert, wie sich aus einer bestimmten Tabelle der VerbaAlpina-Datenbank sämtliche morpholexikalischen Typen, die das Konzept BUTTER bezeichnen, extrahieren lassen. Das Ergebnis zeigt außerdem die Anzahl der bislang in VA_DB erfassten Einzelbelege, die dem jeweiligen morpholexikalischen Typ zugeordnet sind:
-- SQL-Statement
-- Finde sämtliche morpholexikalischen Typen, die das Konzept BUTTER bezeichnen,
-- und gib die jeweilige Häufigkeit des morpholexikalischen Typs an
select
Name_Konzept as Konzept,
group_concat(typ, ' (', anzahl, ')' separator ', ') as Morphtypen
from
(
select
count(*) as Anzahl,
a.Name_Konzept,
a.Typ
from vap_ling_de a
where
a.Name_Konzept like 'BUTTER'
and a.Art_Typ like 'Morph_Typ'
group by a.Typ
order by Anzahl desc
) sq
;
-- Ergebnis
BUTTER: beurre / burro (1264), Anke (866), Butter (348), Schmalz (271), paintg (96),
éponge / spongia (64), smalz (42), Buttern (24), unto (21), süßes Schmalz (20), puter (19),
pischada (19), Schmalzbutter (8), smalz crü (6), maslo (4), rance / rancido (3), bütér (3),
menata (3), fiore (2), balle / palla (2), süess Schmalz (2), süesses Schmaalz (2),
Brütschi (1), süess Schmaalz (1), brusco (1)
Im Vorgriff auf die weiter unten vorgestellten Funktionen der Webschnittstelle von VerbaAlpina (VA_WEB) sei hier erwähnt, dass das von VerbaAlpina verwendete WordPress-System die direkte Einbindung der Ergebnisse von Datenbankabfragen in WordPress-Beiträge wie den vorliegenden erlaubt. Diese Funktion wurde als sog. WordPress-Plugin ("SQLtoHTML") von VerbaAlpina entwickelt und steht als Modul auch für im Grunde beliebige andere WordPress-Installationen zur Verfügung. Das soeben vorgestellte SQL-Beispiel kann, eingebettet in eine spezifische Syntax, in den Text eines WordPress-Beitrags eingebettet werden. Im Frontend erscheint dann anstelle des Codes das Ergebnis der Abfrage.
Code (darf keinen Zeilenumbruch enthalten):
[[SQL:select Name_Konzept as Konzept, group_concat(typ, ' (', anzahl, ')' separator ', ') as Morphtypen from ( select count(*) as Anzahl, a.Name_Konzept, a.Typ from vap_ling_de a where a.Name_Konzept like 'BUTTER' and a.Art_Typ like 'Morph_Typ' group by a.Typ order by Anzahl desc ) sq ]]
Ergebnis im Frontend:
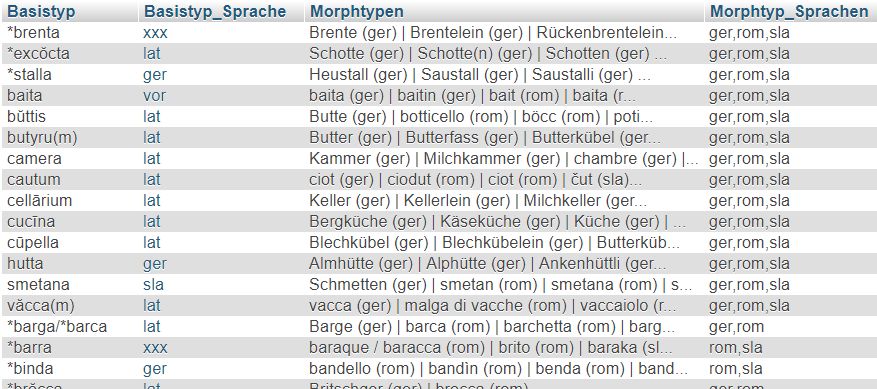
Ein weiteres Beispiel für die Möglichkeiten von SQL zeigt, wieviele verschiedene Basistypen den morphologischen Typen zur Bezeichnung des Konzepts SENNHÜTTE zugrundeliegen und wieviele morphologische Typen pro Basistypen bislang registriert sind:
-- SQL-Statement
/*
Errechne die Anzahl von morphologischen Typen, die das Konzept SENNHÜTTE bezeichnen
und die jeweils mit demselben Basistypen verbunden sind:
select
count(*) as Anzahl,
sq.basistyp,
group_concat(Typen separator ' | ') as Morphtypen
from
(
select distinct
a.Basistyp,
concat(a.Typ, ' (', a.Art_Typ, ')') Typen
from vap_ling_de a
where
a.Name_Konzept like 'SENNHÜTTE'
and a.Basistyp is not null
) sq
group by basistyp
order by Anzahl desc
;
-- --
-- Ergebnis
14: căsa(m): casino (Morph_Typ) | casini (Morph_Typ) | Casel (Morph_Typ) | casone (Morph_Typ) | casa (Morph_Typ) | casa da/di alp (Morph_Typ) | casella (Morph_Typ) | casello (Morph_Typ) | casa da fuoco (Morph_Typ) | casine (Morph_Typ) | casa da caschar (Morph_Typ) | casina (Morph_Typ) | caseta (Morph_Typ) | casinel (Morph_Typ)
8: hutta: Sennhütte (Morph_Typ) | Sentumhitta (Morph_Typ) | Hütte (Morph_Typ) | Almhütte (Morph_Typ) | Melkhütte (Morph_Typ) | Sennerhütte (Morph_Typ) | Berghütte (Morph_Typ) | Alphütte (Morph_Typ)
5: *sanio: Sennerei (Morph_Typ) | Sennhütte (Morph_Typ) | Sentumhitta (Morph_Typ) | Sennerhütte (Morph_Typ) | Sennhaus (Morph_Typ)
5: alpe: Alp(e) (Morph_Typ) | casa da/di alp (Morph_Typ) | Almhütte (Morph_Typ) | Alphütte (Morph_Typ) | cascina da/di alp (Morph_Typ)
5: alpes: Alpgemach (Morph_Typ) | Alp(e) (Morph_Typ) | Almhütte (Morph_Typ) | Alphütte (Morph_Typ) | Alm (Morph_Typ)
4: căpsa(m): cascina dal fuoco (Morph_Typ) | cascina per caschar (Morph_Typ) | cascina (Morph_Typ) | cascina da/di alp (Morph_Typ)
4: caseāria: Käser (Morph_Typ) | Chäseren (Morph_Typ) | casera (Morph_Typ) | caserìn (Morph_Typ)
3: *tegia: Teie(n) (Morph_Typ) | Tieje (Morph_Typ) | Tegia (Morph_Typ)
3: baita: baita (Morph_Typ) | baito (Morph_Typ) | bait (Morph_Typ)
2: *caseare: cascina per caschar (Morph_Typ) | casa da caschar (Morph_Typ)
... -- gekürzt
Das Beispiel zeigt z.B., dass insgesamt 14 unterschiedliche morpholexikalische Typen, die das Konzept SENNHÜTTE bezeichnen könnten, mit dem Basistypen "casa(m)" verbunden sind.
Das relationale Datenmodell und die Abfragesprache SQL erlauben auch weitergehende arithmetische und in der Folge statistische Berechnungen über dem Datenbestand. Das nachfolgende Beispiel berechnet den prozentualen Anteil der einzelnen Basistypen an der Gesamtzahl aller morpholexikalischer Typen, die das Konzept SENNHÜTTE bezeichnen:
-- SQL-Statement
-- Errechne den prozentualen Anteil der einzelnen Basistypen
-- an der Gesamtzahl aller morpholexikalischer Typen, die das Konzept SENNHÜTTE
select
sq.basistyp as Basistyp,
count(*) as Anzahl,
round(count(*) / (
select count(*)
from
(
select
a.Basistyp
from vap_ling_de a
where
a.Name_Konzept like 'SENNHÜTTE'
and a.Basistyp is not null
group by basistyp
) sq0
) * 100,2) as Prozentanteil
from
(
select distinct
a.Basistyp,
concat(a.Typ, ' (', a.Art_Typ, ')') Typen
from vap_ling_de a
where
a.Name_Konzept like 'SENNHÜTTE'
and a.Basistyp is not null
) sq
group by basistyp
order by Anzahl desc
;
-- Ergebnis
Basistyp | Anzahl | Prozentanteil
căsa(m) | 14 | 41.18
hutta | 8 | 23.53
alpe | 5 | 14.71
alpes | 5 | 14.71
caseāria | 4 | 11.76
căpsa(m) | 4 | 11.76
baita | 3 | 8.82
... -- gekürzt
Ende Mai 2018 umfasste die VerbaAlpina-Datenbank insgesamt
- 1167 unterschiedliche Konzepte sowie
- 5446 verschiedene morphologische Typen.
VA_WEB
Die zentrale Datenbank von VerbaAlpina, VA_DB, ist angebunden an die multifunktionale Webschnittstelle, die unter der Adresse https://www.verba-alpina.gwi.uni-muenchen.de (VA_WEB) im Internet erreichbar ist.
VA_WEB ist mit dem weit verbreiteten WordPress-Framework in den Programmiersprachen PHP und Javascript programmiert. Die Entwickler von VerbaAlpina haben eine Reihe von VerbaAlpina-spezifischen Funktionserweiterungen geschrieben. All diese Funktionserweiterungen sind modular als sog. "Plugins" – wie das bereits weiter oben erwähnte SQLtoHTML-Plugin – konzipiert, die frei zur Verfügung gestellt und nach Belieben auch in andere WordPress-Installationen übernommen werden können.
VA_WEB gliedert sich in einen öffentlichen Bereich, das sog. Frontend, und einen zugangsbeschränkten Bereich, das sog. Backend. Das Frontend ist gleichsam das Schaufenster des Projekts. Hier findet sich das bislang zentrale Analyseinstrument, die interaktive Onlinekarte, auf der das in der Datenbank gesammelte Material nach vorgegebenen Kriterien visualisiert werden kann. Eine besondere Bedeutung kommt dem Bereich "Methodologie" zu. Hier werden nach Stichworten gegliedert sämtliche Aspekte des Gesamtprojekts, von den wissenschaftlichen Grundlagen bis hin zur Erläuterung technischer Details und Vorgehensweisen, allgemeinverständlich erläutert und dokumentiert. Die Sektion "Methodologie" wird ständig erweitert bzw. nötigenfalls auch überarbeitet.
Das Web-Frontend dient auch als zentrale Publikationsplattform des Projekts. Unter der Rubrik "Beiträge" finden sich neben allgemeinem Informationsmaterial für die Öffentlichkeit auch ausgwählte Vorträge, die von den Projektmitarbeitern auf wissenschaftlichen und populären Veranstaltungen gehalten werden, sowie wissenschaftliche Beiträge in Artikelform.
Funktionen des Backends
Das Backend von VA_WEB bietet über die von WordPress standardmäßig bereitgestellten Basisfunktionen, zu denen auch die von VA verwendete Benutzerverwaltung gehört, eine Reihe von überwiegend individuell entwickelten Zusatzfunktionen, die in der Projektarbeit Verwendung finden:
Transkriptionstool
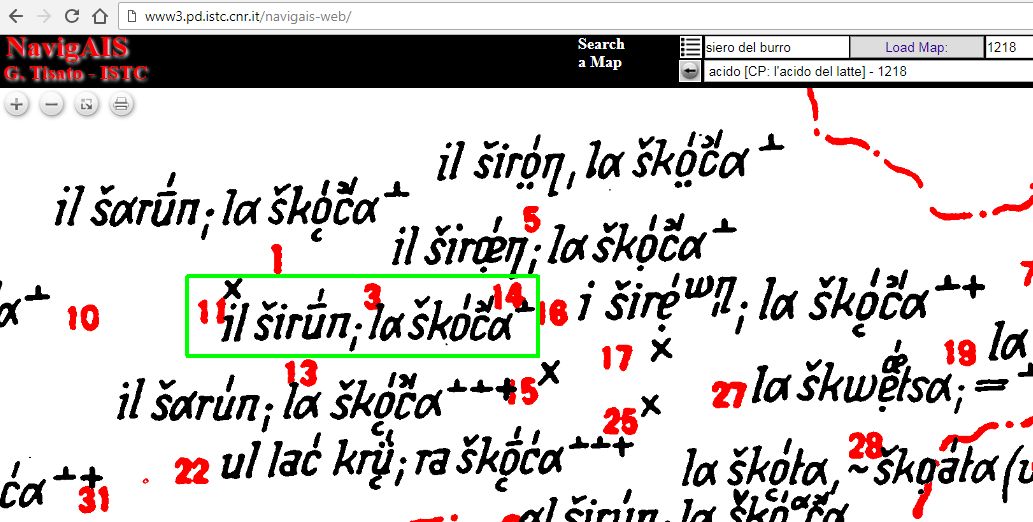
Die Erfassung von Daten speziell aus Sprachatlanten kann bislang nur manuell erfolgen. Der Einsatz von OCR (= Optical Character Recognition = automatische Verwandlung von Graphikdaten in elektronisch kodierten Text) ist in diesem Kontext nicht möglich. Das Hauptproblem besteht in der Zuordnung der auf den Karten eingetragenen Einzelbelege zu den jeweils richtigen Erhebungspunkten. Im folgenden Beispiel ist es für einen Computer de facto unmöglich zu entscheiden, welchem der durch die roten Zahlen bezeichneten Erhebungspunkte der grün markierte Beleg zuzuordnen ist.
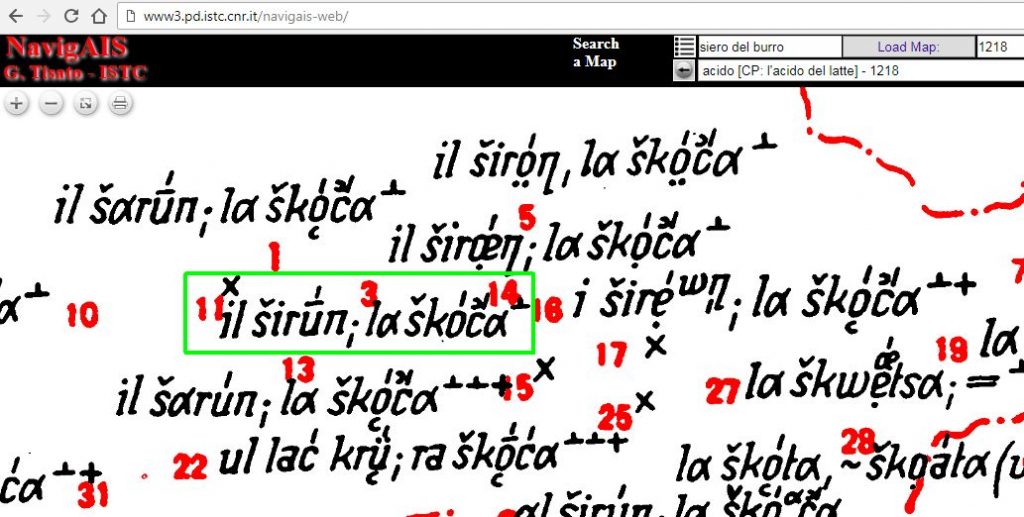
AIS-Karte 1218: Il siero del latte
Seit wenigen Wochen sind am Leibniz-Rechenzentrum (LRZ) bzw. am Lehrstuhl Prof. Kranzlmüller (Lehrstuhl für Kommunikationssysteme und Systemprogrammierung der LMU) ein, eventuell auch zwei Masterarbeiten ausgeschrieben, die Lösungsansätze für dieses Problem entwickeln sollen.
