

Abstract
Since 2014 the DFG-funded long term project VerbaAlpina (VA) is run at the Ludwig-Maximilians-University of Munich (LMU). VA is a cooperation of the Institute of Romance Studies and the LMU Center for Digital Humanities (DH; IT-Gruppe Geisteswissenschaften).
The project focuses on lexical variation throughout the Alpine area as defined by the so-called Alpine Convention (https://www.alpconv.org/). Whereas geolinguistic research within the Alpine region is traditionally orientated towards the spread of national languages and towards political borders, VA takes the homogeneous natural environment of the mountaneous region and the resulting uniform habitat conditions and ways of living as the guiding parameters defining its area of research.
VA is conceptualized as a strictly digital project that uses web technology for various purposes such as documentation, publication and visualisation. VA takes its data from traditional geolinguistic publications, mainly linguistic atlases and suitable dictionaries (i.e. dictionaries providing geographic information). The strictly digital approach is associated with several challenges starting from the difficulties regarding the transcription of the sometimes complex phonetic characters that are used especially in some of the linguistic atlases. VA has developed a series of specific reusable and freely available online tools that are used within the workflow of digitizing data from the printed sources. Another tool, the so-called Crowdsourcing tool, was built for gathering speech data from online users with the aim of filling documentation gaps that result from inconsistencies of the available printed sources.
An interactive online map that is using performant up-to-date graphical technology (WebGL) offers suggestive qualitative and quantitative visualisation of geographic distribution patterns from onomasiological and/or semasiological perspectives. These can also be combined with non linguistic data such as the sites of latin inscriptions.
In addition to the geolinguistic core themes of the project, VA is providing methodological reflexion on many of the issues deriving from the strictly digital orientation that should be of interest also beyond the borders of the project and even beyond the field of geolinguistics. In general, VA is looking for perspectives and solutions that allow the linkage of lexical data across so far isolated domains of geolinguistic research projects with the option of real interoperability (the “I” in the acronym FAIR).
The talk will provide more detailed information on the mentioned aspects of the project VerbaAlpina.
Talk*
One word in advance: It is still common to work with PowerPoint presentations on occasions like this. VerbaAlpina tries to avoid PowerPoint as it does not totally comply with the "FAIR"-criteria: At least a powerpoint presentation is not interoperable (FAIR) at all and usually hardly findable, accessible and reusable (FAIR). On the other hand, all these demands are met with a web-based contribution like the one you can see right here. This preamble is not meant as a criticism of using Powerpoint but rather as an apology for the use of this different kind of presentation.
You can scan the QR-Code below with your smartphone and follow the talk on your mobile device.
! Scan with Smartphon !

! Scan with Smartphon !
Introduction
Some of you might already know our project VerbaAlpina. Nevertheless, I will start my talk by sketching the overall frameset of VerbaAlpina.
Scientific Approach
VerbaAlpina is a linguistic project with mainly lexical orientation. The focus is on a simple question: We would like to know which terms are used for specific concepts in the Alpine region. The documentation is limited to concepts that are typical for the Alpine region, such as mountain pasture and dairy farming or the specific alpine flora and fauna. From the point of view of traditional geolinguistics, a fundamental innovation is certainly the definition of the research area. The scope of many of the existing speech atlases for example complies with political-administrative concepts such as national territories or the selection criterion is restricted to the distribution of national languages. In contrast, VerbaAlpina has chosen the homogeneity of the Alpine region in terms of landscape, culture, and economy as the decisive aspect for the definition of the research area.
As already mentioned, the focus of VerbaAlpina's interest is the lexical material. VerbaAlpina's database is primarily based on material published in traditional language atlases. To a certain extent dictionaries were also used, but only those whose entries contain information on the geographical distribution of the documented terms. Examples include the Swiss-German Idiotikon or the Dizionario di Montagne di Trento by Corrado Grassi (DizMT).1. Among the language atlases prominent examples are the Sprach- und Sachatlas Italiens und der Südschweiz (AIS) and the Vorarlberger Sprachatlas (VALTS).
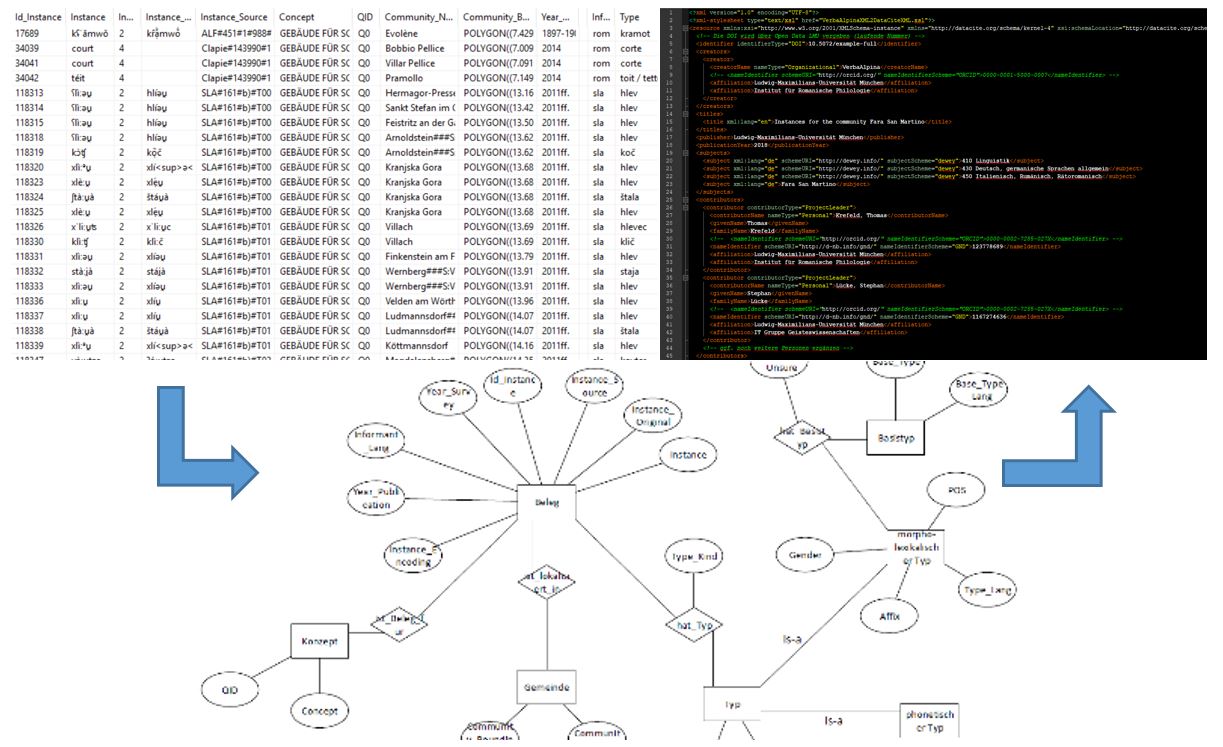
VerbaAlpina sees itself as an entirely "digital" online project that completely refrains from publications in conventional book or atlas form. The term "digital" also refers to work with *structured* data, that means data enriched with metadata. All these data are managed in a relational database (MySQL).
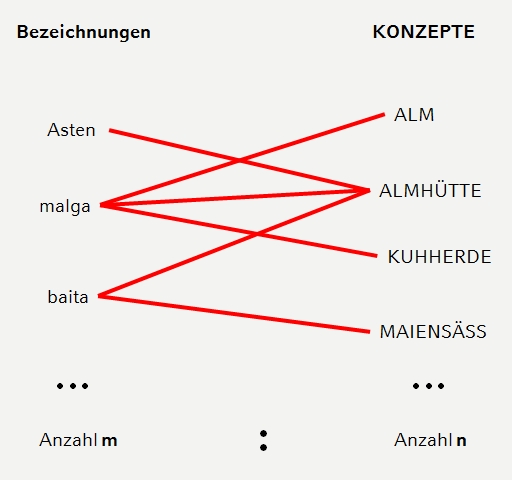
VerbaAlpina's data model is dominated by the correlation between the world of language and the extralinguistic reality, that is the world of concepts. The following scheme illustrates this correlation and makes it clear that in principle a certain word can designate more than just one concept and vice versa several words can exist for one and the same concept. In the context of VerbaAlpina, concepts are always written in capitals to clearly distinguish between words and concepts:
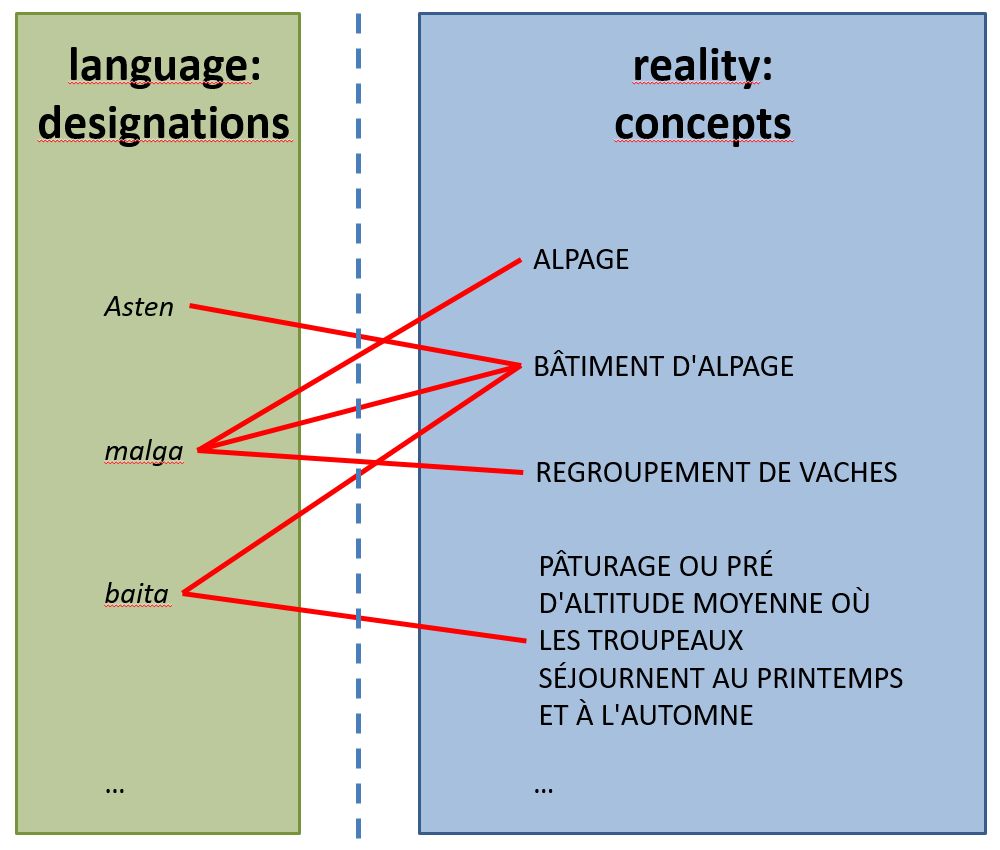
Correlation between designations and concepts
This basic model, which initially appears very simple, quickly acquires a high degree of complexity by adding the dimensions of space and time. This is because certain terms for certain concepts are only used in certain regions. The location and size of these regions can change over time or even disappear altogether.
So the question is:
- Which words are or have been used
- at which places
- at what time to designate
- which concepts?
Since the dimension of space is one of the central factors, VerbaAlpina only collects language material with georeferencing, as is the case in language atlases or in some dictionaries.