Die Datenerfassung kann dann automatisch unter Verwendung von OCR erfolgen, wenn das Material in der analogen Quelle in Tabellen- bzw. Listenform vorliegt. Gute Erfahrungen liegen mit dem Programm ABBYY Finereader vor. Das folgende Beispiel stammt aus dem Atlante Linguistico ed Etnografico del Piemonte Occidentale (ALEPO)
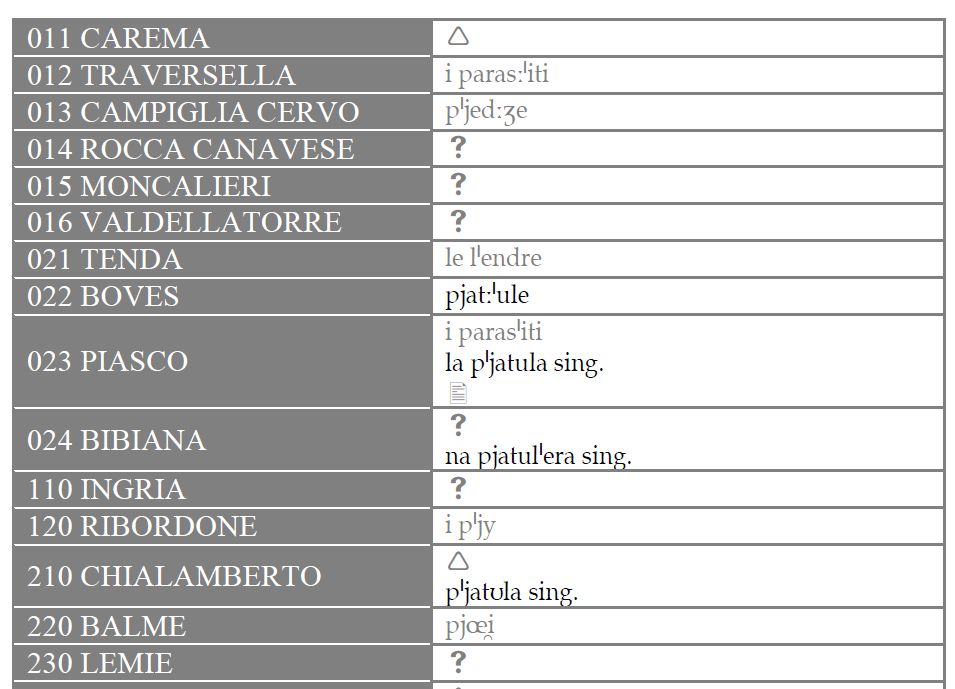
Daten in Listenform (hier: Alepo III-i-1: PARASSITI) erlauben den Einsatz von OCR
Aus dargelegten Gründen ist eine automatische Datenerfassung speziell von Datenmaterial aus Sprachatlanten bislang nicht möglich und eine manuelle Erfassung unumgänglich. Zur Erleichterung dieser Arbeit wurde ein spezielles Transkritptionstool entwickelt:
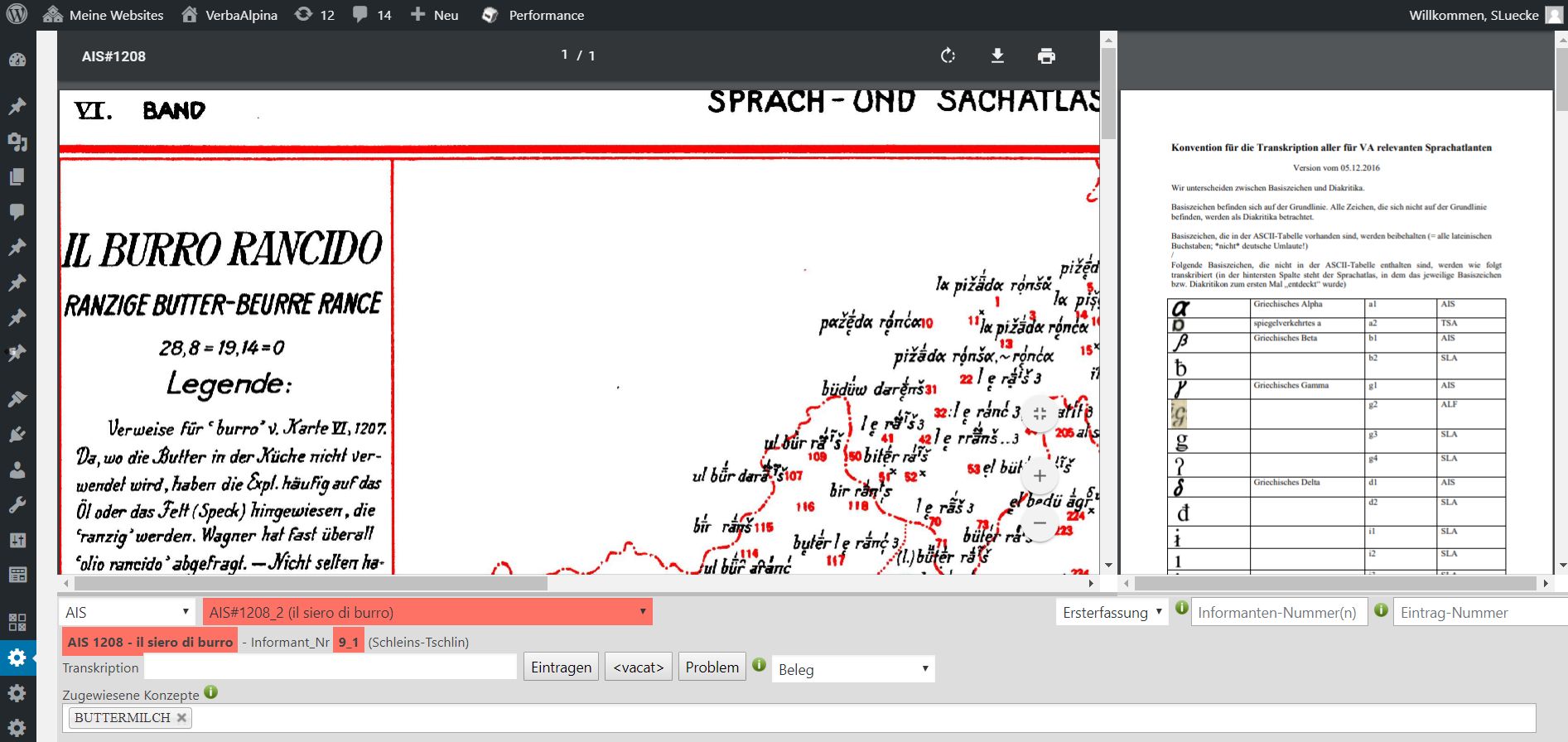
Das Transkriptionstool von VerbaAlpina
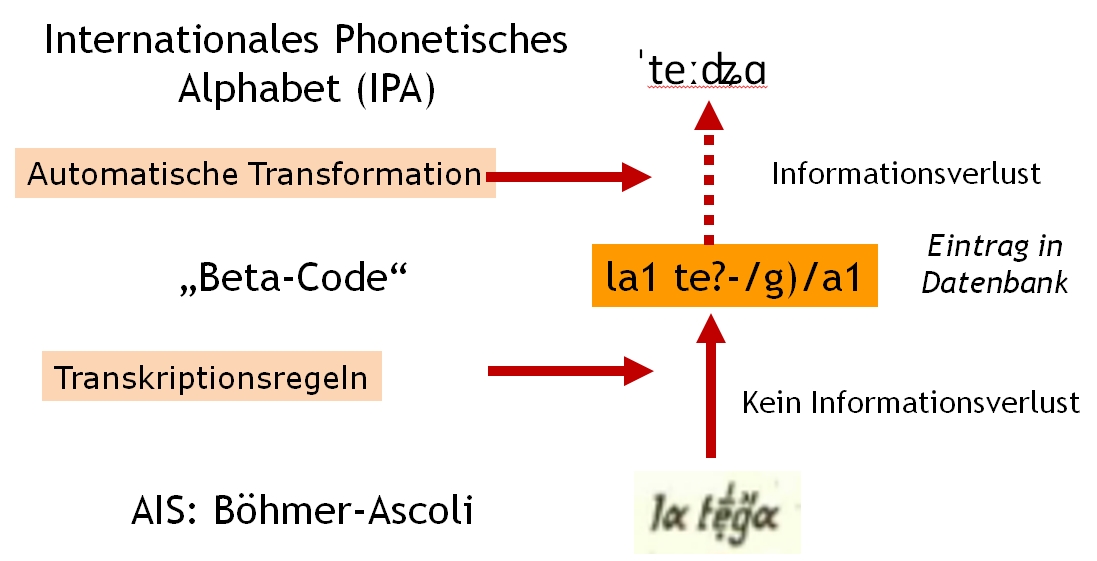
In einem Fensterausschnitt wird ein Bild einer Atlaskarte präsentiert. Unmittelbar darunter befindet sich ein Formular, das die strukturierte Erfassung der Kartendaten erlaubt bzw. auch erzwingt. Jeder Einzelbeleg auf der Karte wird unter Angabe des kartierten Stimulus und der Identifizierung des jeweiligen Informanten erfasst und direkt in einer Datenbanktabelle abgelegt. Die Transkription erfolgt im sog. Betacode, einem Verfahren, das auf eine Idee des Thesaurus Linguae Graecae (University of California Irvine) aus den Siebzigerjahren zurückgeht. Grundidee ist, beliebige Sonderzeichen samt Diacritica in Sequenzen von Standardzeichen (konkret: sog. ASCII-Zeichen) zu übertragen. Dabei werden Sonderzeichen und Diacritica nach einem simplen Schema in Abfolgen von Buchstaben des englischen Alphabets und geläufige Satz- und Sonderzeichen wie etwa runde Klammern oder Schrägstriche übertragen. Im Transkriptionstool wird dem Transcriptor auf der rechten Fensterseite das entsprechende Regelwerk eingeblendet.
Zur Herstellung von Vergleichbarkeit werden alle von VA erfassten phonetisch transkribierten Einzelbelege auf das Internationale phonetische Alphabet (IPA) abgebildet. IPA hat demnach innerhalb von VA den Status einer Referenztranskription. Bei der Überführung der quellentreuen Betacode-Transkription nach IPA kann es jedoch, unvermeidbar, zu Informationsverlusten kommen. Als Beispiel sei das Transkriptionssystem nach Böhmer und Ascoli genannt. Dieses unterscheidet durch Diacritica bei den Vokalen eine größere Anzahl von Öffnungsgraden des Mundes als IPA. Bei der Übertragung von Böhmer/Ascoli zu IPA müssen demnach Kompromisse eingegangen werden.
Die bei der Transkription verwendeten Zeichen sind ausnahmslos sogenannte ASCII-Zeichen. Dabei handelt es sich um Zeichen, die bereits im Jahr 1963 kodiert worden sind. Mit Kodierung ist dabei die Zuordnung der Schriftzeichen zu ganz bestimmten Zahlenwerten gemeint. Dies ist nötig, weil Computer nur mit Zahlen arbeiten können. Kodiert wurden insgesamt 128 Schriftzeichen, bei denen es sich hauptsächlich um die Buchstaben des englischen Alphabets, die arabischen Ziffern sowie um einige Satz- und Sonderzeichen handelt. Die damals festgelegte Kodierung ist bis zum heutigen Tage gültig. Anders als z.B. bei der Verwendung des moderneren Unicode ist die Gefahr des Entstehens von Kodierungsfehlern so gut wie ausgeschlossen. Allgemein bekannt dürfte folgendes Phänomen sein: Der deutsche Umlaut ü wird durch zwei sinnlose Zeichen dargestellt: Mühle ⇒ Mühle. Dergleichen ist bei Verwendung von ASCII-Zeichen ausgeschlossen.
Daneben bietet der Einsatz des Betacodes weitere Vorteile:
- Die Transkriptionen können unter Verwendung von Standardtastaturen durchgeführt werden
- Es ist unerheblich, ob ein Transkriptor die konkrete Bedeutung der von ihm erfassten Schriftzeichen kennt. Die Übertragung orientiert sich allein an der graphischen Gestalt der zu transkribierenden Zeichen.
- Die Transkription ist kaum anfällig für Tippfehler und erfolgt in vergleichsweise hoher Geschwindigkeit
- Die Transkription ist insofern quellentreu, als dabei keinerlei Informationsverlust auftritt – jedes Basiszeichen und jedes Diacriticum wird durch jeweils genau ein anderes Zeichen wiedergegeben.
Die von den gedruckten oder auch digitalen Quellen verwendeten Transkriptionssysteme sind sehr unterschiedlich. So kann ein und dasselbe graphische Zeichen, z.B. ein e mit einem Punkt darunter, durchaus unterschiedliche Laute bezeichnen. Um Vergleichbarkeit zu erzielen, werden sämtliche quellenspezifischen Transkriptionssysteme auf eine Referenztranskritption, nämlich IPA, abgebildet. Der entsprechende Vorgang erfolgt automatisch durch Ersetzungsprozeduren.
Die aus den unterschiedlichen Quellen, also im wesentlichen Sprachatlanten und Wörterbüchern, transkribierten Belege sind hinsichtlich ihres Status sehr heterogen. VerbaAlpina unterscheidet diesbezüglich im wesentlichen zwischen den folgenden Kategorien:
Einzelbeleg — morpholexikalischer Typ — Basistyp
Ein Einzelbeleg ist die mehr oder weniger unmittelbare und individuelle Äußerung eines Informanten. In Sprachatlanten ist sie meist daran erkennbar, dass sie in phonetischer Transkription und gebunden an einen spezifischen Informanten oder Erhebungspunkt gebunden ist.
Ein morpholexikalischer Typ (kurz: Morphtyp) sind am ehesten vergleichbar mit den Lemmata in traditionellen Wörterbüchern. Ein Morphtyp wird definiert durch die Zugehörigkeit zu einem jeweils gemeinsamen Wortstamm, Sprachfamilie, Wortart, Affigierung sowie Genus. Beispiel: Der Butter und die Butter bilden zwei unterschiedliche Morphtypen, da sie sich hinsichtlich des Genus unterscheiden.
Der Basistyp ist schließlich ein in unterschiedlichen Morphtypen erkennbares gemeinsames lexikalisches Element, ohne dass damit eine Aussage über die Entstehungsgeschichte des einzelnen Morphtypen getroffen werden würde. Vorstellbar in diesem Zusammenhang wären z.B. die Entstehung eines Morphtypen direkt aus einer sprachlichen Vorstufe am Ort im Sinne eines Etymons, jedoch kommen auch Entlehnungsszenarien im Umfeld von Sprachkontakt in Betracht. Als Beispiel können die beiden Morphtypen Salamander (ger.) und Salamandra (rom.) genannt werden. Beide enthalten erkennbar ein gemeinsames lexikalisches Element. Ob aber der eine Morphtyp sich aus dem anderen entwickelt hat oder beide auf einen gemeinsamen Vorläufer zurückgehen, lässt sich vor der Hand nicht entscheiden. Um dennoch die offenkundige Verwandtschaft der beiden Morphtypen im Datenbestand abbilden zu können, werden bei dem Basistypen "salamandra" zugewiesen. VerbaAlpina geht speziell diesen Fragen nicht systematisch nach, entsprechende spätere Erweiterungen und Ergänzungen sind jedoch jederzeit möglich.
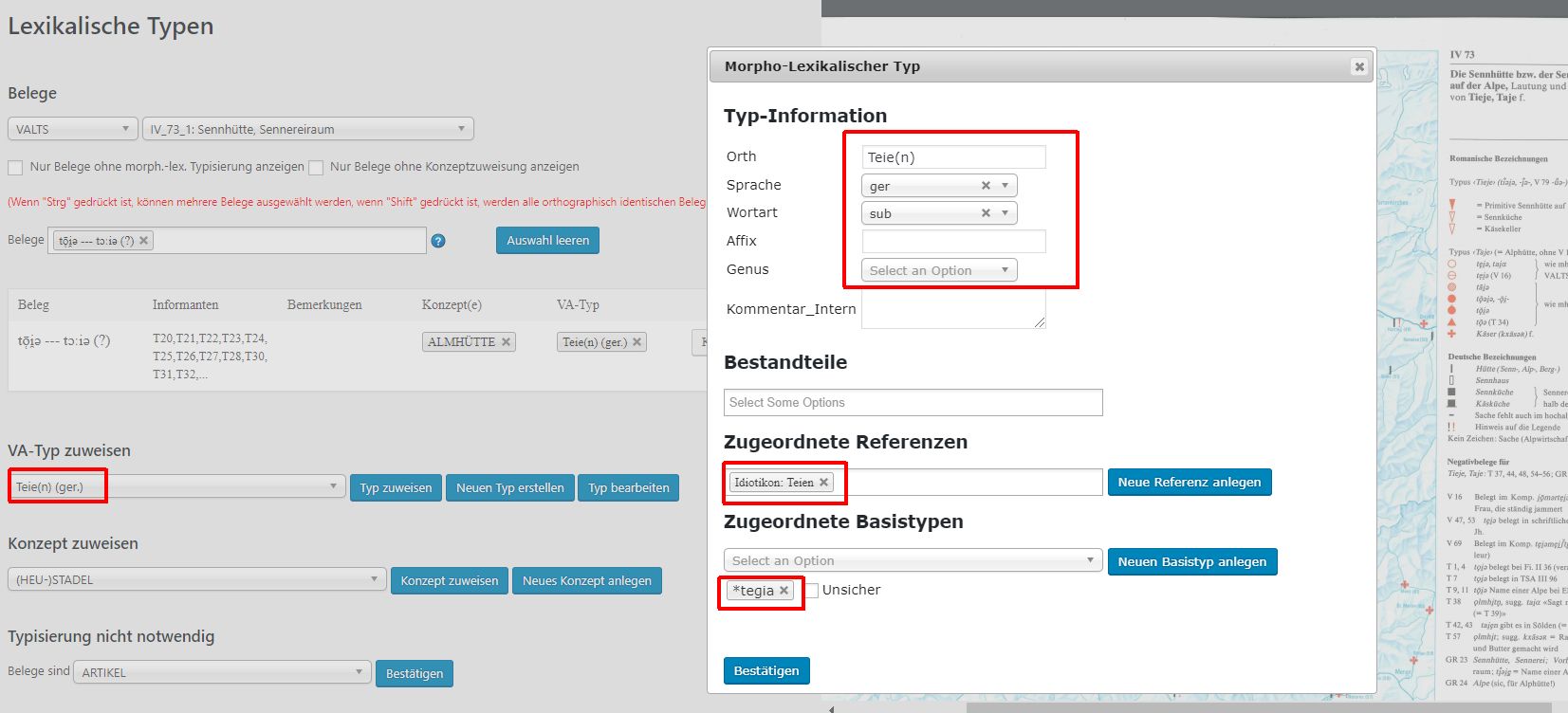
Gleichsam die Referenzkategorie für VerbaAlpina stellt der Morphtyp dar. Speziell für die Zuweisung der transkribierten Belege zu Morphtypen wurde in VerbaAlpina das sog. Typisierungstool entwickelt. Neben der Zuweisung zu Morphtypen erfolgt hier auch die Zuweisung zum jeweiligen Konzept, das laut Quelle von diesem Morphtyp bezeichnet wird.
Sofern möglich, können Morphtypen im Typisierungstool auch mit Lemmata in ausgewählten Referenzwörterbüchern verknüpft werden. Als Beispiel sei der Einzelbeleg tɔːiə aus dem Vorarlberger Sprachatlas (VALTS, Karte 73) genannt. Dieser ist über das Typisierungstool zunächst dem Morphtypen "Teie(n) – ger – sub" und dieser wiederum dem Lemma "Teien" im Schweizerdeutschen Wörterbuch, dem sog. Idiotikon, zugewiesen.
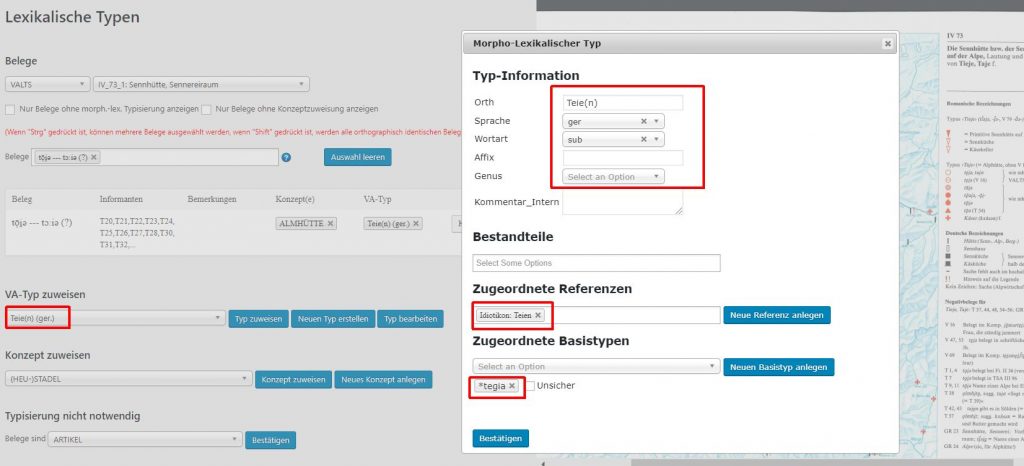
VerbaAlpina sieht grundsätzlich auch die Definition und Zuordnung von phonetischen Typen (z.B. Kas, Kaas -> Kaas vs. Kees, Käs -> Kees etc.) vor. Da das Projekt jedoch vorrangig morpholexikalisch ausgerichtet ist, liegt eine entsprechende Typisierung bislang erst lückenhaft vor. Derzeit (Juni 2018) stehen den 5446 morphologischen gerade einmal 646 phonetische Typen gegenüber.
Konzeptbaum
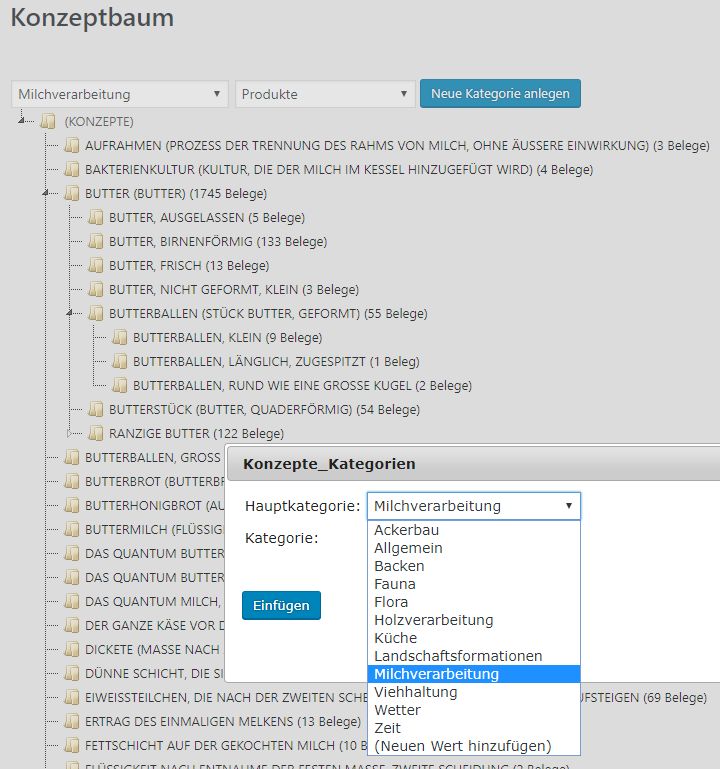
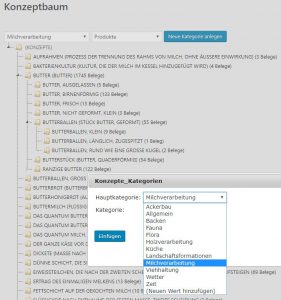
Ganz wesentlich für VerbaAlpina ist die außersprachliche Kategorie der Konzepte. Schließlich lautet die zentrale Frage: Welche Konzepte werden wo und wann mit welchen Morphtypen bezeichnet. Zur Verwaltung der Konzepte wurde von VA ein im Backend von VA_WEB zugängliches Tool entwickelt, das als Konzeptbaum bezeichnet wird.
Nach Aufruf des Tools muss zunächst eine der vorgegebenen Hauptkategorien (z.B. Milchverarbeitung) und anschließend eine Unterkategorie (z.B. Produkte) ausgewählt werden. Danach erscheint eine alphabetisch sortierte Liste aller bislang angelegten Konzepte. Die Elemente dieser Liste könnten durch Drag&Drop zu Unterkonzepten bestehender anderer Konzepte umgruppiert werden. Auch die Neuanlage von Konzepten ist hier möglich.
Forschungslabor (in Planung)
VerbaAlpina möchte sich u.a. zu einer Plattform entwickeln, auf der Forscher und Laien individuelle Studien betreiben und sich bzw. auch ihre Daten austauschen können. Das Konzept sieht vor, dass registrierte Benutzer nach dem Einloggen in VerbaAlpina eine persönliche Umgebung vorfinden, innerhalb derer sie zum einen das vorhandene VerbaAlpina-Datenmaterial nach individuellen Interessen analysieren und die Ergebnisse abspeichern können. Zum anderen soll es möglich sein, eigenes Material in das System zu importieren und dieses dann entweder isoliert oder auch in Kombination mit dem VerbaAlpina-Material zu verarbeiten.
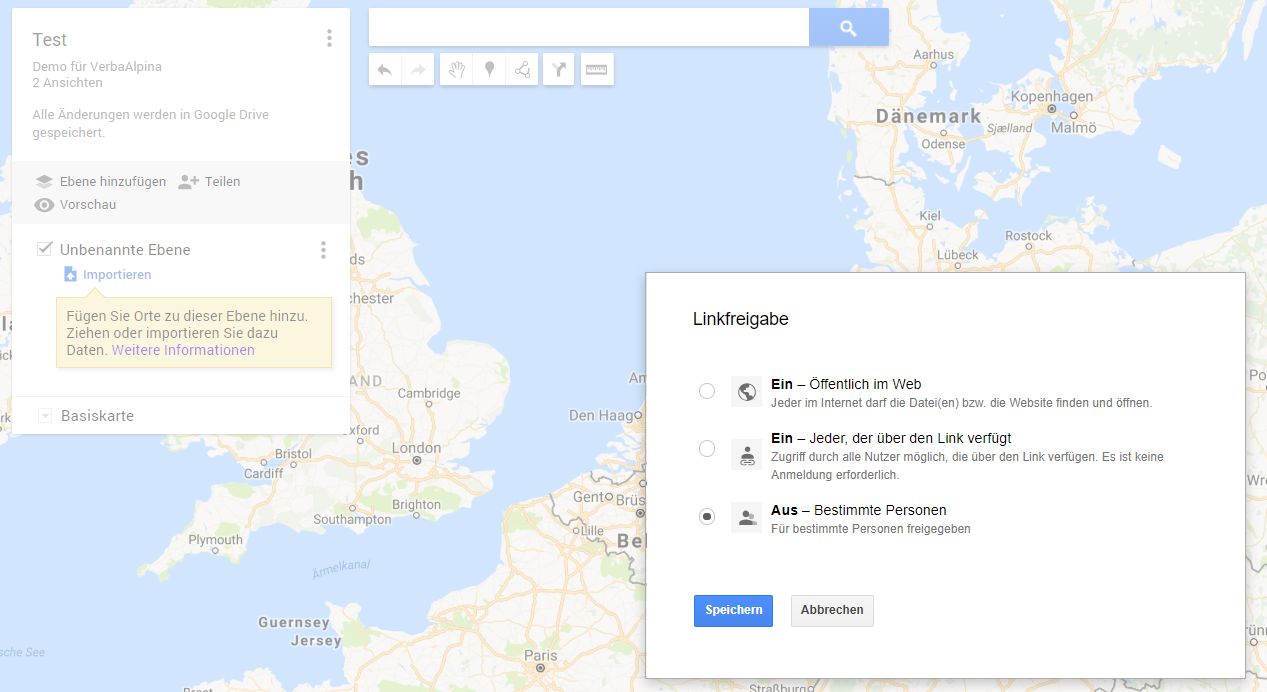
So wie nunmehr schon in vielen Internet-Diensten etabliert, soll es die Möglichkeit geben, Daten und Analyseergebnisse für den Zugriff durch Dritte freizugeben. Diese Freigabe soll mehrere Optionen anbieten: Freigabe für spezifische andere registrierte Benutzer von VerbaAlpina, Freigabe für alle registrierten Benutzer von VA und schließlich die unbeschränkte Freigabe von Daten im Internet. Das Konzept orientiert sich grob am von Google eingesetzten Verfahren im Zusammenhang mit von Nutzern erstellten Karten auf Google Maps.