VerbaAlpina's spatial dimension is defined by the perimeter of the so-called Alpine Convention. The Alpine Convention is a treaty under international law signed by the countries sharing the Alps. The perimeter is a boundary drawn by this organisation which defines the extent of the Alps administratively. For purely pragmatic reasons VerbaAlpina follows this border since a clear delimitation of the study area is organisationally indispensable and otherwise hardly possible.2
Within the study area all collected and georeferenced language material is related to the grid of political communities. In the case of large-scale distribution data such as "Ticino" or "Vorarlberg", the corresponding language data is attributed to all municipalities in these regions. Starting from the fine granulation of the political communes, the language material can be grouped in later analyses according to superordinate political units such as cantons, departments, government districts or regions and visualised on a map.
From VerbaAlpina's point of view, the dimension of time is a little problematic, since the data grid is still very patchy in terms of chronological distribution and unbalanced in relation to the entire Alpine region. Some of the sources evaluated by VerbaAlpina indicate the time of the collection of a single document very precisely, sometimes even to the day3, while for other sources the year of publication only provides a terminus ante quem for the language data recorded therein.
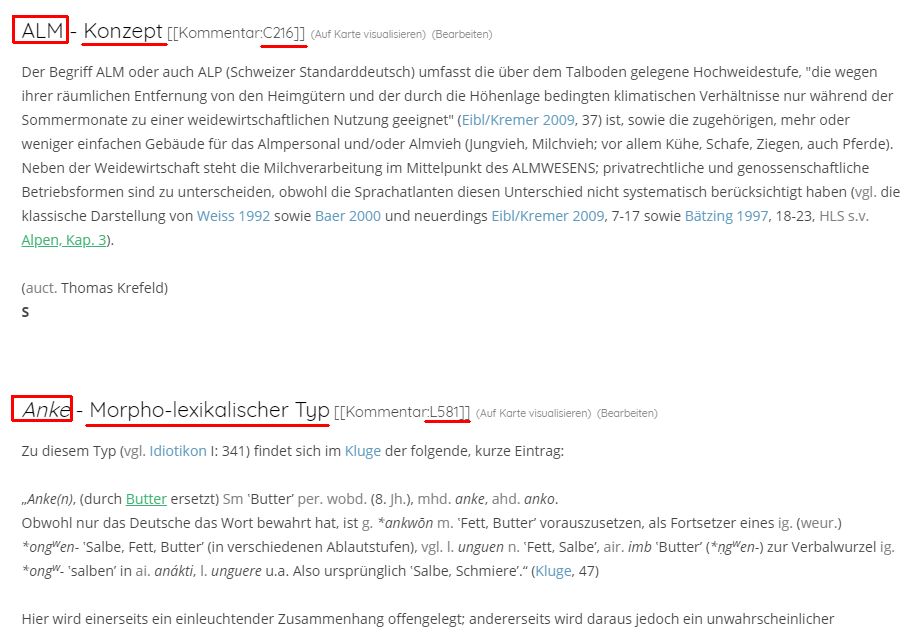
VerbaAlpina's data material acquires historical depth through the interlocking of the words drawn from the sources and the identification of similarities in the lexical basis. French salamandre, Italian salamandra and German salamander have the same lexical basis. It is obvious to assume a historical connection here. However, it is not easy to decide whether, for example, the German word is derived from one of the two Romance words (loanword scenario), or whether all three variants can be traced back to a common forerunner independently of each other. In such cases, VerbaAlpina identifies a lexical precursor from an earlier language spoken in the Alpine region and assigns it to the modern words in order to be able to grasp *that* there is a connection between the three words mentioned. VerbaAlpina refers to such precursors as "base types". In the case of the example this would be the Latin salamandra.
The reason for this simplification is twofold: on the one hand, it is often not possible to decide which of the possible scenarios mentioned is present in the individual case and on the other hand, corresponding searches may be very time-consuming, so that they cannot be carried out within the framework of the project due to time constraints. The VA base types have the great advantage that they can be used to represent obviously existing connections *without* forcing the specification of the connections in detail.
The central reference value of VerbaAlpina are the so-called "morpholexical types", hereinafter referred to as "morph types". These are lexical units that are distinct, that means unmistakable, with regard to the linguistic family they belong to, spelling, genus and the question of whether they have an affixation or not. In this respect, the morph types correspond roughly to the lemmas of traditional dictionaries. These are predominantly nomina, verbs only play a subordinate role in VerbaAlpina so far.
VerbaAlpina initially bases its typification on so-called reference dictionaries. If there is a suitable entry in these dictionaries, it is assigned to the selected tokens. If the type exists in several reference dictionaries, multiple assignments are made. If a morph type does not exist in any reference dictionary, VerbaAlpina creates its own new morph type which is then assigned.
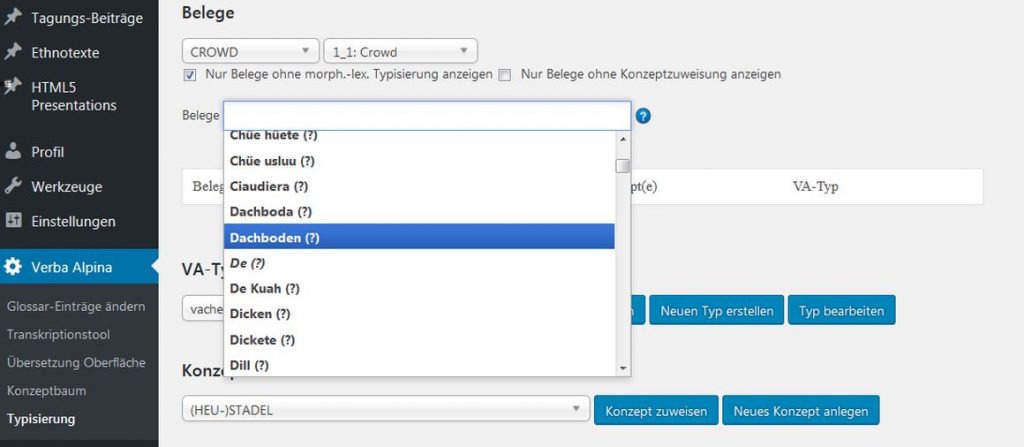
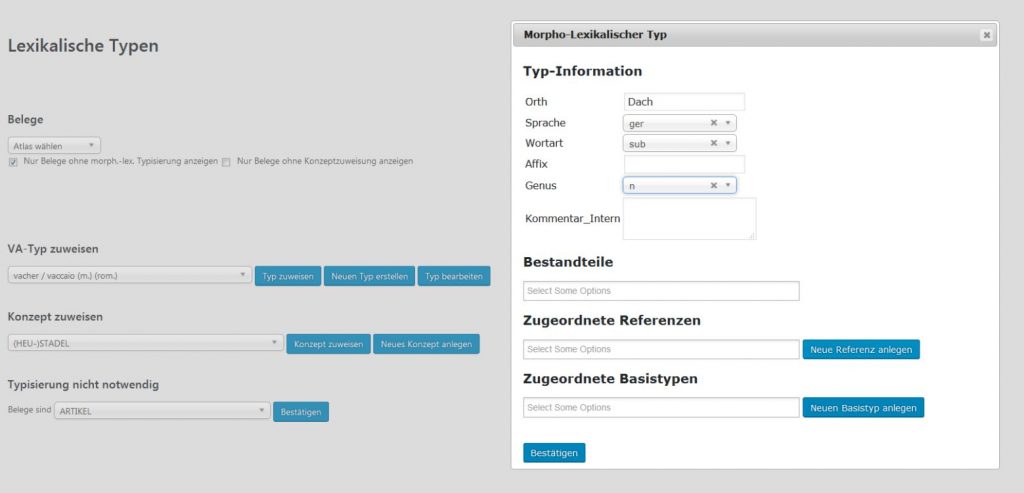
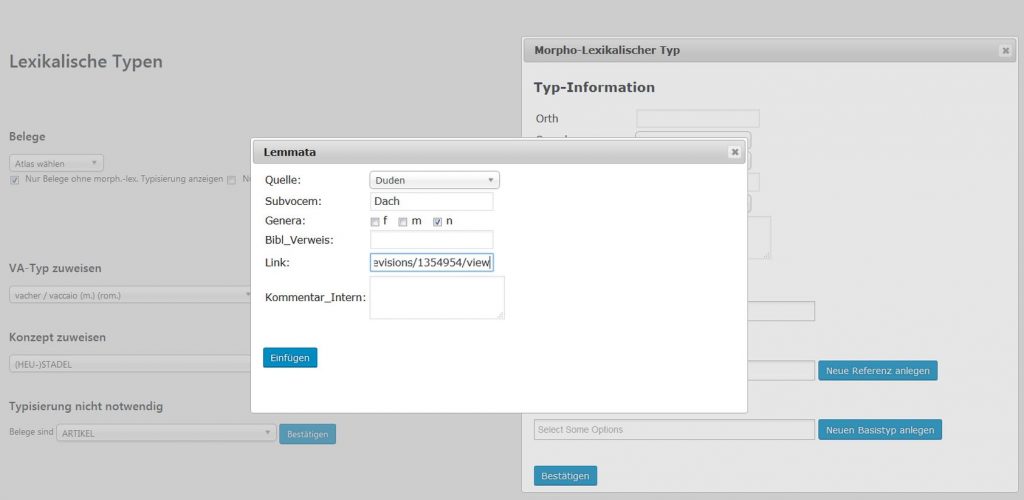
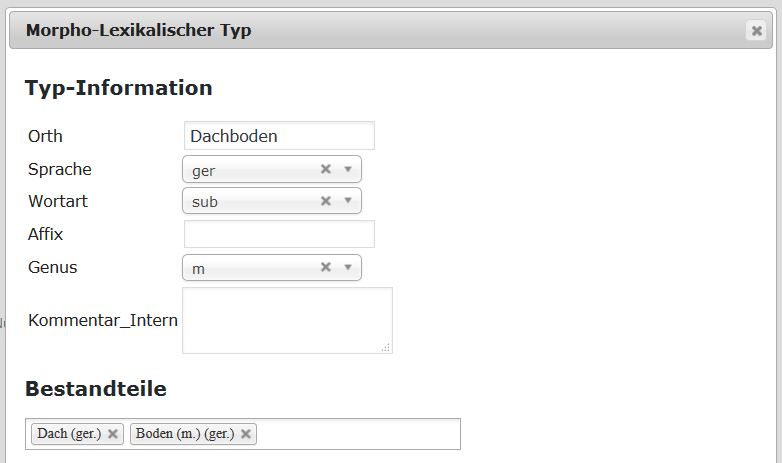
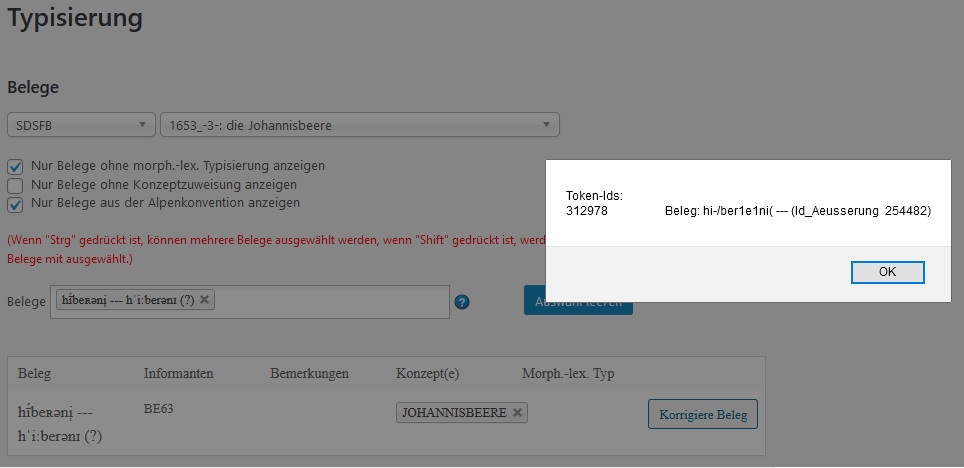
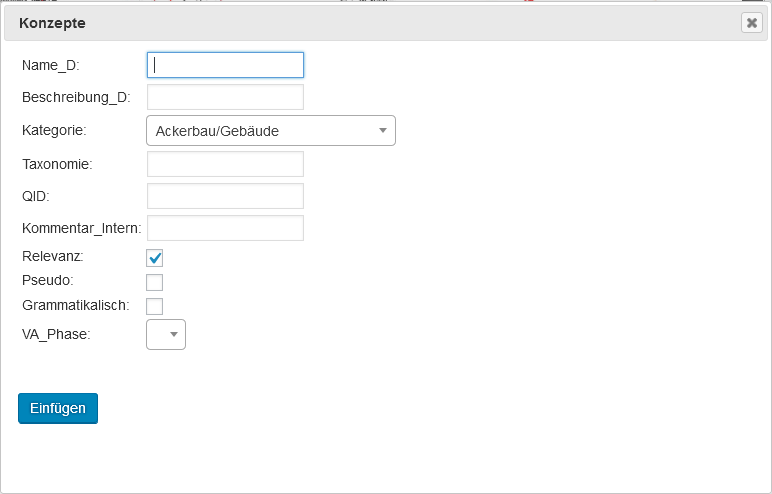
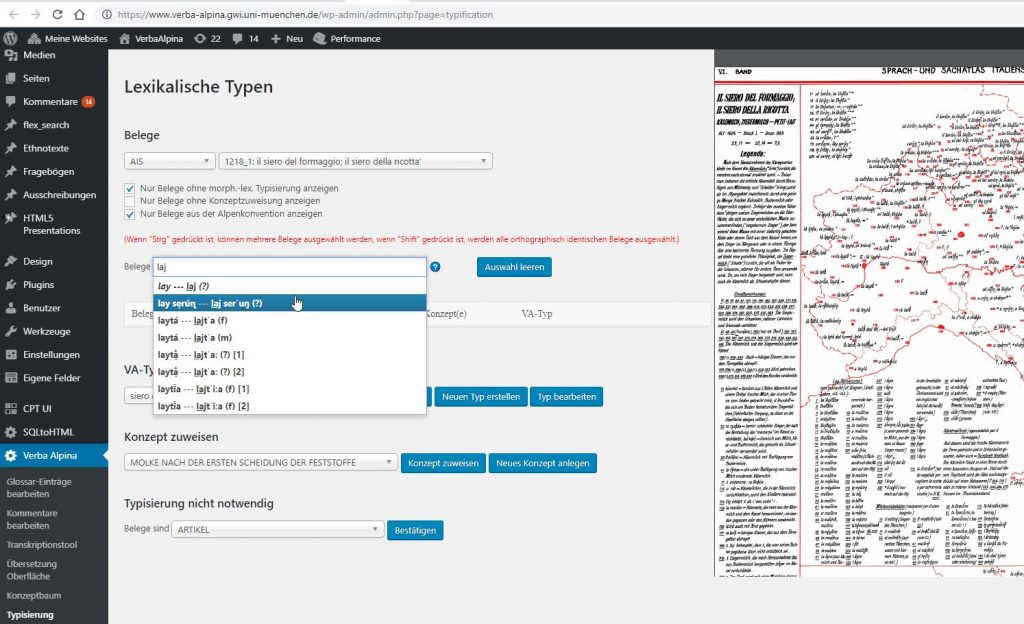
For the data collected from language atlases and dictionaries the morph type they represent must be decided on a case-by-case basis. An automatic assignment seems impossible. VerbaAlpina has developed a special tool facilitating manual typification, in which the transcribed and then tokenised utterances can be assigned to morph types (screenshot; link [registered users only]).
VerbaAlpina deliberately refrains from assigning morph types to individual languages or even dialects. The reason is that linguistic landscapes and thus also the Alpine region basically represent continua within which clear demarcations are practically impossible. Strictly speaking, each locality can have its own dialect. When defining the morph types, therefore, only the assignment to one of the three language families existing in the Alpine region is made. The assignment to a language family is inherited from the sources from which the documents belonging to the respective morph type originate.
The phonetic dimension is largely ignored by VerbaAlpina but can be mapped in the VerbaAlpina data model and is already present selectively in the database.
Many project specific aspects, be it related to linguistics or computer sciences, are reflected and thus documented in the methodology section of the project website.
Technical Aspects
VerbaAlpina tools
VerbaAlpina uses standard software wherever possible which must also be open source. Essentially, this involves the MySQL database management system (DBMS) for managing the central database and the WordPress PHP framework for the project website. For the specific requirements of the project, however, tools based on the aforementioned basic technologies have been developed. All of them are available on Github for free re-use under the CC-BY-SA license (VerbaAlpina-Github-Repository). And there is already one case in which some of our tools is reused: The VerbaPicardia (APPI).
Betacode and Transcription Tool
Betacode
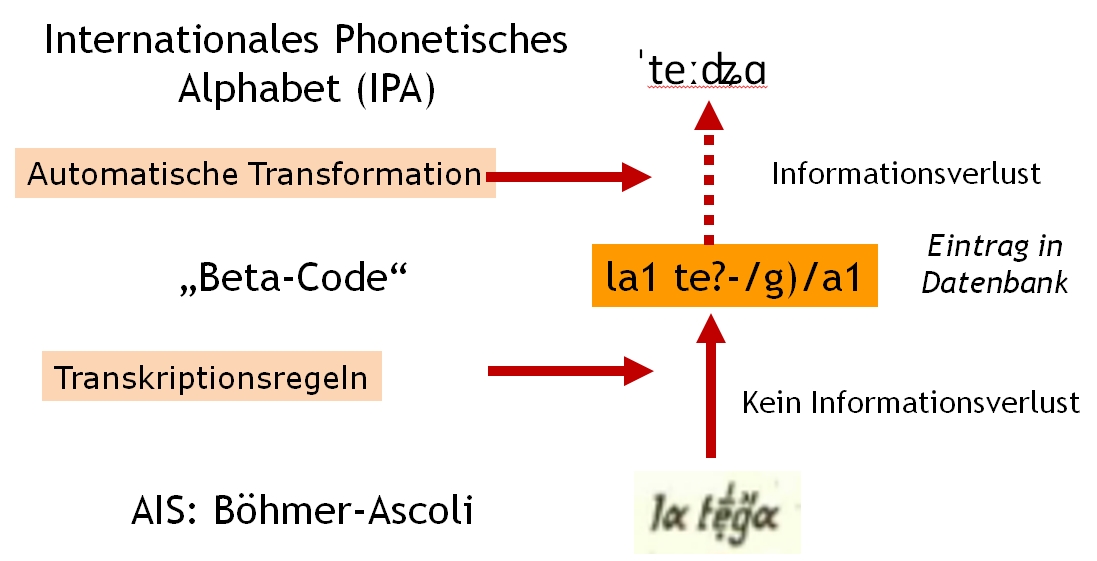
For the transcription of "exotic" writing systems, that primarily are found in language atlases, VerbaAlpina uses a concept that was developed and successfully used for the Thesaurus Linguae Graecae (TLG) in the 1970s (TLG-Betacode). In essence, the aim is to replace arbitrary characters and diacritics with defined and documented sequences of ASCII characters. The rules follow as simple and mnemotechnically favorable patterns as possible. For example, an acute on a base character is transcribed by a slash behind the base character.
The utterance you see here4:
![]()
taken from the AIS, is transcribed according to the transcription rules as follows:
la lac/a/
The sound value denoted by a sign is not important at all. This also means that identical signs such as the acute are always transcribed in the same way, that means with a slash after them, completely independent of the transcribed original and the possibly specific phonetic meaning. Only a source specific conversion procedure, in which all transcriptions are transferred into the IPA system, takes the sound values of the original source into account.
This method has several advantages:
- It is possible to transcribe characters that are not yet Unicode-encoded.
- The transcription can be done comfortably with standard keyboards and without complicated key combinations.
- The transcriptors do not require knowledge of the meaning of the characters.
- The transcriptions are – unlike multi-byte characters from UTF-8 – technically robust against unwanted changes.