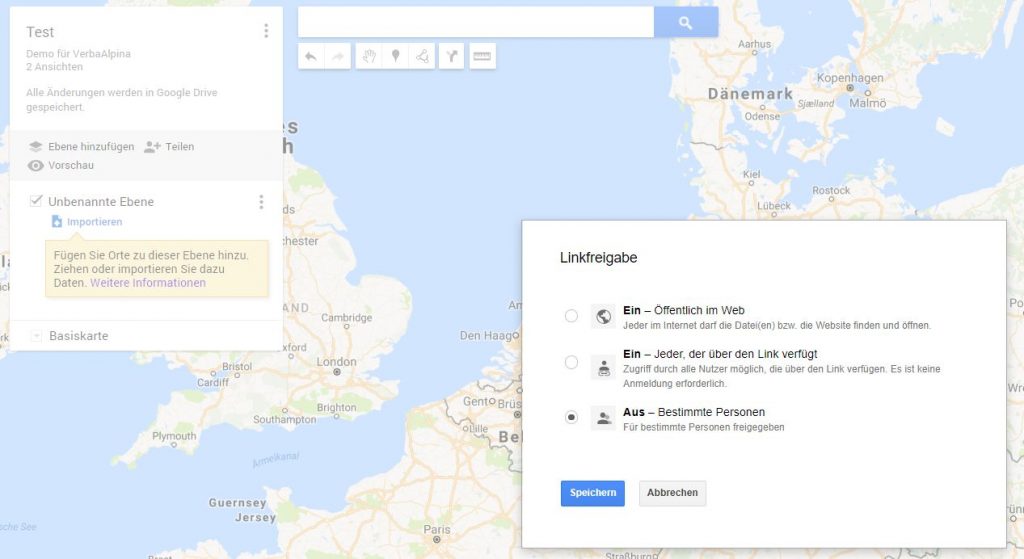
Das Konzept ist bislang erst in Ansätzen realisiert. Ein solcher Ansatz besteht in der Möglichkeit, auf der interaktiven online-Karte von VerbaAlpina durch die Auswahl beliebiger sprachlicher und außersprachlicher Datenkategorien erzeugte Kartenbilder als "synoptische" Karten abzuspeichern. Diese Funktion steht aktuell nur registrierten Benutzern zur Verfügung. Beim Abspeichern einer Karte besteht die Möglichkeit, einen Kommentar beizufügen, der den Informationsgehalt der Karte erläutern soll. Für eine erstellte synoptische Karte kann eine Freigabe beantragt werden. Diese erfolgt dann erst nach einer qualitätssichernden Überprüfung durch das Team von VerbaAlpina. Bei künftig verstärkter Nutzung dieser Möglichkeiten wird man über alternative Konzepte zur Qualitätssicherung nachdenken müssen. Vorstellbar sind z.B. Bewertungen durch die Nutzergemeinde von VerbaAlpina.
Im Forschungslabor könnte auch ein Modul zur statistischen Analyse der VerbaAlpina-Korpusdaten eingerichtet werden. An den Instituten für Statistik und Kunstgeschichte wird zur Zeit ein System entwickelt, bei dem es um die statistische Analyse von Museumsbeständen geht. Das Konzept von MAX (Museum Analytics; https://www.max.gwi.uni-muenchen.de/; ein von der LMU im Rahmen des "Qualitätspakts Lehre" gefördertes Projekt) beinhaltet auch das Szenario, dass Anwender im Grunde beliebige Daten z.B. im csv-Format in das System importieren, um es dort mit vorgefertigten Verfahren statistisch zu analysieren. Künftig sollen die im Rahmen von MAX entwickelten Funktionalitäten in das Forschungslabor von VerbaAlpina integriert werden.
Funktionen des Frontends
Methodologie
In der Rubrik Methodologie erfolgt eine ausführliche Methodenreflexion. Hier sollen alle mit VerbaAlpina verbundenen Aspekte transparent und nachvollziehbar dokumentiert werden. Der Inhalt ist nach Schlagworten gegliedert, die wiederum thematischen Kategorien zugeordnet sind. Hier werden neben grundlegenden Konzepten des Gesamtprojekts auch spezifisch linguistische oder auch informatisch-technische Detailaspekte erläutert. Die Einträge in dieser Rubrik werden ständig erweitert oder nötigenfalls auch überarbeitet und angepasst. Die Methodologie spielt eine wichtige Rolle im Hinblick auf das Erfordernis der Nachhaltigkeit und Nachnutzbarkeit aller von VerbaAlpina gesammelten und erzeugten Daten. Der Anspruch besteht, dass sämtliche Teile des Gesamtprojekts, seien es die Sprachdaten in der VA_DB, die sprachwissenschaftlichen Kommentare und (mit gewissen Einschränkungen) auch der erzeugte Software-Code auch noch nach Jahrzehnten nutzbar sein werden.
Interaktive Online-Karte
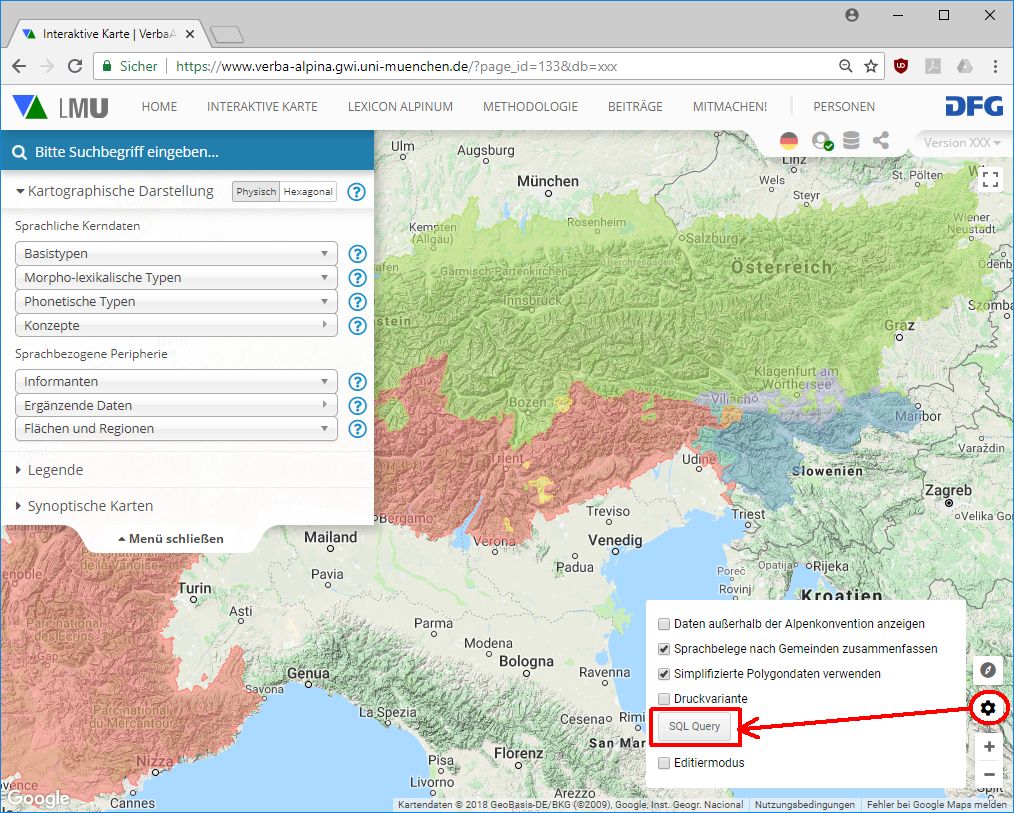
Die interaktive Online-Karte von VA ist das zentrale Visualisierungs- und Analyseinstrument. Aktuell basiert die Karte auf Google-Technologie, konkret auf dem Online-GIS Google Maps und der entsprechenden Javascript-Bibliothek. VerbaAlpina ist im Grunde der Überzeugung, dass der Einsatz von Diensten kommerzieller Anbieter im wissenschafftlichen Umfeld generell vermieden werden sollte. Speziell im Fall der online-Kartographie führt derzeit jedoch kaum ein Weg an Google Maps vorbei. Das Opensource-Projekt Openstreetmap (OSM), das grundsätzlich eine Alternative darstellen könnte, kann hinsichtlich Funktionalität und, was fast noch wichtiger ist, hinsichtlich der Dokumentation mit dem Google-Dienst nicht mithalten. Bei Einsatz von Openstreetmap hätte sehr wahrscheinlich der aktuelle Entwicklungsstand der online-Karte von VerbaAlpina nicht in derselben Zeit erreicht werden können. Grundsätzlich wäre eine Umsetzung der online-Karte auf OSM rein technisch wohl möglich. Sollten in Zukunft Verbesserungen bei OSM festzustellen sein, die einen Umzug vertretbar erscheinen lassen, so wäre ein solcher Schritt durchaus vorstellbar. VerbaAlpina behält diese Perspektive jedenfalls im Auge.
Das Karteninterface erlaubt wahlweise oder auch kombiniert semasiologischen und/oder onomasiologischen Zugriff auf den Datenbestand. Nachfolgend stehen unterschiedliche Gruppierungsoptionen zur Verfügung.
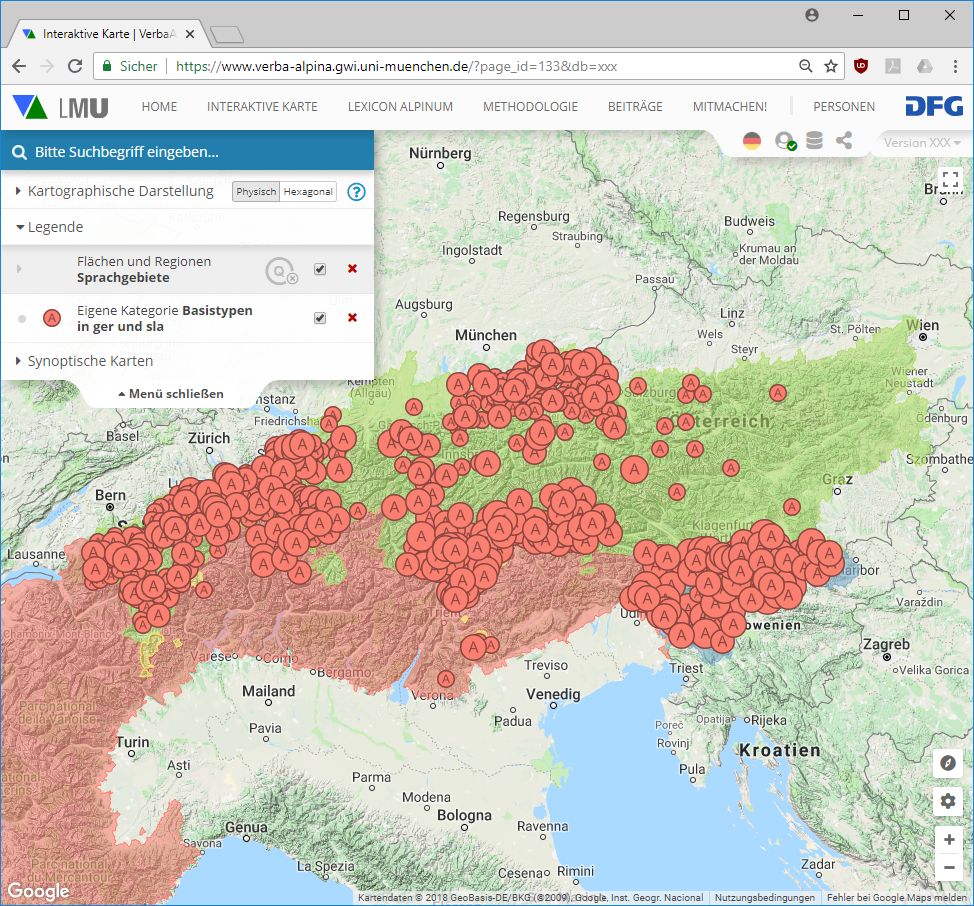
Qualitative Kartierung
Über die Legende am linken Rand der Karte können Konzepte, phonetische oder morpholexikalische Typen oder auch ausgewählt werden. Seit kurzem steht auch eine Suchfunktion zur Verfügung, die sämtliche auswählbare Listeneinträge durchsucht, unabhängig von deren Kategorisierung als "Konzept", "Morphtyp" usw. Nach Auswahl eines verfügbaren Elements erscheinen die entsprechenden Symbole auf der Karte.
Neben Sprachdaten können auf der Karte synoptisch auch georeferenzierte Daten der "sprachbezogenen Peripherie" visualisiert werden. Darunter werden unterschiedlich Kategorien von Daten verstanden, die mit sprachlichen Phänomenen in der einen oder anderen Weise in Wechselwirkung stehen können. Dies können z.B. historische Daten wie etwa Daten zu antiken Besiedlungsstrukturen und Verkehrswegen, entlang derer sich sprachliche Phänomene verbreitet haben könnten, oder auch Daten zur modernen Infrastrukutur wie etwa zur Verbreitung der Internetanschlüsse im Alpenraum sein, die sicherlich Auswirkungen auf sprachliche Veränderungsprozesse haben. Die Daten dieses Sektors sind bislang noch nicht systematisch gesammelt worden.
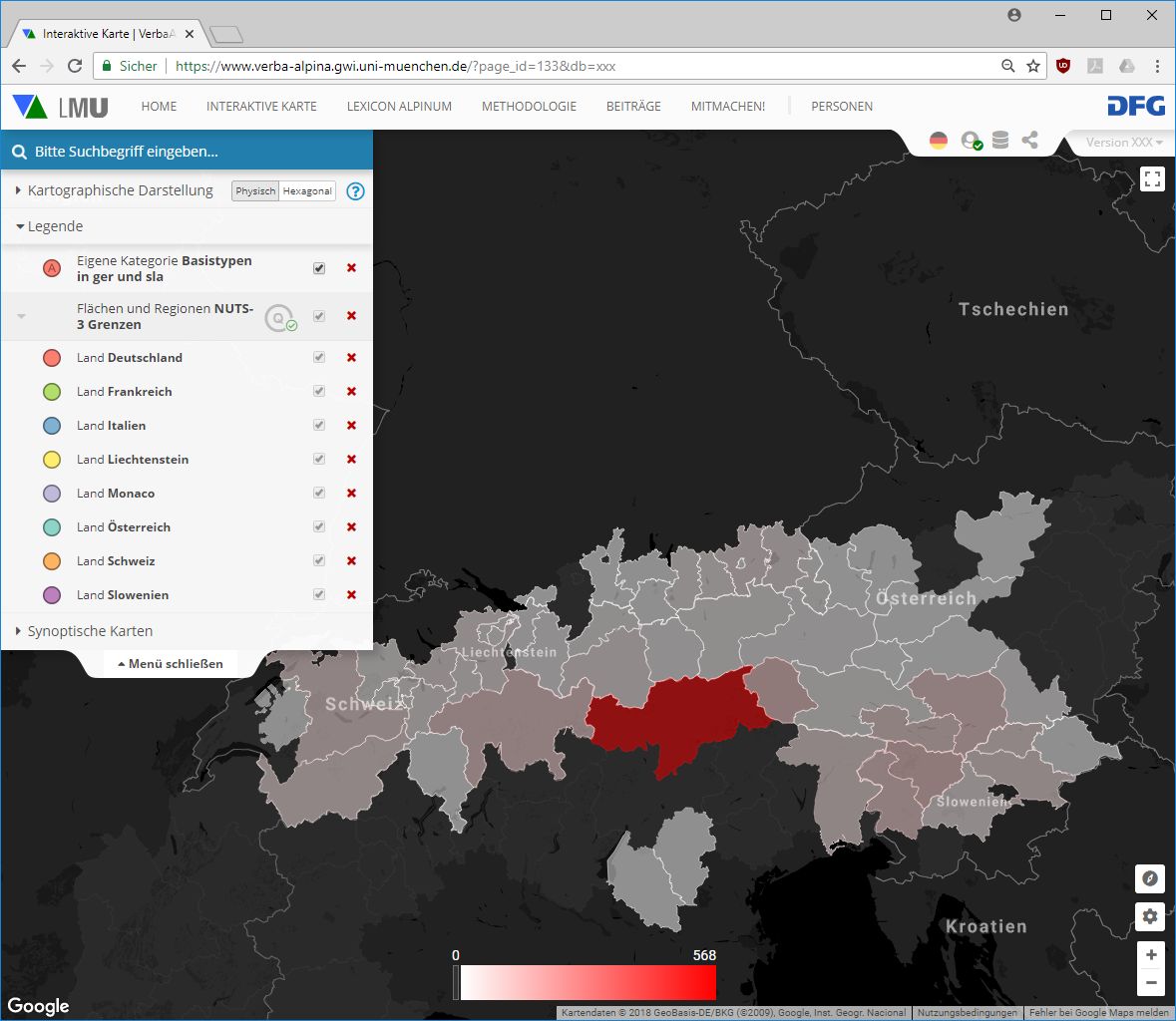
Quantifizierende Darstellung
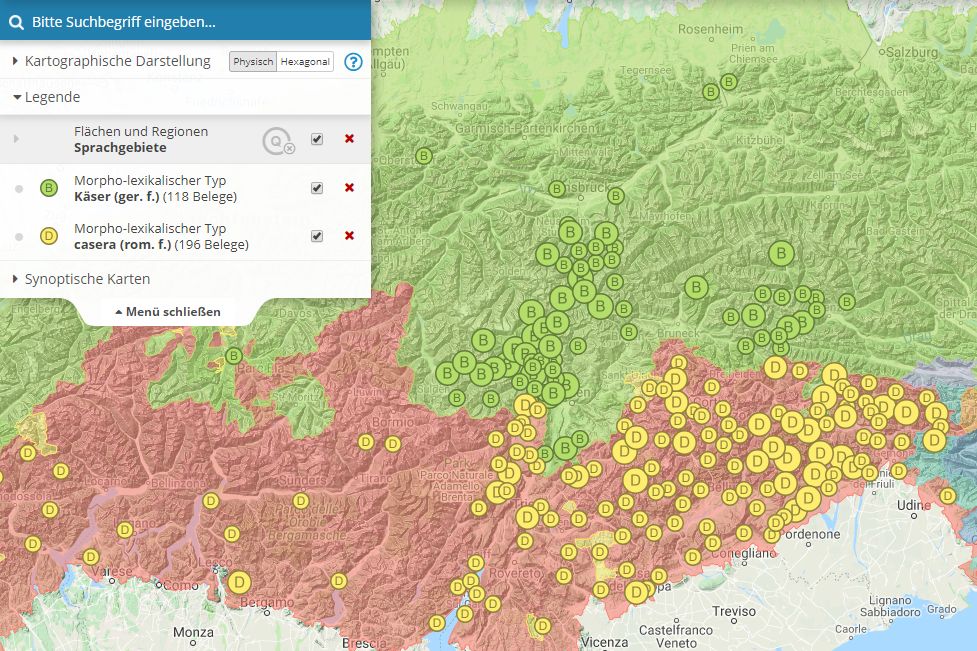
Die online-Karte erlaubt auch eine quantifizierende Abbildung der auf einer Karte dargestellten Inhalte. Im folgenden Beispiel ist zunächst die nach jeweiliger Bedeutung (Konzepten) gruppierte Verbreitung des Morphtyps "Teie(n)" kartiert:
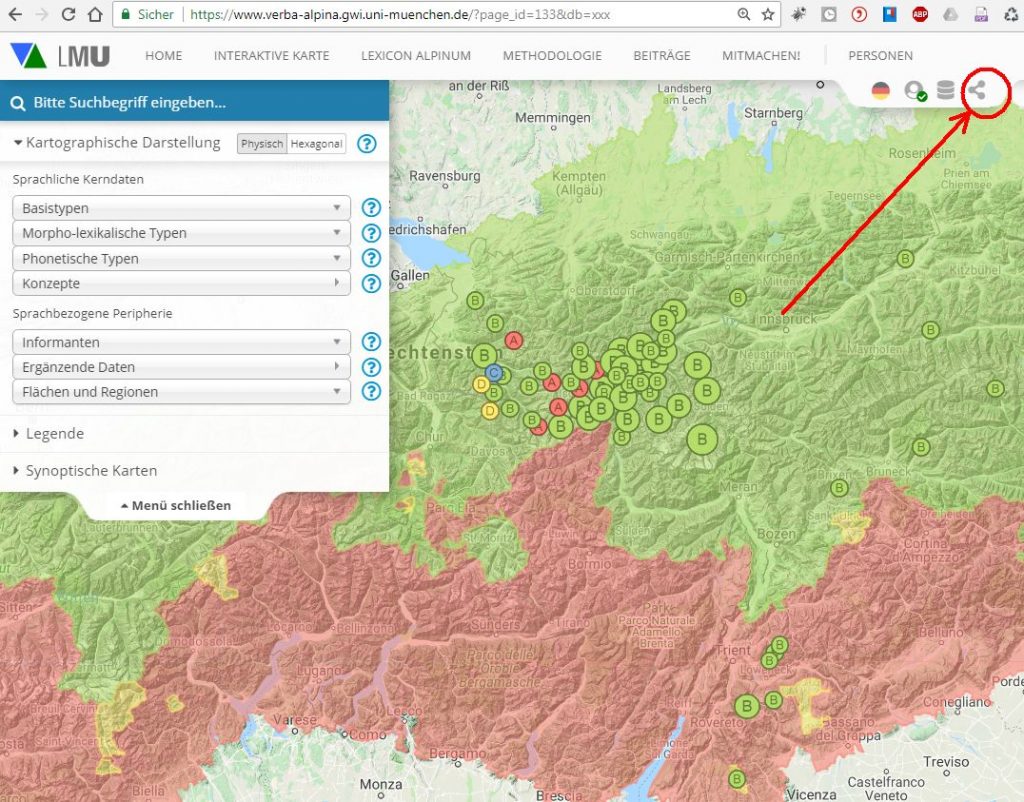
Qualitative Kartierung des Morphtyps "Teie(n)"
Die hier abgebildete Karte ist mit dem Link https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=xxx&tk=1357 hinterlegt. Die hinter dem Fragezeichen folgenden, rot gesetzten sog. URL-Parameter bewirken, dass die interaktive Onlinekarte mit der gewünschten Vorauswahl "Morpho-lexikalischer Typ Teie(n) (ger.)" aufgerufen wird. Ein solcher Link kann für Karten mit der Kartierung beliebiger Elemente (Morphtypen, Konzepte, sprachbezogene Peripherie ...) abgerufen werden, indem man am oberen rechten Rand der Karte das allgemein bekannte Sharing-Symbol anklickt.
Die quantifizierende Darstellung dieser Daten orientiert sich an Flächen bzw. administrativen Regionen, d.h. es wird die jeweilige Anzahl von Belegen pro Teilfläche des gewählten Bezugssystems durch unterschiedliche Farbgebung markiert.
Im Wesentlichen kann zwischen den folgenden verschiedenen Bezugssystemen gewählt werden:
- Sprachgebiete
- Nationalstaaten
- NUTS3 (= administrative Gliederung auf Niveau der deutschen Landkreise)
- Gemeindegrenzen
Die quantifizierende Kartierung setzt die Auswahl mindestens einer dieser Kategorien voraus. Sobald ein entsprechender Eintrag in der Kartenlegende auf der linken Seite vorhanden ist, kann man dort auf das von einem Kreis umgebene Q klicken. Anschließend werden die Daten gemäß den Teilflächen der gewählten Kategorie gruppiert und die gruppenbezogene Anzahl durch Farbgebung der Flächen visualisiert.
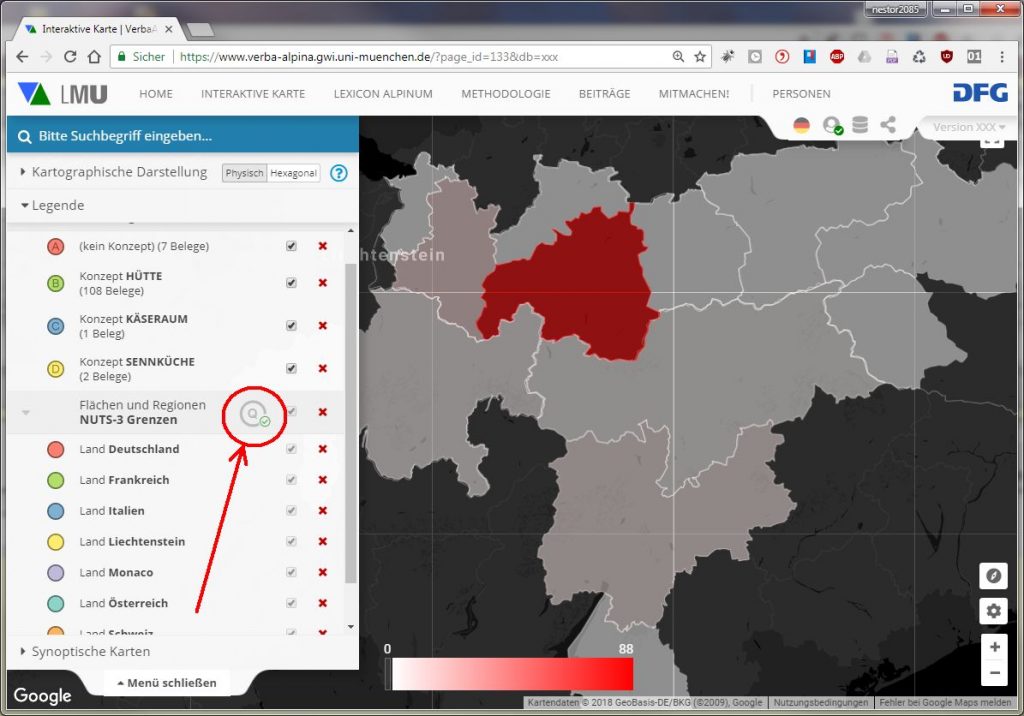
Quantifizierende Darstellung der Verbreitung des Morphtyps "Teie(n)" mit georefrenziertem Verlauf der NUTS3-Grenzen
Im Legendeneintrag "Kartographische Darstellung" lässt sich sodann noch wählen zwischen den Optionen "Physisch" und "Hexagonal". Erstere, im vorstehenden Beispiel angewendete, Option verwendet den tatsächlichen, geographisch exakt kartierten Grenzverlauf der entsprechenden Teilflächen. Bei Auswahl der Option "Hexagonal" wird jede Teilfläche durch Hexagone jeweils identischer Größe repräsentiert. Diese Art der Darstellung soll die Wahrnehmung verzerrende Effekte beseitigen, die sich durch die z.T. stark unterschiedliche Flächengrößen ergeben können.
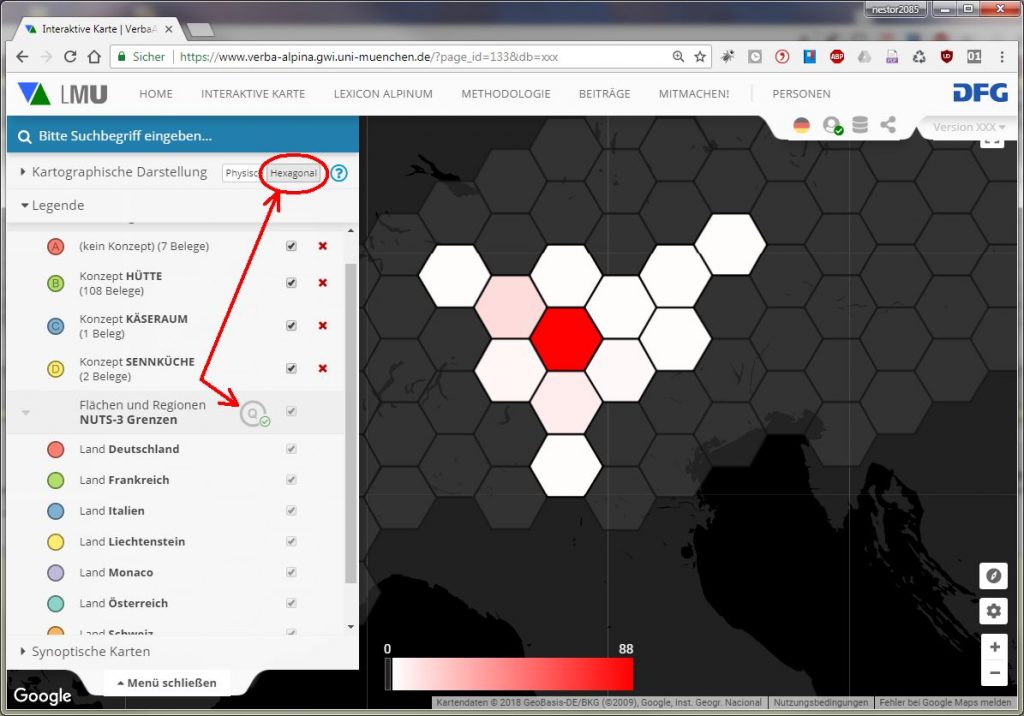
Quantifizierende Darstellung der Verbreitung des Morphtyps "Teie(n)" mit hexagonaler Darstellung der Bezugsflächen
Bei dieser Darstellung gehen konzeptbedingt Teile der geographischen Logik verloren. Im Inneren des Wabenmusters hat jede Fläche stets genau sechs Nachbarhexagone. Es liegt auf der Hand, dass es in der Realität nicht wenige Teilflächen geben wird, die entweder mehr oder weniger Nachbarflächen aufweisen.
Am unteren Rand der quantifizierenden Karten kann die Farbgebung der Flächen verändert werden (u.a. die verbreitete Heatmap, die den Verlauf der Regenbogenfarben verwendet). Die bei dem Balken für die Farbauswahl an der rechten oberen Ecke angegebene Zahl gibt die Anzahl der Belege an, die in der Fläche mit der maximalen Anzahl an Belegen versammelt sind, und hilft somit bei der Einschätzung der Anzahlen in den schwächer eingefärbten Flächen.
Die einzelnen Elemente in der Kartenlegende auf der linken Seite können durch Entfernen oder Setzen des kleinen Häkchens in die Berechnung und Visualisierung der Daten auf der Karte einbezogen oder herausgenommen werden. Bei jeder solchen Aktion wird die Kartendarstellung entsprechend aktualisiert.