- Transcription takes place without loss of information.5
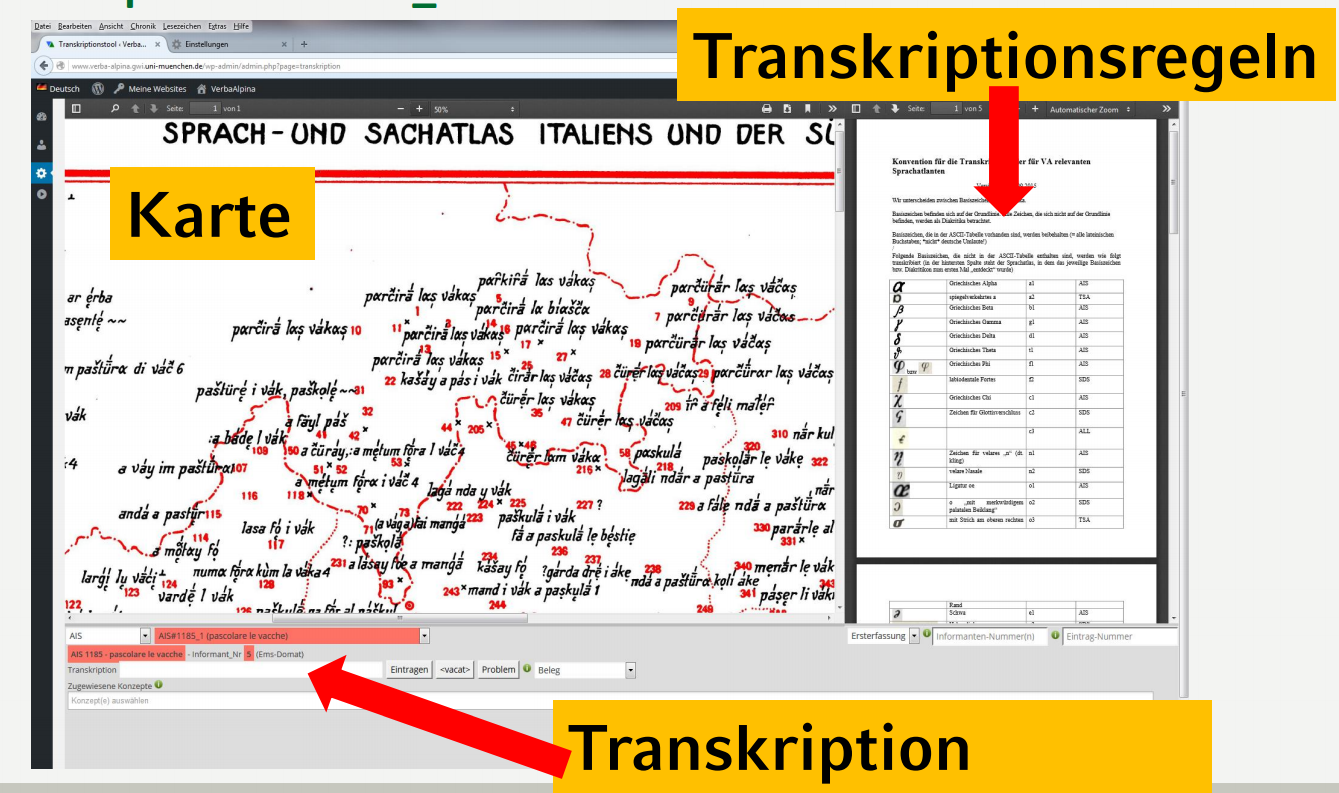
Transcription Tool
Especially, the automatic structured recording of lexical material from language atlases represents a considerable technical problem. It is not about the transformation of the partly exotic writing systems, which are sometimes used there. OCR programs such as Abbyy Finereader can be trained in such a way that they also correctly capture such writing systems and even produce the VerbaAlpina-specific beta code.6
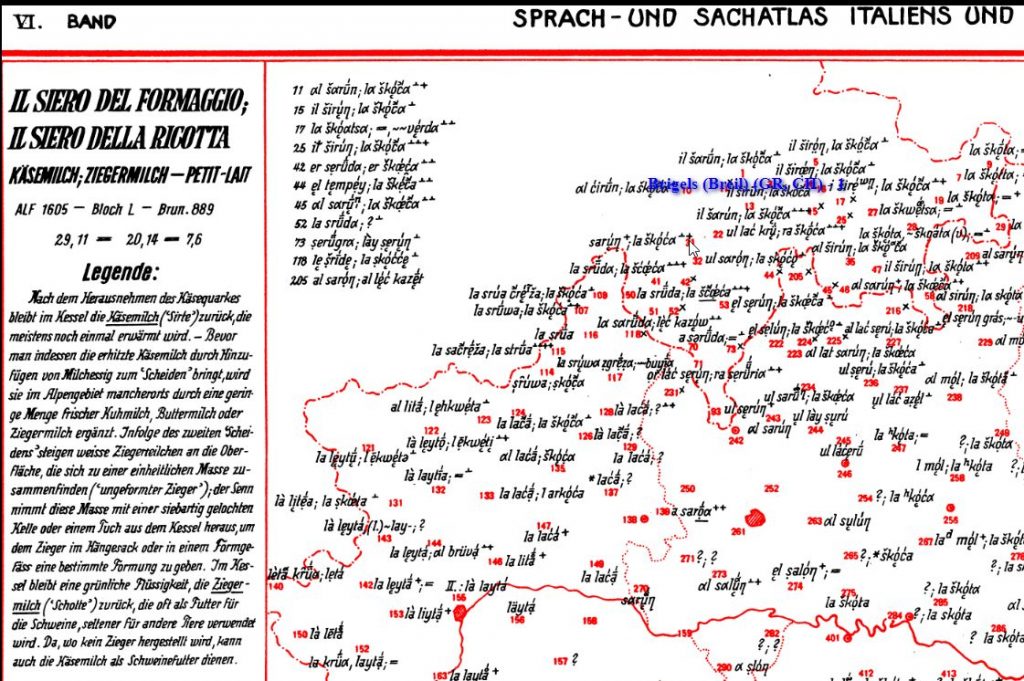
In case of the linguistic atlases of the Romance tradition the real difficulty lies often in assigning the correct place, represented by a number, to the statements entered directly on the map. Machines are always overwhelmed by this task – and sometimes even humans are – when the entries on the map are too close together, as is the case, for example, in the AIS in southern Switzerland and neighbouring Italy.7

AIS-map 1218: Problem of assigning strings to numbers
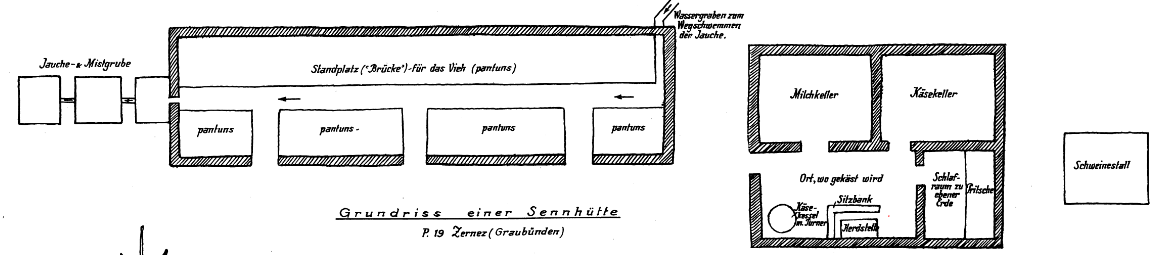
From the point of view of automatic data acquisition the language atlases with point symbol maps, which are widely used in the field of German studies, appear to be even more complicated. In contrast to the Romance atlases data is usually displayed here in typified form. Concrete individual utterances of the informants are only presented occasionally.
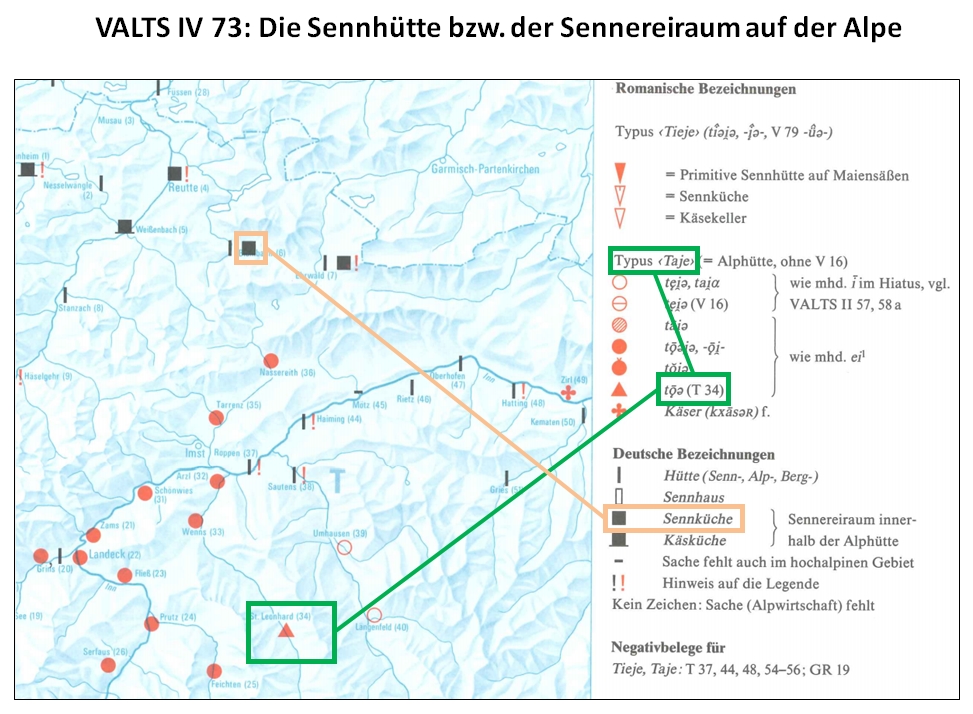
Punktsymbolkarte germanistischer Tradition (VALTS IV 73: Die SENNHÜTTE)
Transcription tool
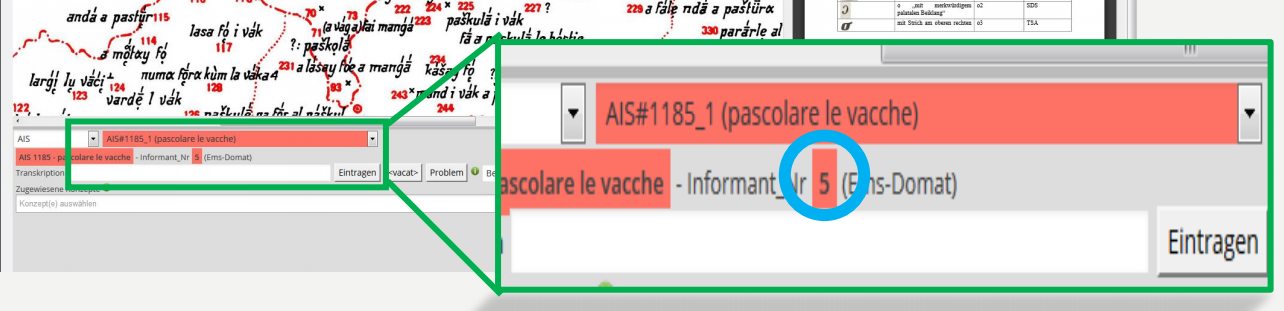
The tool synoptically combines a scan of the map to be transcribed and the form in which the transcriptions are entered. Maps and points on the map that have already been transcribed are marked accordingly. The system also prevents the duplicate capture of individual entries on the map. The transcriptor is given the numbers or signatures of the points on the map one after the other by the system. The transcription then takes place in the appropriate field of the form. The other parameters such as map number, location point number and concept assignment are specified by the system and are stored together with the transcription in the database. The registered data in the database then look like this:

The input mask presents the general transcription rules for data entry in beta code in a windowframe at the top right, so the transcriptor can consult them with as little effort as possible. The automatic conversion corresponding to the original script on the map is displayed to the right of the input field as the transcriptor is writing. Thus, the transcriptor can immediatly detect eventual typos. In addition, the system prevents entering invalid character combinations.