Lexicon Alpinum
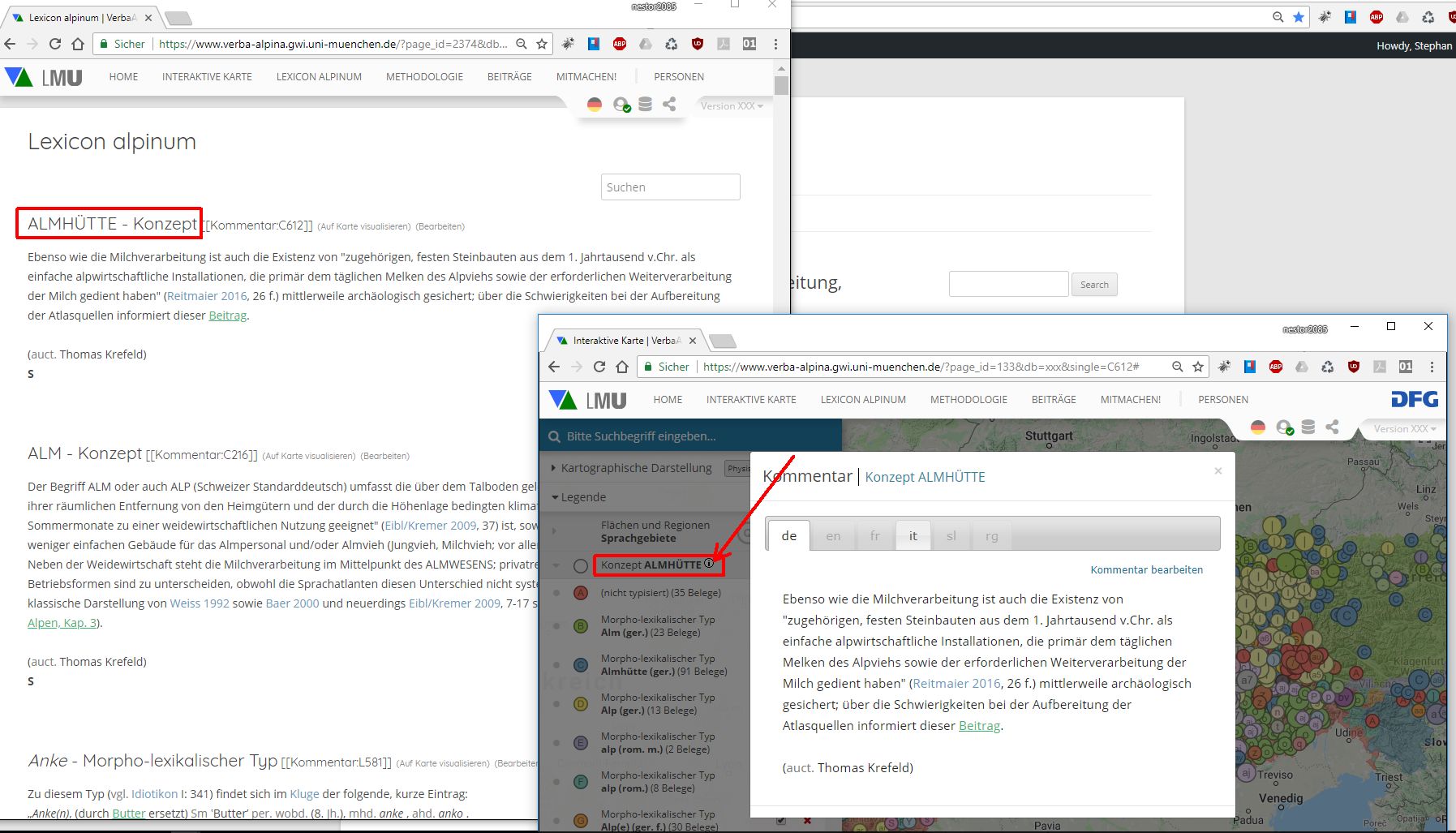
Das Lexicon Alpinum enthält eine alphabetisch sortierte Liste mit Morphtypen, Konzepten und Basistypen, zu denen bislang ein wissenschaftlicher Kommentar verfasst worden ist. Hinter jedem Eintrag ist angegeben, ob es sich um ein Konzept, einen Morph- oder einen Basistyp handelt. Konzepte sind außerdem, wie auch in der Legende der Onlinekarte, an der Schreibung in Versalien erkennbar. Über den Link "Auf Karte visualisieren" gelangt man zur Online-Karte, auf der dem Lexikoneintrag zugeordnete Daten dargestellt werden.
Die im Lexicon Alpinum gelisteten Kommentare können auch über die Online-Karte aufgerufen werden. Sofern für einen bestimmten Legendeneintrag auf der Online-Karte ein Kommentar vorhanden ist, erscheint unmittelbar rechts von diesem Eintrag ein kleines i in einem Kreis. Ein Klick auf dieses Symbol öffnet den Kommentartext, der auch im Lexicon Alpinum präsentiert wird.
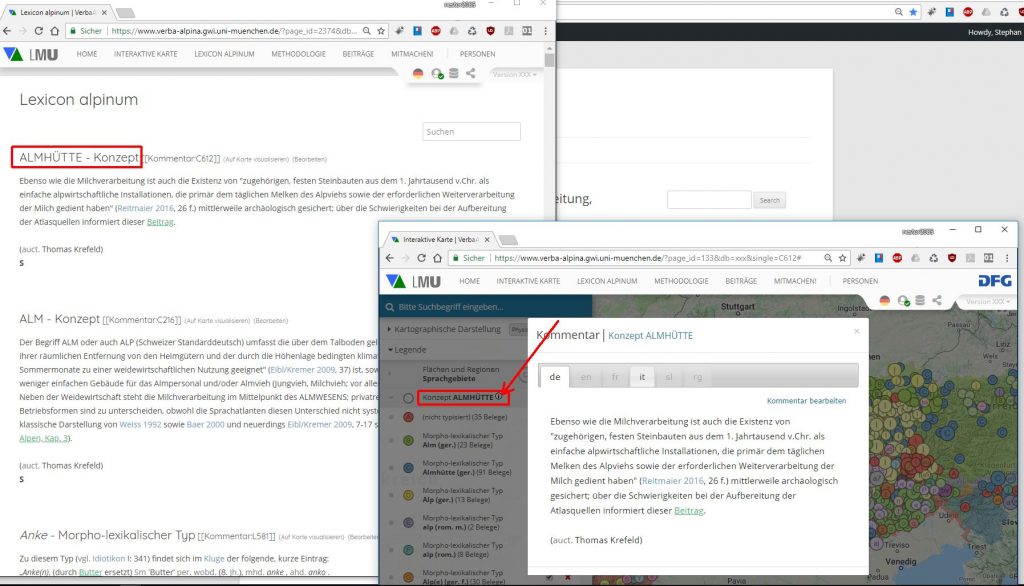
Kommentar zum Konzept ALMHÜTTE im Lexicon Alpinum und auf der Online-Karte
Crowdsourcing: Dateninkonsistenzen und deren Ausgleich
Dadurch dass die Hauptquellen von VA, nämlich Sprachatlanten und Wörterbücher, bezogen auf den gesamten Alpenraum durchaus unterschiedliche Konzepte und in der Folge auch Bezeichnungen dokumentiert haben, entsteht bei der Sammlung des Gesamtmaterials ein mehrdimensionales Netz mit einer Reihe von Inkonsistenzen. Die Mehrdimensionalität entsteht dabei im Wesentlichen durch die Variablen Georeferenz, Chronoreferenz und Konzept. So ist es z.B. möglich, dass ein bestimmter Sprachatlas zu einem bestimmten Zeitpunkt in einer bestimmten Region das Vokabular für ein bestimmtes Konzept erhoben hat. Für andere Regionen fehlen hingegen entsprechende Erhebungen entweder vollständig oder aber wurden zu einem erheblich früheren oder späteren Zeitpunkt durchgeführt. Um Inkonsistenzen dieser Art wenigstens im Hinblick auf die Konzept- und geographische Dimension auszugleichen, hat VA ein Crowdsourcing-Tool entwickelt, mit dem über das Internet gezielt Sprachmaterial gesammelt wird. Auch dieses Tool ist über das Frontend von VA_WEB erreichbar (Reiter "MITMACHEN!").
Konkret werden Internetuser dazu aufgefordert, Bezeichnungen für bestimmte Konzepte, die nach ihrer Ansicht an einem bestimmten Ort üblich sind, in ein online-Formular einzutragen. Das Tool hebt dabei bestimmte Konzepte, die aus Sicht von VerbaAlpina von besonderem Interesse sind, hervor. Grundsätzlich sind die Internetuser jedoch frei, auch Bezeichnungen für beliebige Konzepte ihrer Wahl einzutragen.
Die Validierung der Eintragungen erfolgt nach dem Prinzip der unabhängigen Quellen: Wenn zwei oder mehr Internet-Informanten für einen Ort die selbe Bezeichnung für ein bestimmtes Konzept eingegeben haben, gilt der Eintrag als validiert.
Ein großes Problem dieser Form der Online-Erhebung ist die Resonanz. Jeweils nach der Bewerbung des Crowdsourcing-Tools auf Veranstaltungen oder in den Medien steigt die Zahl der Eintragungen ins System an, ebbt jedoch jedesmal schnell wieder ab.
Jenseits von VA_DB und VA_WEB: Der weitere Horizont
Institutionelle Vernetzung
VerbaAlpina versteht sich als Teil eines Daten- und institutionellen Verbundes. Derzeit (Mai 2018) haben insgesamt über 40 Institutionen und Einzelpersonen mit VerbaAlpina eine Kooperationsvereinbarung geschlossen. Die einzelnen Partner sind hinsichtlich ihrer wissenschaftlichen Ausrichtung und ihren spezifischen Interessen überaus heterogen. Viele der Partner verfügen wie VerbaAlpina über Sprachmaterial, das in aller Regel hinsichtlich Strukturierung und Zeichenkodierung sehr individuell gestaltet ist.
Wesentlicher Bestandteil der VA-Kooperationsvereinbarungen ist der wechselseitige Austausch von Daten zum gegenseitigen Nutzen. Grundsätzlich kommen in diesem Zusammenhang zwei Szenarien ins Spiel, die den effektiven Datenaustausch überhaupt erst ermöglichen:
Entweder, man verständigt sich auf Standards (gleichermaßen für Datenstrukturen wie für Zeichenkodierung), die von allen Beteiligten angewandt werden, oder man folgt einem Schnittstellenkonzept, das es den Projektpartnern erlaubt, ihre individuellen Lösungen beizubehalten. Letztere Option ist die von VerbaAlpina favorisierte Lösung. Bei jedem Datentransfer von der oder in die Datenbank von VerbaAlpina (VA_DB) muss eine eigene Prozedur entwickelt werden, die die Daten der Quelle an die Strukturen und Kodierungen der Zielinstanz anpasst bzw. sie in diese überführt.
Nach außen hin verfügt VerbaAlpina neben der Webschnittstelle mit der Kartenfunktion über eine definierte Datenbankschnittstelle. Diese ist nur für die Kooperationspartner von VerbaAlpina zugänglich. Sämtliches georeferenziertes Sprachmaterial sowie die, ebenfalls georeferenzierten Daten der sprachlichen Peripherie können in Datenbanktabellen konsultiert und von dort auch heruntergeladen werden. Der Name der Datenbankschnittstelle für die Sprachdaten lautet vap_ling_de, der für die Daten der sprachlichen Peripheri vap_geo_de.

Schnittstelle vap_ling_de (Ausschnitt)
Schnittstelle vap_geo_de (Ausschnitt)
Für jede der beiden Tabellen existieren weitere Versionen mit Spaltennamen in den im Alpenraum gesprochenen Nationalsprachen (vap_ling_fr, vap_ling_it, vap_geo_fr etc.). Die Daten der beiden Schnittstellen sind über die Georeferenzierung aufeinander beziehbar.
VerbaAlpina als vollständig "digitales" Projekt
VerbaAlpina möchte den Paradigmenwechsel, der sich durch Digitalisierung und Vernetzung ergeben hat, so konsequent wie möglich umsetzen. Dazu gehört im Wesentlichen, dass das Projekt in all seinen Teilen ausschließlich elektronisch realisiert wird und im Internet zugänglich ist. Die Vorteile bestehen dabei in den Möglichkeiten der erweiterten algorithmischen und statistischen Analyse des Datenbestands, der Beschleunigung aller Prozesse, der weitgehenden Unabhängigkeit von kommerziellen Institutionen wie z.B. Wissenschaftsverlagen sowie der ständigen Verfügbarkeit aller Daten und Funktionen unabhängig von Ort und Zeit.
Den genannten Vorteilen stehen auf der anderen Seite Probleme oder besser: Herausforderungen gegenüber. Diese bestehen zunächst in der "Flüchtigkeit" des elektronischen Mediums, eine Eigenschaft, die eine Reihe von Konsequenzen nach sich zieht. Da wäre zunächst das Problem der Zitierbarkeit elektronischer Ressourcen. Einmal generierte Daten, seien es primäre Forschungsdaten wie etwa das von VerbaAlpina in VA_DB gesammelte Datenmaterial, seien es die analytischen Texte etwa im Lexicon Alpinum, sie alle müssen genauso zuverlässig zitier- und in der Folge vor allem auffindbar sein, wie das ehedem beim Zitat einer Passage in einem gedruckten Buch der Fall gewesen war. Um dieses Ziel zu erreichen, bedient sich VerbaAlpina des Konzepts der Versionierung: In regelmäßigen Abständen (seit 2018 jeweils Ende Juni und Ende Dezember) wird der komplette Datenbestand von VerbaAlpina, also alle Elemente in den Modulen VA_DB und VA_WEB gleichsam eingefroren. Sämtliche Elemente einer eingefrorenen Version können dann über die bekannten URLs direkt angesprochen werden, wobei die jeweilige Nummer der entsprechenden VA-Version als Parameter "db=[Versionsnummer]" in die URL eingebunden ist. Zwei Beispiele:
Zitat eines Kommentars im Lexicon Alpinum:
Krefeld, T.: s.v. “ALM”, in: VA-de 17/2, Lexicon alpinum, https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=2374&db=172#C216
Zitat einer online-Kartierung:
https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=172&tk=1373
Die unterschiedlichen Zitierversionen können in VA_WEB durch die Navigationselemente am rechten oberen Fensterrand ausgewählt werden:
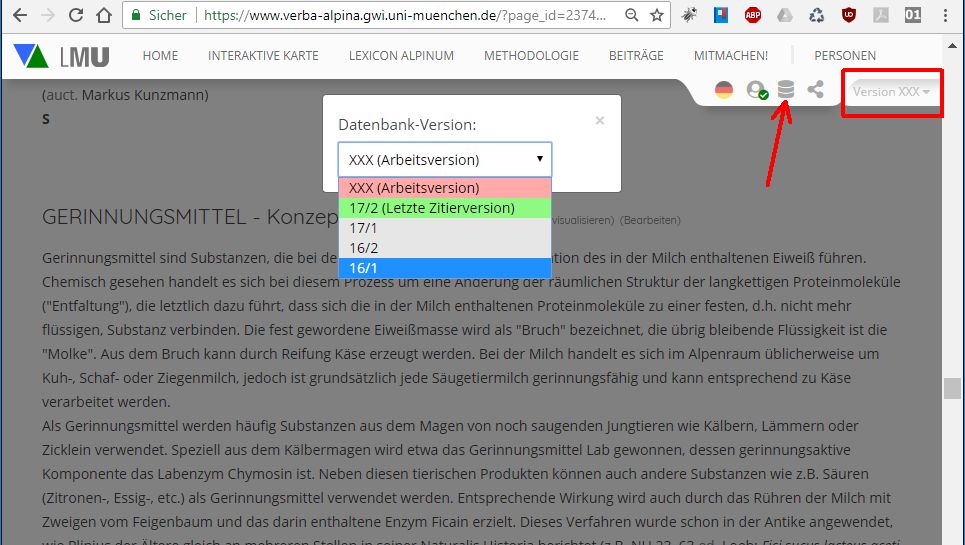
Auswahl einer VA-Version in VA_WEB. Die jeweils jüngste Zitierversion ist grün unterlegt.