Crowdsourcing tool
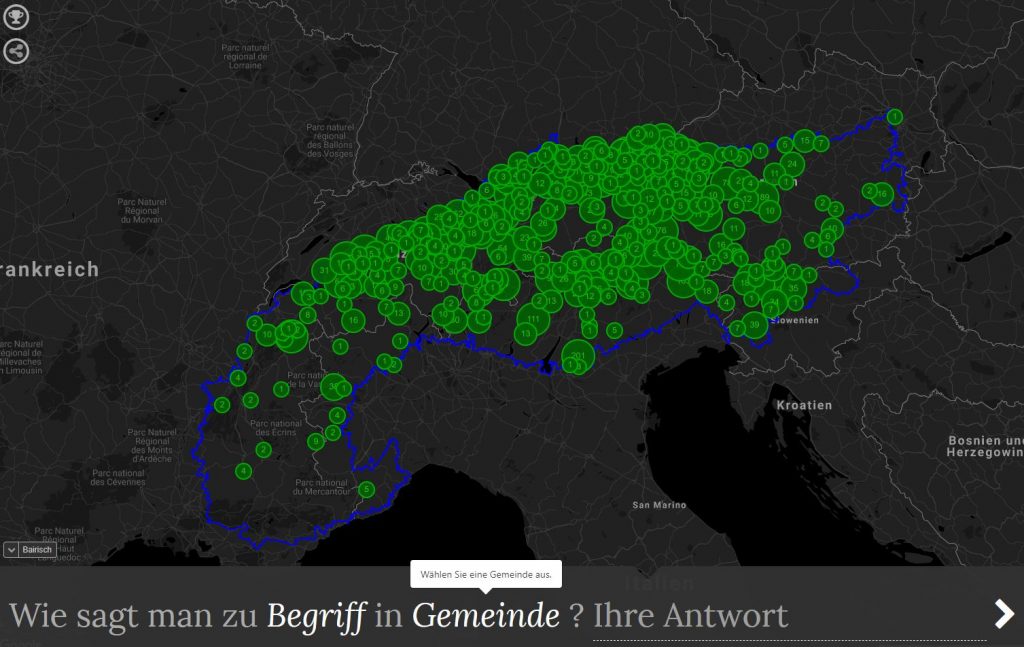
The database compiled by VerbaAlpina from language atlases and dictionaries shows inconsistencies in several respects. These inconsistencies result mainly from the fact that the language atlases each cover only parts of the Alpine region and do not all comprise the same concepts. As a result, for a certain region there are terms for concepts that were not even queried elsewhere – which does not mean that they do not exist there. For example the concept BEE is only attested in the areas documented by the following atlases: AIS, ALF, ALJA, ASLEF, TSA as is visualized on the following map8
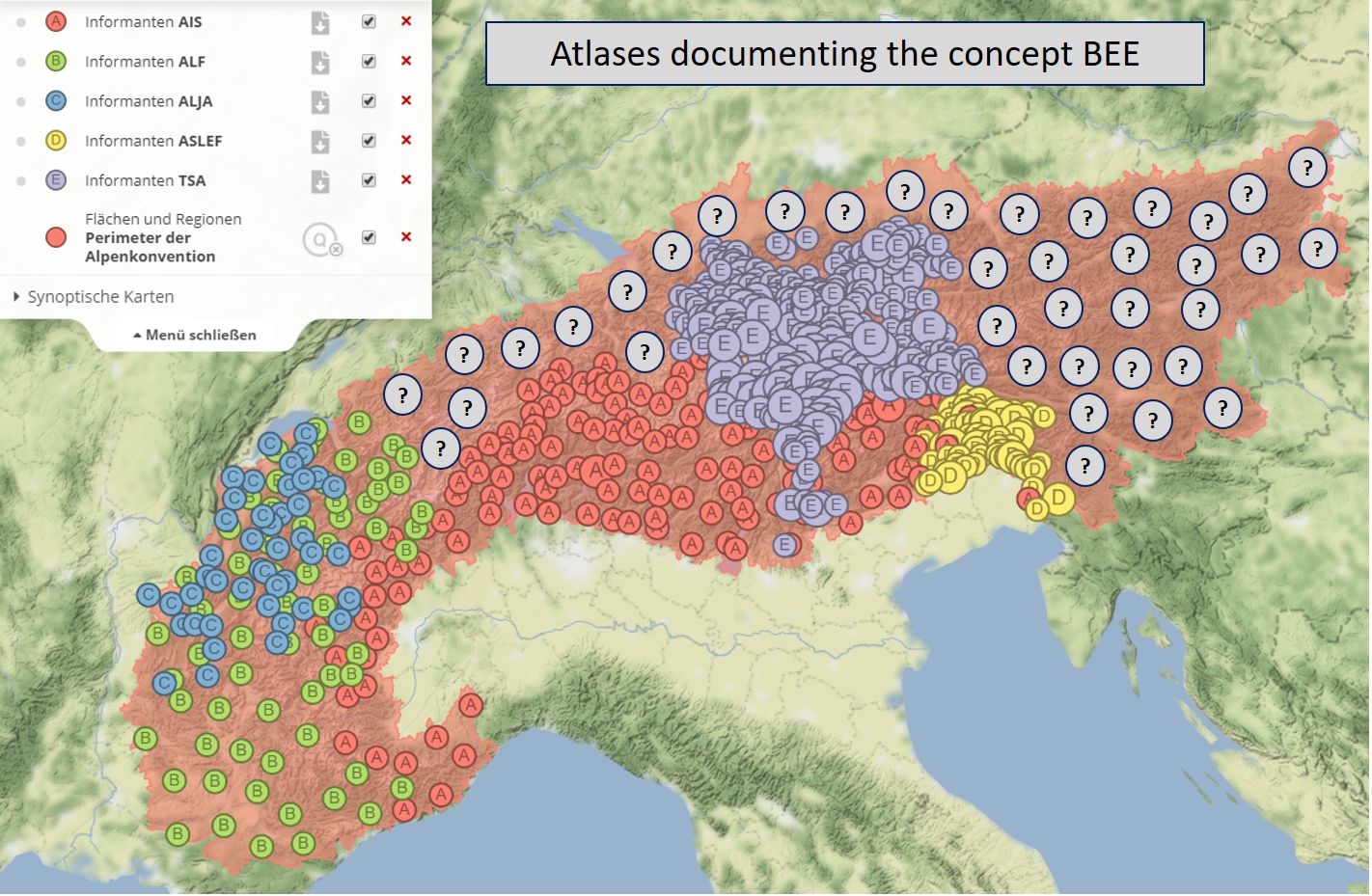
Missing attestations for the concept BEE
It is not possible to carry out any surveys to fill the gaps. VerbaAlpina is therefore using the idea of crowdsourcing to round off the database. The idea is that users on the Internet contribute previously undocumented terms for selected concepts. VerbaAlpina has developed a special crowdsourcing tool (CS tool) for this purpose (Link). The functionality is deliberately kept simple so as not to deter potential crowders.
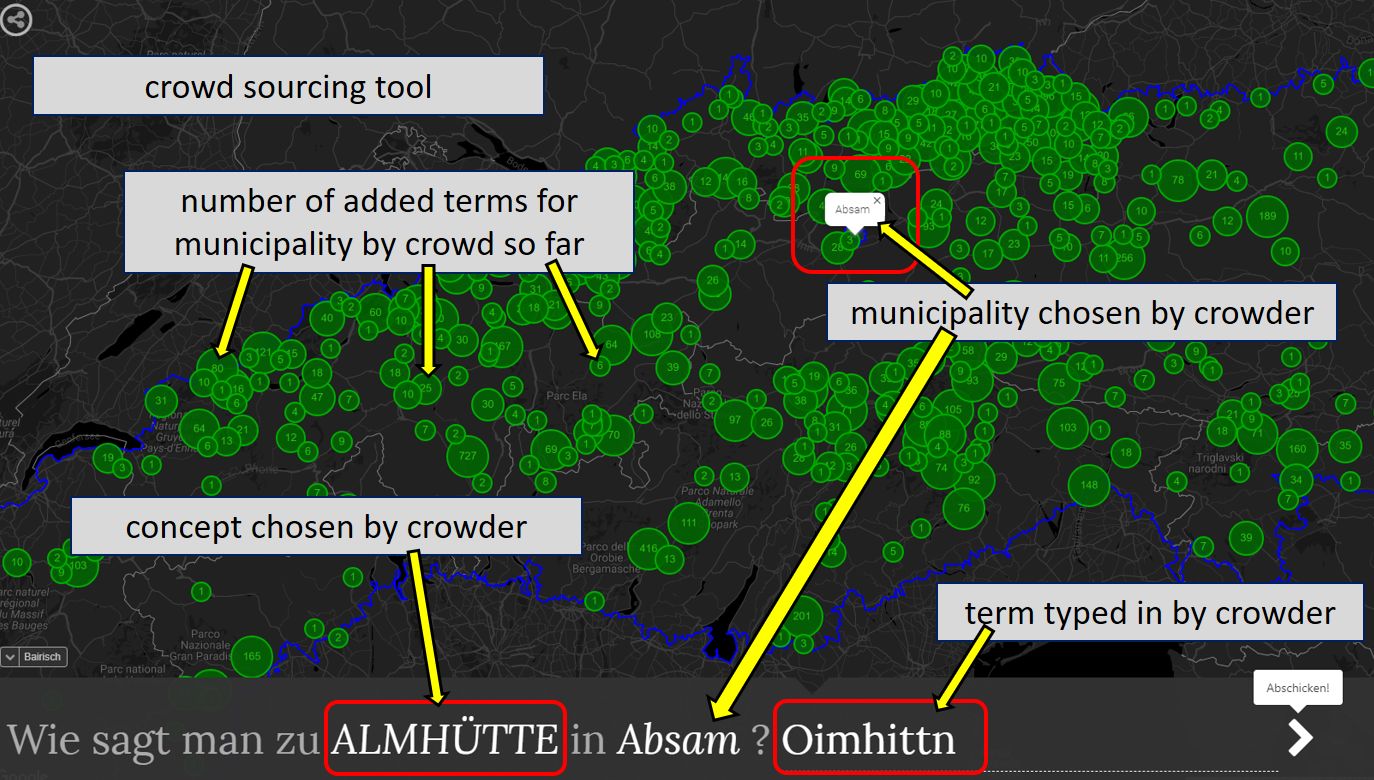
The VerbaAlpina Crowdsourcing (CS) Tool
Each "crowder" has to select a location on a map and enters designations for selected concepts that are, in his opinion, common at this location. VerbaAlpina typifies the entire material as well as the data from atlases and lexica. A validation of the crowd material is theoretically possible through the principle of third-party confirmation but is currently not carried out by VerbaAlpina, mainly because the amount of data is still too small.
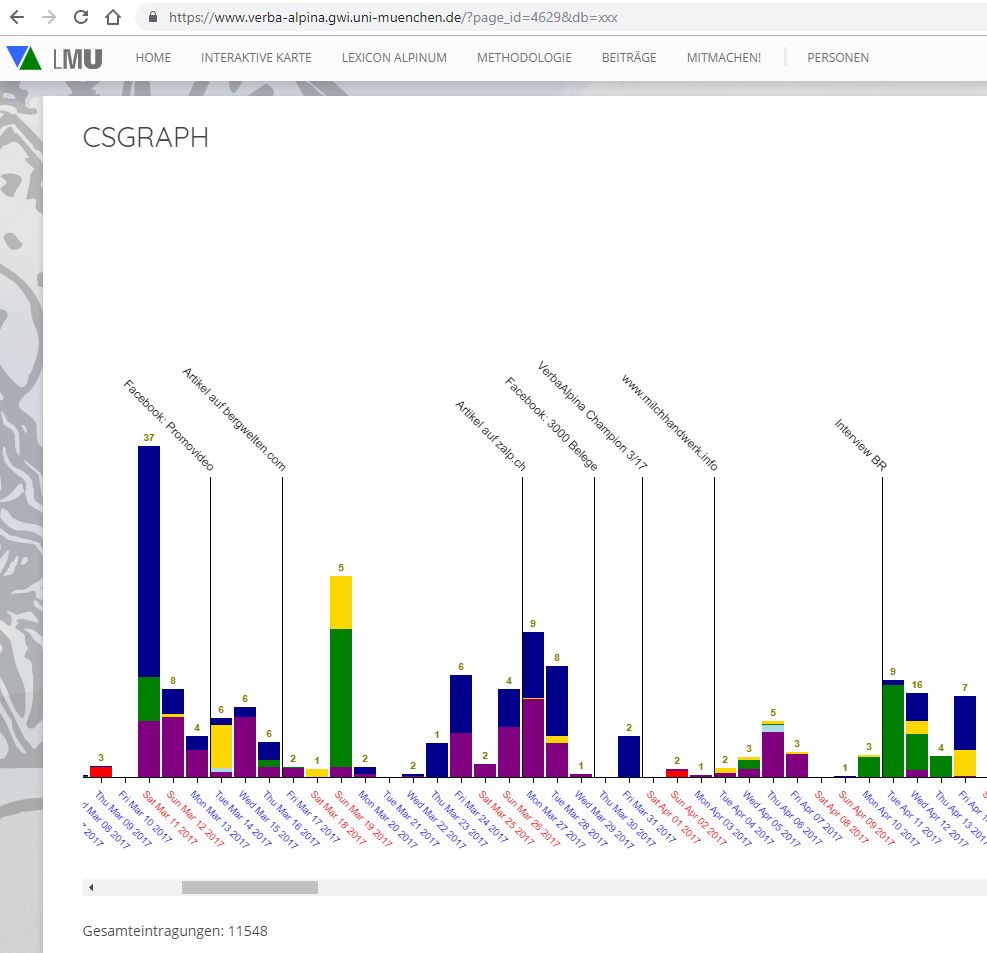
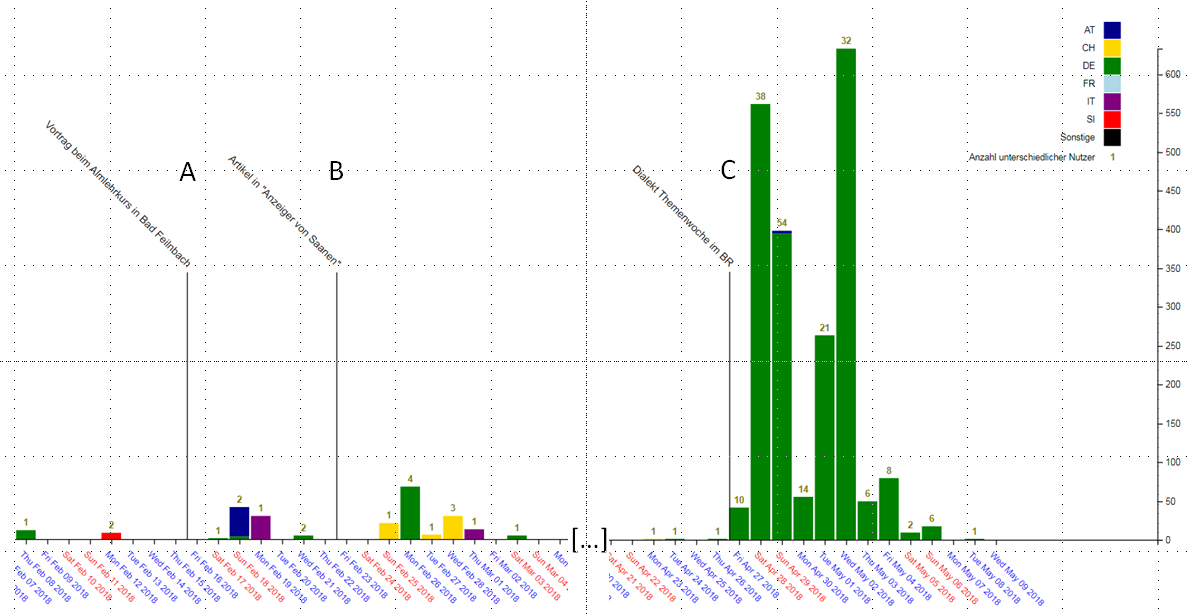
VerbaAlpina is monitoring the crowd activity (Link). Experience has shown that the vitality of the croudsourcing tool, that is: the number of entries, depends crucially on corresponding advertising activities. Immediately after media reports about VerbaAlpina and its crowdsourcing tool or corresponding propaganda in social media, the number of entries rises sharply but always falls again soon.
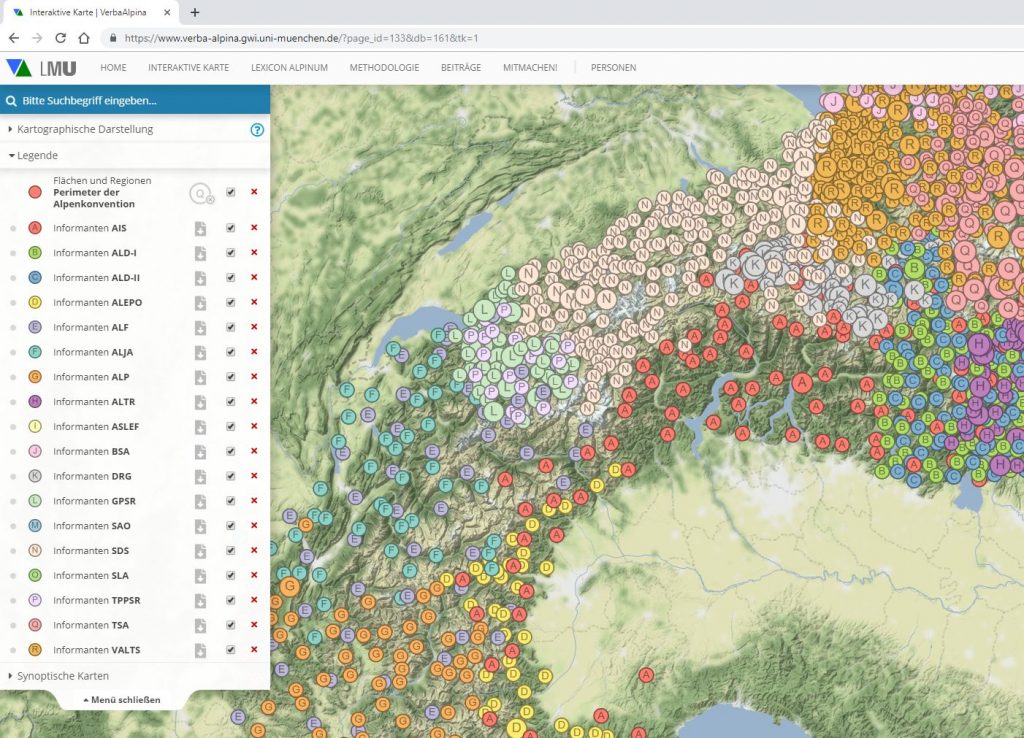
Mapping tool
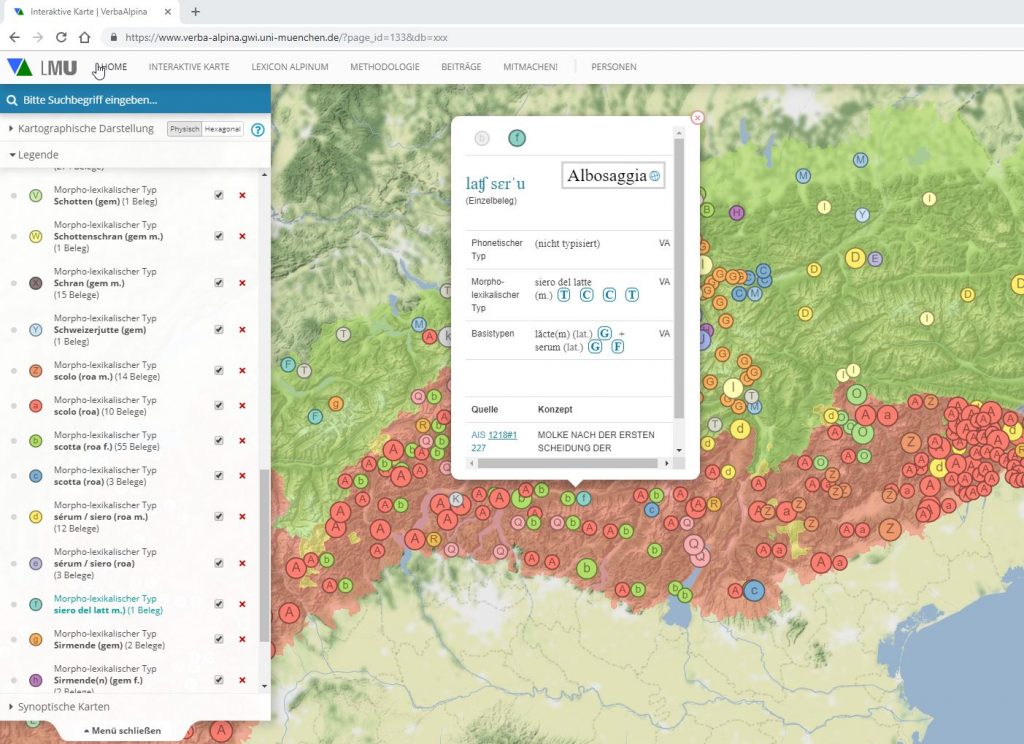
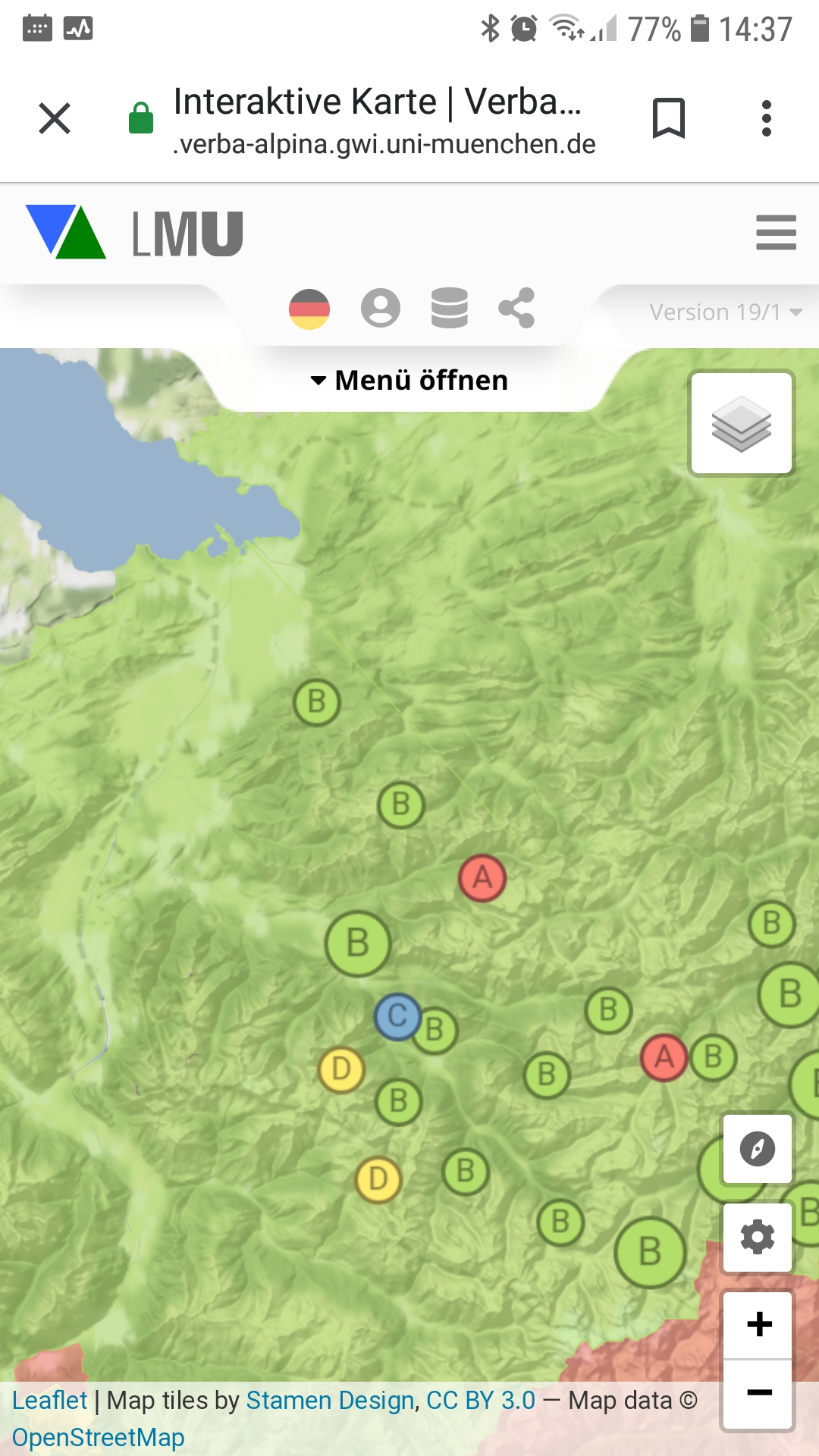
The interactive online map appears as the, so to say, "showcase" of the project. It is designed as the central data access point for the public, enabling the representation of language data in the dimension of space and thus revealing connections that often remain hidden when data is viewed in table or list form.