Zitierfähig ist im Grunde auch die jeweilige Arbeitsversion von VerbaAlpina (db=xxx). Allerdings kann in diesem Fall nicht garantiert werden, dass die Inhalte, auf die referiert wird, stabil sind. Die ständige Erweiterung des Datenbestands sowie die Arbeit an Texten kann dazu führen, dass bei Aufruf einer entsprechenden URL nicht die Inhalte angezeigt werden, auf die es bei Anlage des Zitats angekommen war.
Zwar ist Dergleichen nicht geplant, jedoch kann es nicht ausgeschlossen werden, dass in Zukunft die sog. "Domain" der VerbaAlpina-URLs geändert werden muss. Mit Domain ist der Teil einer URL gemeint, der sich vor den URL-Parametern befindet:
https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=2374&db=xxx
Damit die Ressourcen von VerbaAlpina auch denn noch auffindbar sein werden, wurden für die VerbaAlpina-Domain sowohl ein sogenannter Digital Object Identifier (DOI) sowie ein sogenannter Uniform Resource Name (URN) registriert. Bei diesen beiden Systemen handelt es sich im Grunde um nichts anderes als Listen, die auf der einen Seite einen persistenten Identifikator definieren und auf der anderen Seite die diesem Identifikator zugeordnete Domain. Der Identifikator bleibt grundsätzlich unter allen Umständen unverändert, die Domain hingegen ist variabel und kann ausgetauscht werden, wenn eine Ressource unter einer anderen Domain erreichbar sein sollte. DOI und URN von VA_WEB lauten:
Eine andere wichtige Frage ist, welche Institutionen für die rein physische Bewahrung der Daten und deren Auffindbarkeit zuständig sein sollen. Thomas Krefeld und Stephan Lücke haben zu diesen Fragen Vorstellungen entwickelt, die durch die folgende Grafik illustriert werden:
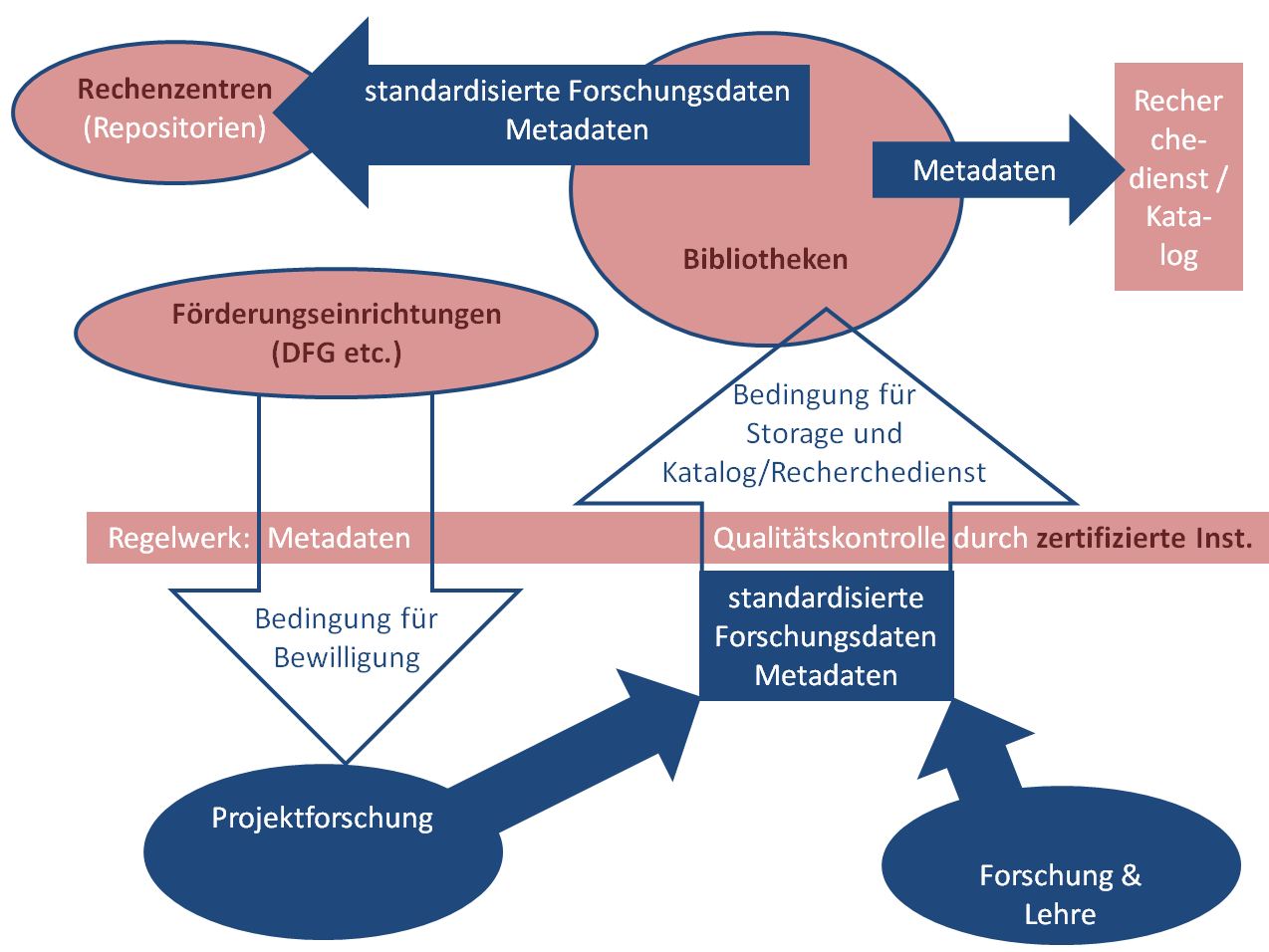
Zuständigkeiten und Regelungen im Kontext der Bewahrung digitaler Ressourcen (aus: Thomas Krefeld & Stephan Lücke (2017): Nachhaltigkeit – aus der Sicht virtueller Forschungsumgebungen. Korpus im Text. Version 7 (10.03.2017, 12:27). url: http://www.kit.gwi.uni-muenchen.de/?p=5773&v=7).
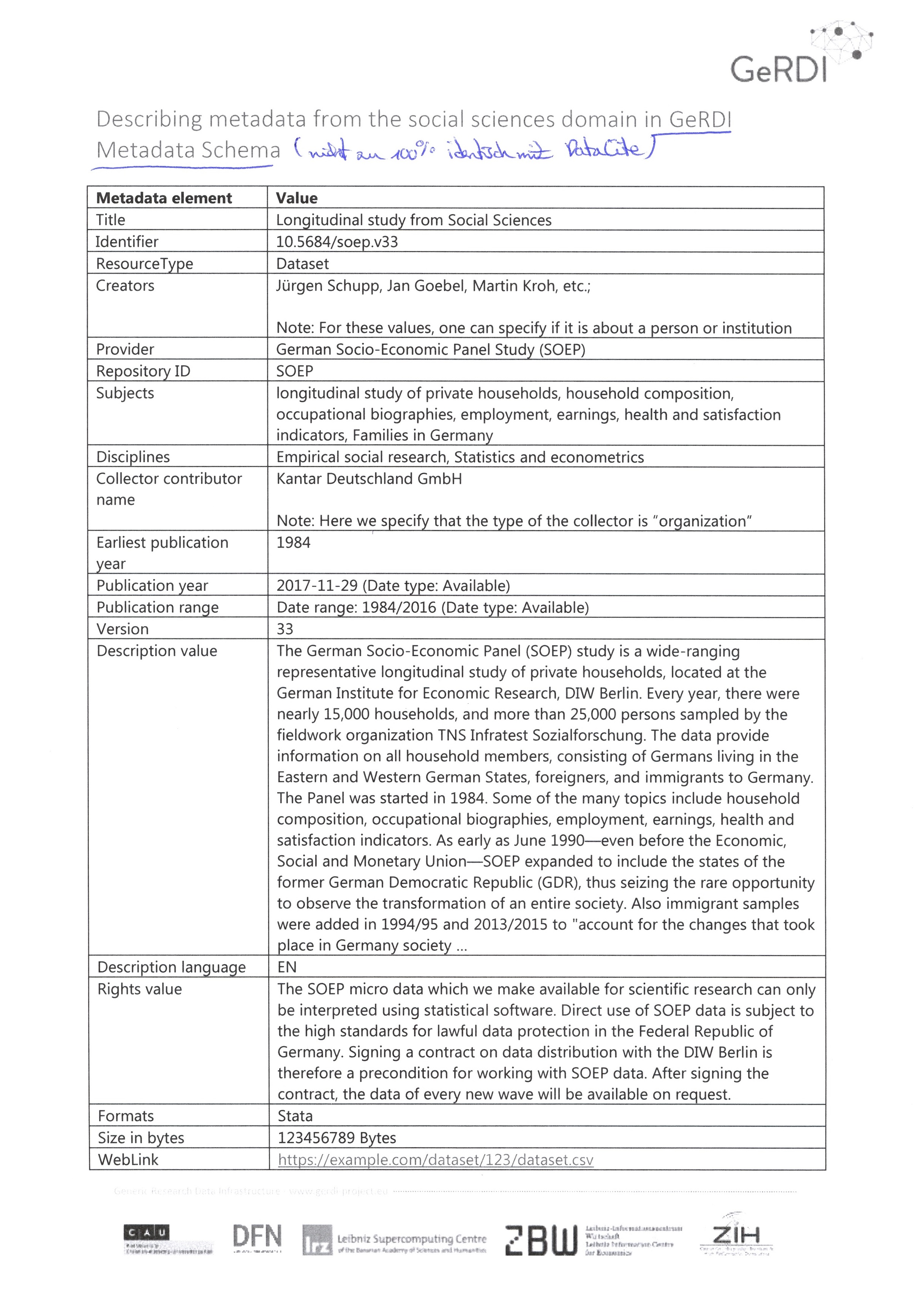
Die Frage nach der Sicherung und Verfügbarkeit von digitalen Ressourcen im Umfeld der Wissenschaft ist hochaktuell und beschäftigt derzeit auch die wissenschaftspolitische Ebene wie z.B. den "Rat für InformationsInfrastrukturen" (rfii), der das Ziel der Schaffung einer Nationalen Forschungsdateninfrastruktur (NFDI) verfolgt, oder das Bayerische Kultusministerium. Momentan ist VerbaAlpina eingebunden in zwei Projekte, die Lösungsansätze in diesem Umfeld evaluieren und entwickeln sollen. Bei dem einen handelt es sich um das von der DFG geförderte Projekt GeRDI (Generic Research Data Infrastructure). Ein Teil dieses Projekts ist am Leibniz-Rechenzentrum (LRZ) angesiedelt. Ziel von GeRDI ist, einen zentralen fach- und disziplinübergreifenden Metadatenkatalog aufzubauen, der in Zukunft das zuverlässige Auffinden digitaler Ressourcen und Informationen ermöglichen soll. Aktuell laufen Bemühungen, wenigstens Teile des VA-Datenbestands aus VA_DB exemplarisch in ein Metadatenschema zu überführen, das dann in den zentralen GeRDI-Index integriert werden soll.
Im selben Umfeld operiert seit Ende letzten Jahres das von der Bayerischen Staatsregierung geförderte Projekt "Forschungsdatenmanagement" (FDM; https://www.fdm-bayern.org/), dessen Ziel es ist, zuverlässige Lösungen im Hinblick auf die Sicherung und langfristige Verfügbarkeit von Forschungsdaten zu entwickeln.
Allgemein besteht im Hinblick auf den nachhaltigen Umgang mit digitalen Ressourcen noch keine Klarheit. So herrscht noch nicht einmal Einigkeit darüber, ob grundsätzlich *alle* Daten eines digitalen online-Projekts dauerhaft bewahrt werden sollen. Dies zeigt der gerade erwähnt Begriff "Forschungsdaten". Traditionell werden darunter z.B. Messdatenreihen von Klimaforschern verstanden, die sich anscheinend klar von den darauf aufbauenden Analysen und Erkenntnissen trennen lassen. VerbaAlpina vertritt den Standpunkt, dass eine solche klare Trennung weder möglich, noch sinnvoll noch angesichts der technischen Möglichkeiten nötig ist und strebt an, *sämtliche* im Projekt gesammelten und erzeugten Daten en bloc zu bewahren — z.B. auch die Protokolle der regelmäßigen Projektbesprechungen, die Einblick in den Fortgang der Projektarbeit geben und getroffene Entscheidungen transparent machen können. Neben dieser Frage, was man unter Forschungsdaten zu verstehen habe, ist auch noch nicht verbindlich geklärt, ob und wie Daten verbindlich strukturiert, dokumentiert und Metadaten versehen werden sollen und welche Institutionen mit welchen Aufgaben betraut werden sollen.
VerbaAlpina begegnet diesen Unsicherheiten durch die Suche nach Best-Practice-Lösungen und mit einem Konzept maximaler Flexibilität. Die Entwicklungen auf diesem Sektor werden aufmerksam verfolgt und die Strukturen und Prozeduren von VerbaAlpina darauf ausgerichtet. Unter den gegebenen Umständen erscheint es die beste Lösung, sich an möglichst vielen der z.T. parallel verlaufenden Anstrengungen zu beteiligen und gleichzeitig die VerbaAlpina-Ressourcen möglichst redundant in mehrere Systeme zu übertragen, die sich der Nachhaltigkeit und Nachnutzbarkeit von digitalen Inhalten verschrieben haben. Neben GeRDI wären in diesem Zusammenhang noch die UB der LMU zu nennen, bei der bereits eine ältere Version von VerbaAlpina in einem sog. Docker-System läuft. Dabei handelt es sich um eine gekapselte Serverinstallation, die garantieren soll, dass vor allem die in VA_WEB realisierten Funktionalitäten auch dann noch laufen, wenn es in Zukunft Serversoftware geben wird, mit der der von VA entwickelte Programmcode nicht mehr lauffähig ist. Zu erwähnen wäre schließlich noch das CLARIN-D-Repositorium. VerbaAlpina hat bereits vor längerer Zeit Kontakt mit den dortigen Verantwortlichen aufgenommen, die Realisierung der Übertragung von VA-Daten dorthin steht bislang aber noch aus. Sämtlicher von VA erzeugter Programmcode ist auf Github (https://github.com/VerbaAlpina/Verba-Alpina-Plugin) frei zugänglich und nachnutzbar.