The digital map offers both the possibility of accessing the database from the perspective of words, that means of mapping the various concepts that can be designated by a particular word, and the option of asking the opposite question: Which concepts are designated where with which words. In traditional publishing, these two perspectives could only be served by two different genera: The (onomasiological) language atlas and the (semasiological) dictionary. The digital online map even offers the possibility of synoptically mapping both perspectives.
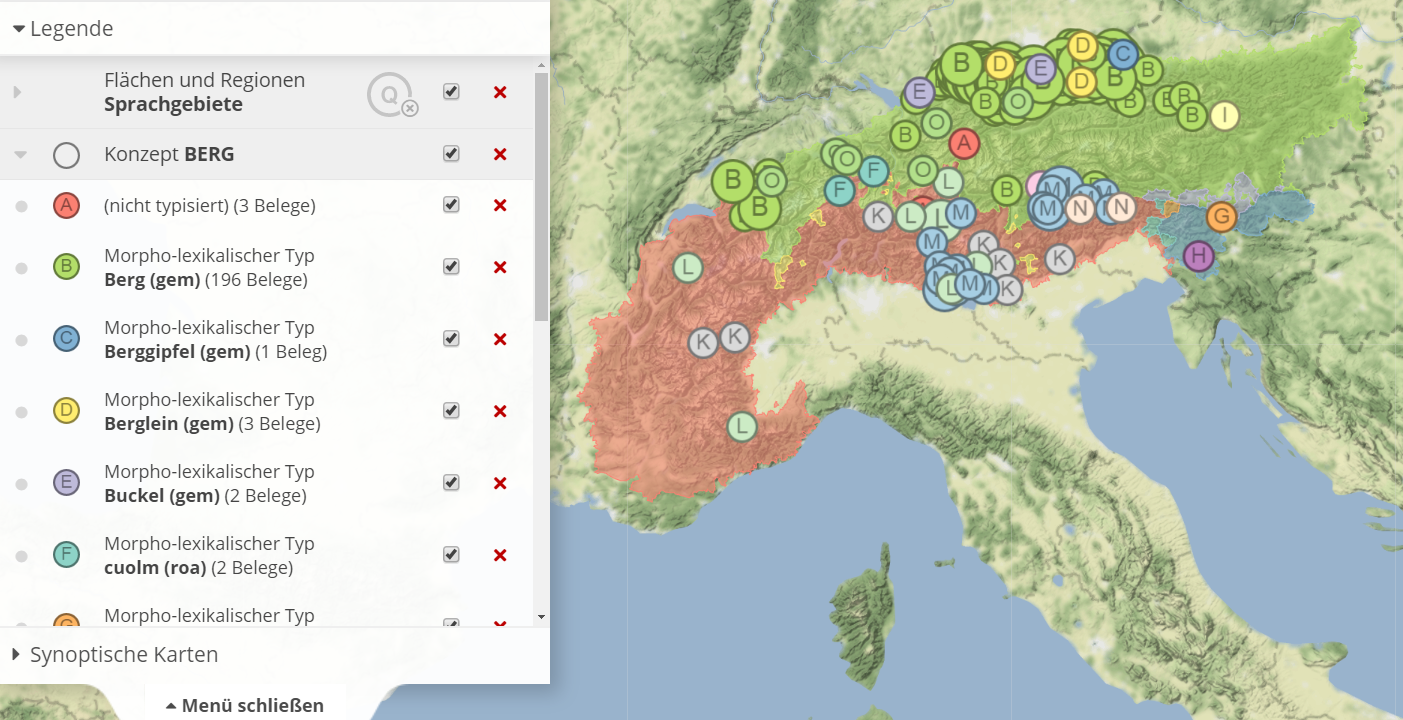
The map essentially offers two different forms of visualization. he standard method is qualitative mapping where the individual data which are bundled according to political communities are first displayed on the map by symbols. The following example shows the mapping of the distribution of the Romanic morph type malga, grouped according to its regionally different meanings:
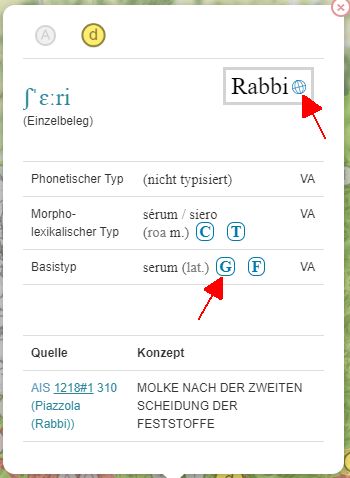
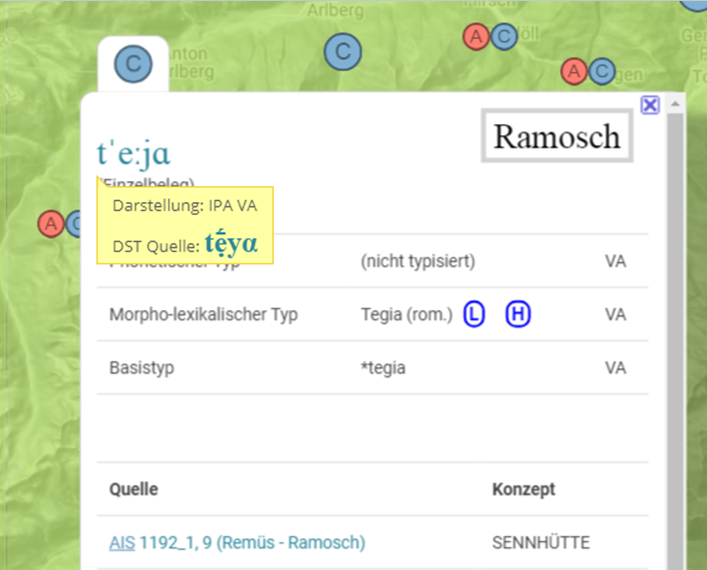
A click on the map symbols opens an info window in which the underlying language data is presented. In addition to the source, the concept designated with the word, the base type and the individual attestation of the respective source in IPA are also displayed. The framed letters behind morph and base types refer to the corresponding entries in the reference dictionaries and are partly interactive, depending on accessibility on the net. A click on the symbol then leads directly to the corresponding entry in the reference dictionary. The info window also includes norm data and links to them. A click on the globe symbol next to or below the municipality name leads to the corresponding Geonames page, the concept names are linked to the Wikidata entries.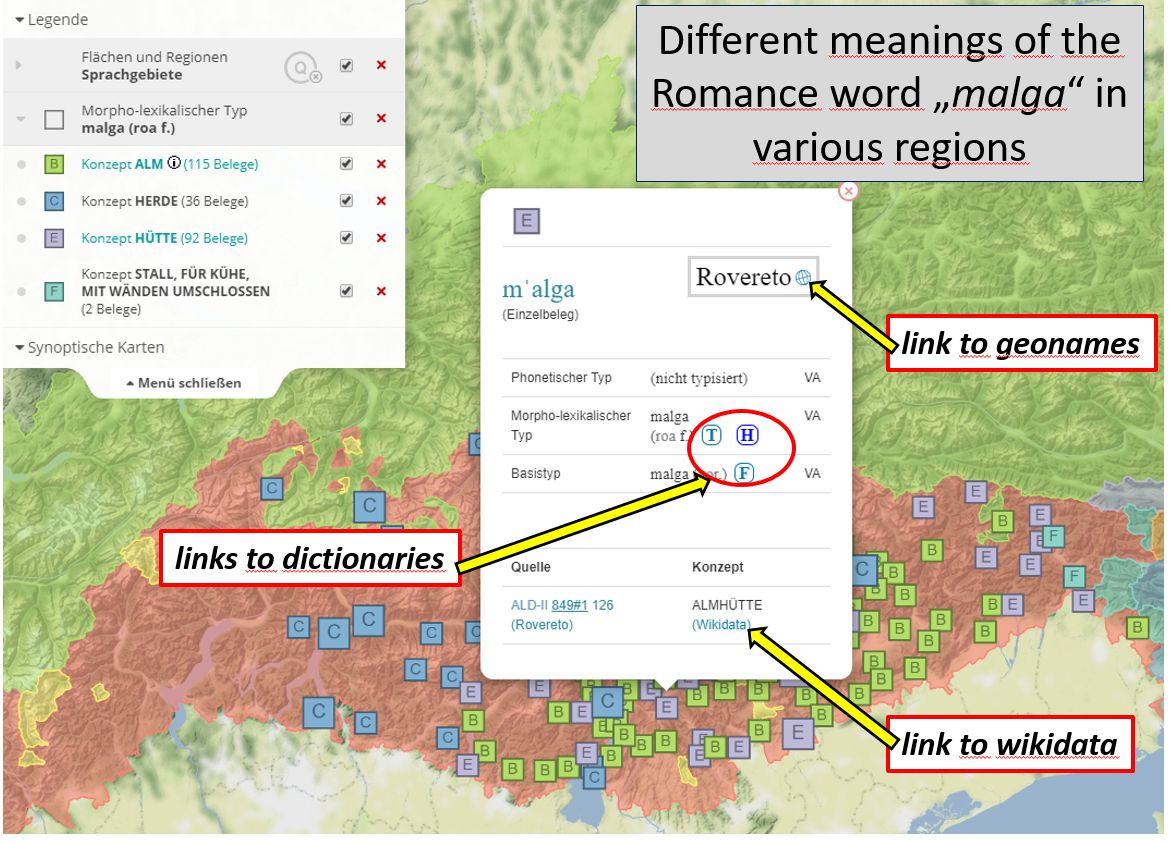
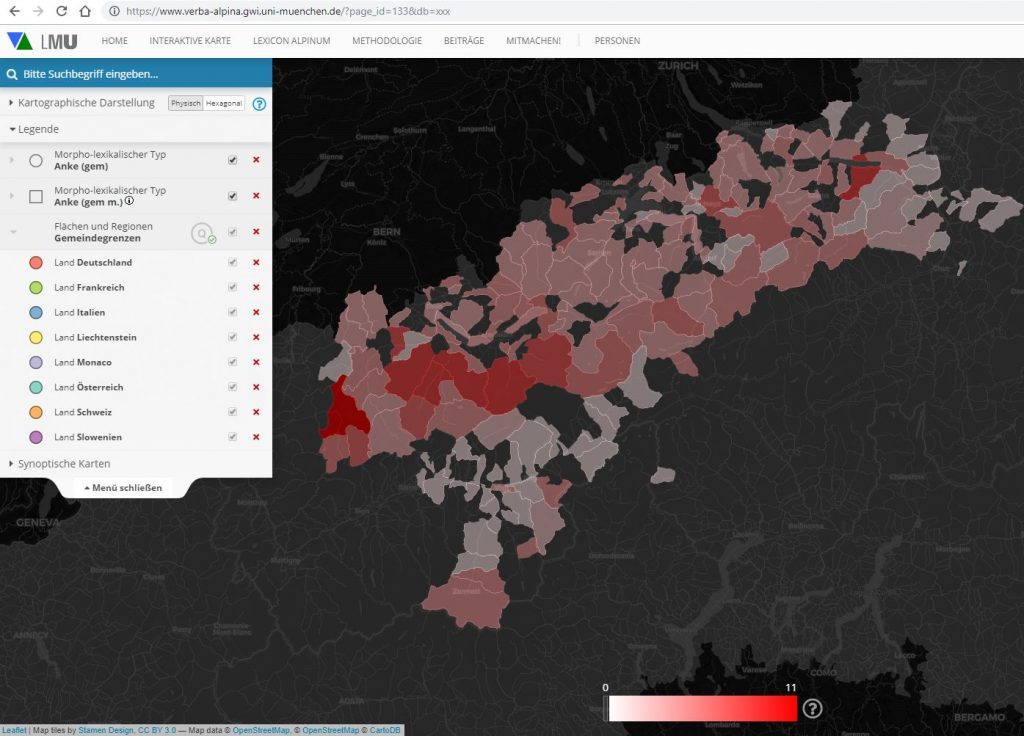
In addition to qualitative mapping, VerbaAlpina also offers a quantifying presentation. A click on the Q in the circle next to the menu item "Areas and regions" acccumulates the currently mapped elements according to regions and colours them differently according to the number of elements mapped there. As default the large language areas form the reference pattern. By selecting the corresponding menu item "Areas and regions", the data can also be accumulated and mapped according to smaller administrative units down to the level of municipalities.