Abschließend sei noch der Aspekt der Lizensierung erwähnt. VerbaAlpina ist der Meinung, dass Forschungsdaten im weitesten Sinne grundsätzlich frei zugänglich gemacht werden müssen. Entsprechend werden die Projektdaten von VA, soweit möglich, unter der CC-BY-SA 3.0 DE Lizenz zur Verfügung gestellt. VerbaAlpina fühlt sich den FAIR-Prinzipien (https://www.force11.org/group/fairgroup/fairprinciples) verpflichtet: Findable – Accessible – Interoperable und Re-usable sein!
Anhang
Eckdaten der technischen Realisierung
Modularer Aufbau: Datenbank (VA_DB) – Publikationsportal (VA_WEB) – Mediathek (VA_MT)
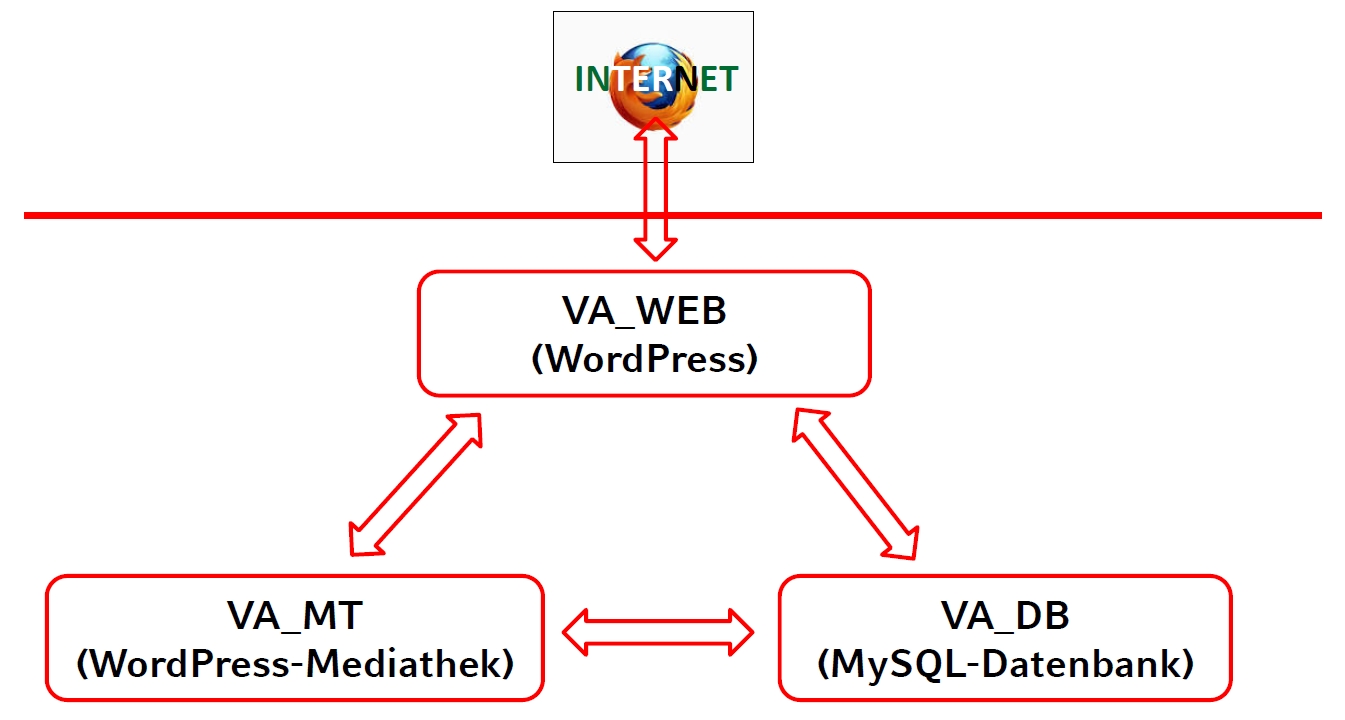
- VA_DB: MySQL-Cluster
- VA_WEB: WordPress-Installation mit Anbindung an MySQL-Datenbank
- WordPress: PHP-Framework, weit verbreitet, standardisiert;
- Visualisierung der Projektdaten auf einer Google-Map
- Anpassung der WordPress-Basisinstallation durch projektspezifische Erweiterungen, möglichst in Form von sog. Plugins.
- Plugin-Konzept ⇒ Synergieeffekte durch Weiterverwendung in anderen Projekten
Beispiel: Strukturierte Erfassung von Daten aus einem Sprachatlas
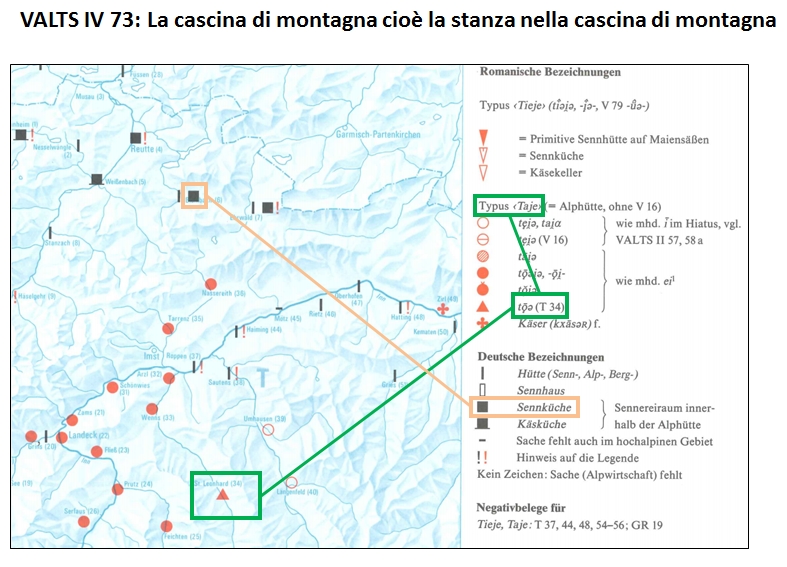
VALTS-Karte IV 73. Orange Markierung: Verwendung der Bezeichnung Sennküche für den SENNEREIRAUM INNERHALB DER ALPHÜTTE in der Ortschaft Bichlbach (T06). Grüne Markierung: Verwendung der Bezeichnung Taje für die ALPHÜTTE in der Ortschaft Sankt Leonhard (T34).
Die Abbildung präsentiert einen Ausschnitt aus dem VALTS|Vorarlberger Sprachatlas-Karte IV 73 ("Die Sennhütte bzw. der Sennereiraum auf der Alpe, Lautung und Bedeutung von Tieje, Taje f.").
Die Karte ist ein Repräsentant einer sog. Punktsymbolkarte, die die Verbreitung der sprachlichen Merkmale hauptsächlich durch unterschiedliche Symbole visualisiert, die jeweils bestimmten definierten Typen zugeordnet sind. Wesentlich ist demnach die vorangegangene Typisierung des gesammelten Sprachmaterials. Diese Art von Sprachkarte steht einer anderen Art gegenüber, auf der jeweils die konkreten Einzelbelege in häufig phonetischer Transkription direkt neben die korrespondierenden Erhebungspunkte geschrieben werden, ohne dass die Einzelbelege in irgendeiner Weise als Vertreter bestimmter Typen markiert werden würden.
Die Eintragungen auf dieser Karte sind sehr heterogen. So sind zunächst mehrere Konzepte auf einer Karte versammelt:
Aus der Legende geht hervor, dass auf der Karte darüberhinaus noch weitere Konzepte dokumentiert sind:
- SENNEREIRAUM INNERHALB DER ALPHÜTTE,
- PRIMITIVE SENNHÜTTE AUF MAIENSÄßEN,
- SENNKÜCHE,
- KÄSEKELLER,
- ALPHÜTTE
Die meisten dieser Konzepte sind nicht flächendeckend in allen kartierten Erhebungsorten abgefragt und dokumentiert worden. Insofern besteht also eine Inkonsistenz in der Fläche.
VerbaAlpina unterscheidet im Hinblick auf die Sprachdaten mehrere Abstrahierungsstufen. An der Basis befindet sich jeweils der individuelle Einzelbeleg, der von einem Gewährsmann/Informanten gleichsam zu Protokoll gegeben wurde. Diese Einzelbelege können sodann in verschiedener Weise typisiert werden. So können zum einen mehrere Einzelbelege, die bestimmte phonetische Gemeinsamkeiten aufweisen, zu phonetischen Typen zusammengefasst werden. Zum anderen können unterschiedliche Einzelbelege Repräsentanten ein und desselben morpholexikalischen Typs sein, unabhängig von phonetischen Eigenheiten.
Die (fiktiven) Einzelbelege Kaas und Kees würden z.B. aufgrund der differierenden Vokalrealisierung zwei unterschiedlichen phonetischen Typen zuzuordnen sein, wären jedoch beide auf denselben morpholexikalischen Typ Käse zu beziehen.
Auf der VALTS-Karte finden sich Vertreter sowohl von Einzelbelegen wie auch von phonetischen und morpholexikalischen Typen. Ein Vertreter eines Einzelbelegs wäre z. B. der Eintrag toːə in der Kartenlegende zum Erhebungspunkt T34, der als Vertreter des phonetischen Typs Taje aufgefasst wird. Diesem phonetischen Typ Taje wird auf der Karte der phonetische Typ Tieie gegenübergestellt, wobei das unterscheidende Merkmal offenkundig der hinter dem anlautenden T eingeschobene i-Laut ist. Grundsätzlich wäre die Definition weiterer phonetischer Typen denkbar, die sich an anderen lautlichen Merkmalen orientieren würden. So könnte man z.B. auch Belegvarianten, die dem Muster Toje folgen, oder solche, die anstelle des o ein e aufweisen, als weitere phonetische Typen auffassen.
Neben phonetischen Typen begegnen auf der VALTS-Karte auch morpholexikalische Typen. Als solche wären z.B. die unter der Rubrik "Deutsche Bezeichnungen" aufgelisteten Bezeichnungen (Senn-, Alp- oder Berg-)Hütte oder Sennhaus aufzufassen. Die Karte gibt keinen Aufschluss über die dahinterstehenden Einzelbelege und deren individuelle lautliche Varianten. Unsicherheit besteht auch im Hinblick auf die Frage, ob ein Informant nun Sennhütte, Alphütte, Berghütte oder einfach nur Hütte verwendet hat. Die strukturierte Erfassung der Daten zwingt jedoch jeweils zu klaren Entscheidungen, die daher oftmals nicht leichtfallen. Strenggenommen ist es im vorliegenden Fall gar nicht möglich, eine Entscheidung zu treffen. Lediglich die Verwendung des Wortes Hütte, möglicherweise als Bestandteil eines Kompositums, ist gesichert.
Bei der strukturierten Erfassung der Daten muss der Status jeder Eintragung identifiziert und entsprechend notiert werden. Eine automatisierte Erfassung der Daten ist unmöglich, manuelle Erfassung durch Personen mit sprachwissenschaftlichem Fachwissen zwingend erforderlich.
Das oben präsentierte Beispiel aus dem Vorarlberger Sprachatlas würde sich skizzenhaft in folgender Weise im relationalen Datenformat abbilden lassen:
Metadatenkategorien (Variable):
- Konzept
- Bezeichnung_morpholexikalischer Typ
- phonetischer Typ
- Einzelbeleg
- Gemeindename
- Gemeindenummer
| Konzept |
Bezeichnung_
morpholexikalischer Typ |
Bez_phontischer Typ |
Einzelbeleg |
Gemeindename |
Gemeindenummer |
| SENNEREIRAUM INNERHALB DER ALPHÜTTE |
Sennküche |
|
|
Bichlbach |
T6 |
| ALPHÜTTE |
Teie(n) |
Taje |
toːə |
St. Leonhard |
T34 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Grundlage für die Transkription ist eine von VA erstellte sog. Codepage, in der die Regeln für die Abbildung von Sonderzeichen durch ASCII-Zeichen festgelegt sind.
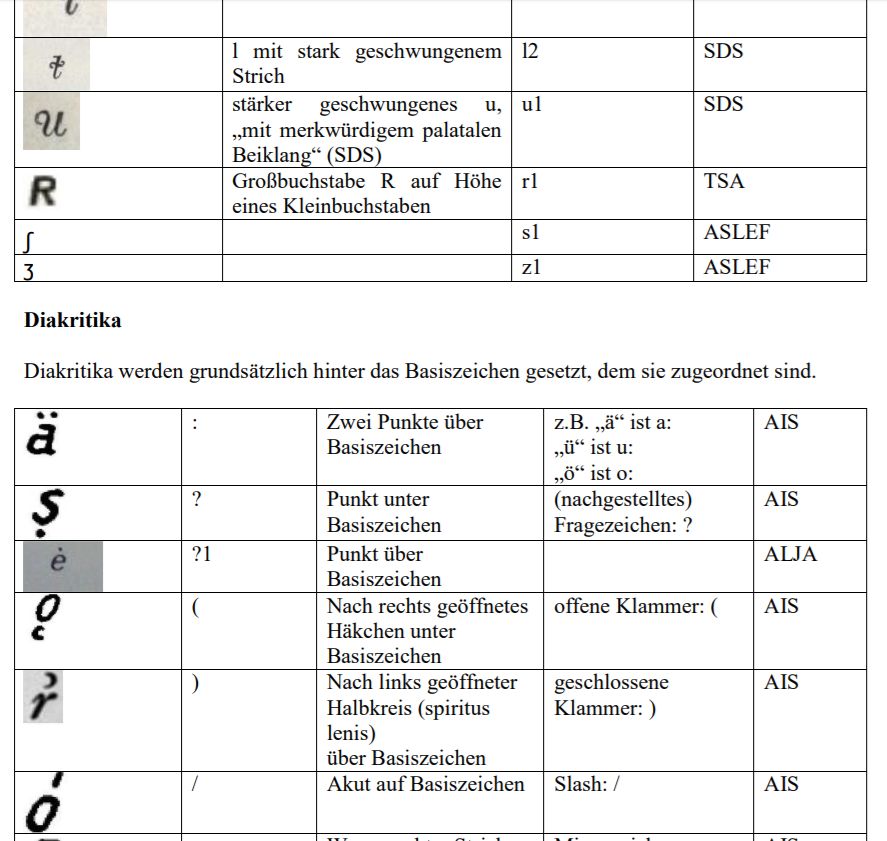
Ausschnitt aus den Transkriptionsregeln von VerbaAlpina für die Erfassung von Daten aus Sprachatlanten
Bibliographie
- VALTS|Vorarlberger Sprachatlas = Eintrag nicht gefunden
Eintrag nicht gefunden
VerbaAlpina
Datenbank
Partner VerbaAlpina
sogenannt
vorrömisch
folgende
structured query language
Ludwig-Maximilians-Universität München
American Standard Code for Information Interchange
International Phonetic Alphabet
Seite
lat. sub voce (
deu. unter dem Stichwort)
Latein (ISO 639-3)
Substantiv
Deutsch (ISO 639-3)
Substantiv
lat. versus (
deu. im Gegensatz zu)
Latein (ISO 639-3)
Deutsch (ISO 639-3)
Uniform Resource Locator
Digital Object Identifier
Uniform Resource Name
Universitätsbibliothek
Femininum