The following map shows the distribution of morph types connected to the (Latin) base type butyuru(m) (Link):
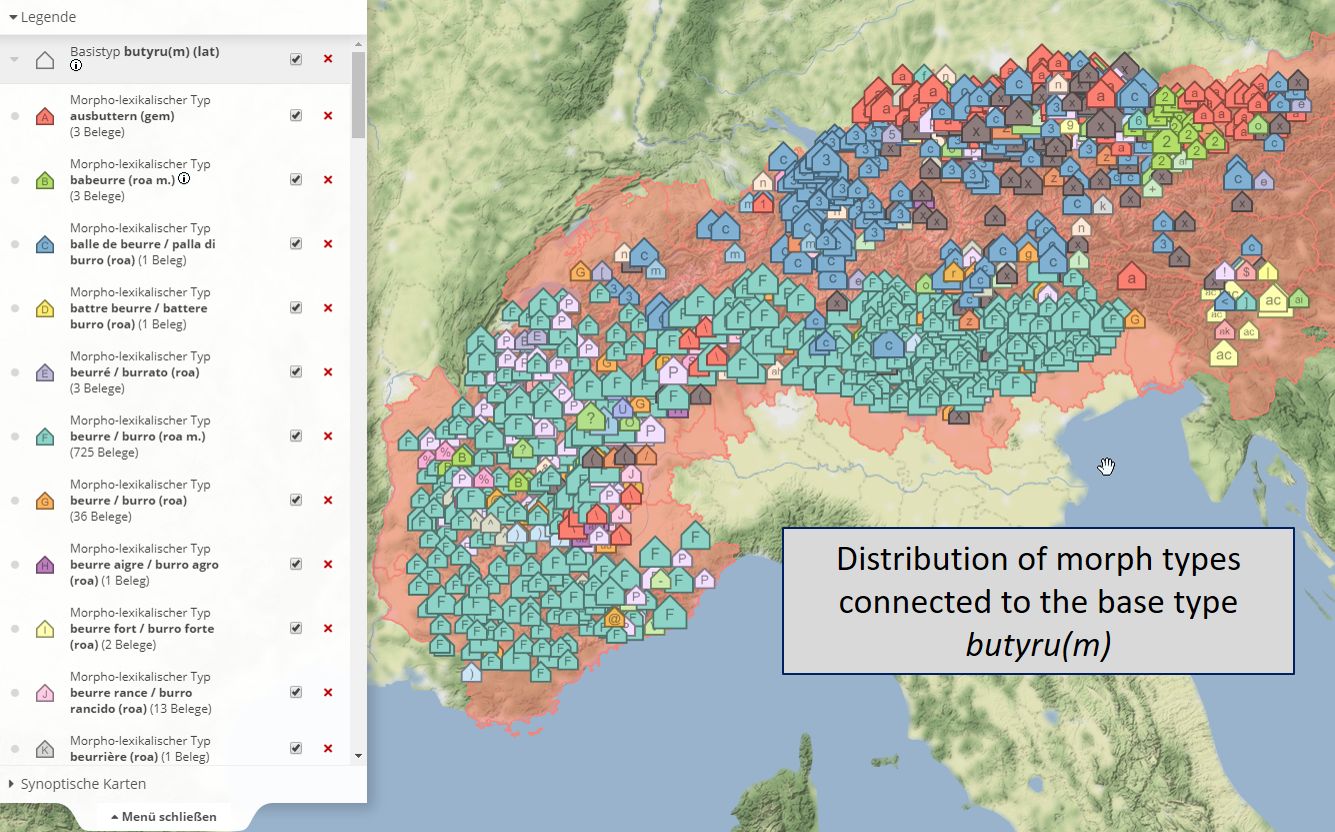
Distribution of morph types connected to the base type butyru(m) (qualitative mapping)
The same data accumulated on the quantifying map (Link):
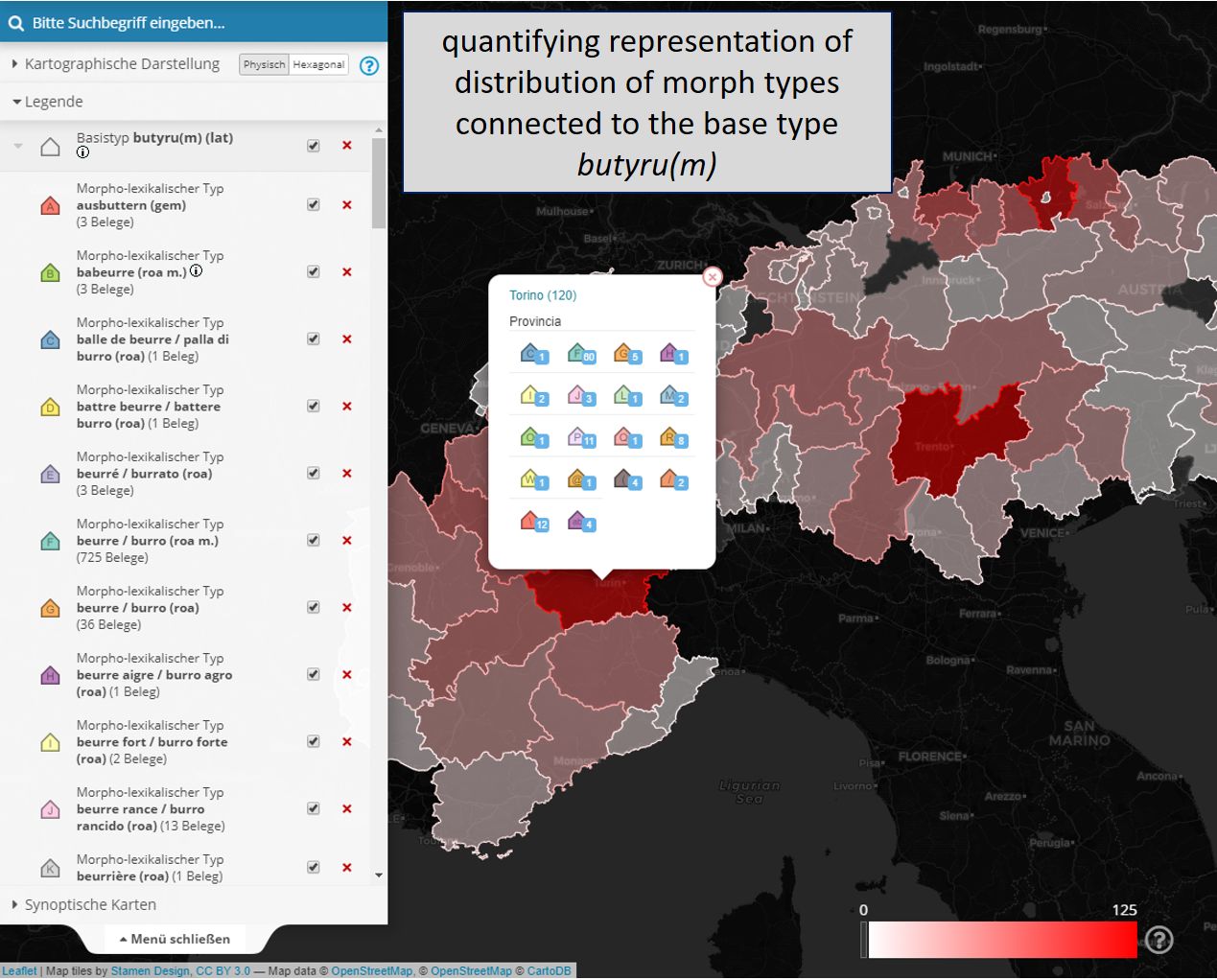
quantifying representation of the distribution of morph types connected to the base type butyru(m)
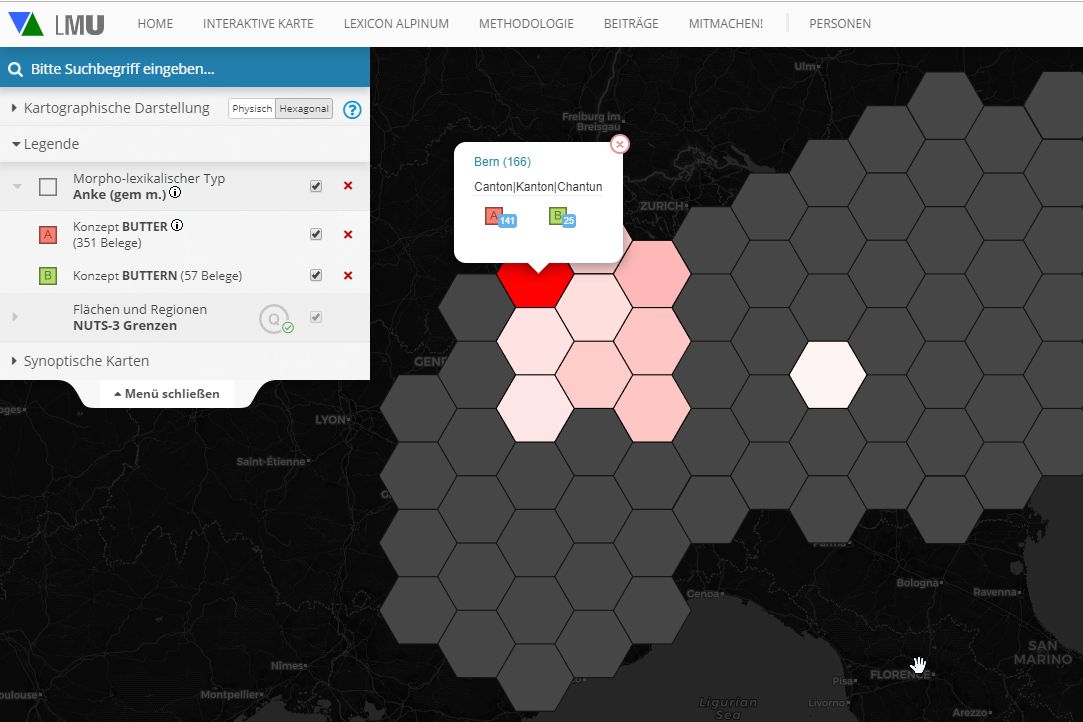
In addition to the realistic representation of the geographical boundaries, the quantifying representation can also be visualized on a hexagon map. In this kind of map, the geographical units are represented by hexagons of identical size. Thus, visual distortion effects are avoided which result from the area sizes which differ strongly from each other in reality. Of course, this kind of mapping has the disadvantage that the geographical arrangement of the areas and especially the number of adjacent areas no longer corresponds to reality in most cases. The added value certainly results from the possibility of switching between the different mapping variants and thus gaining an almost objective impression.
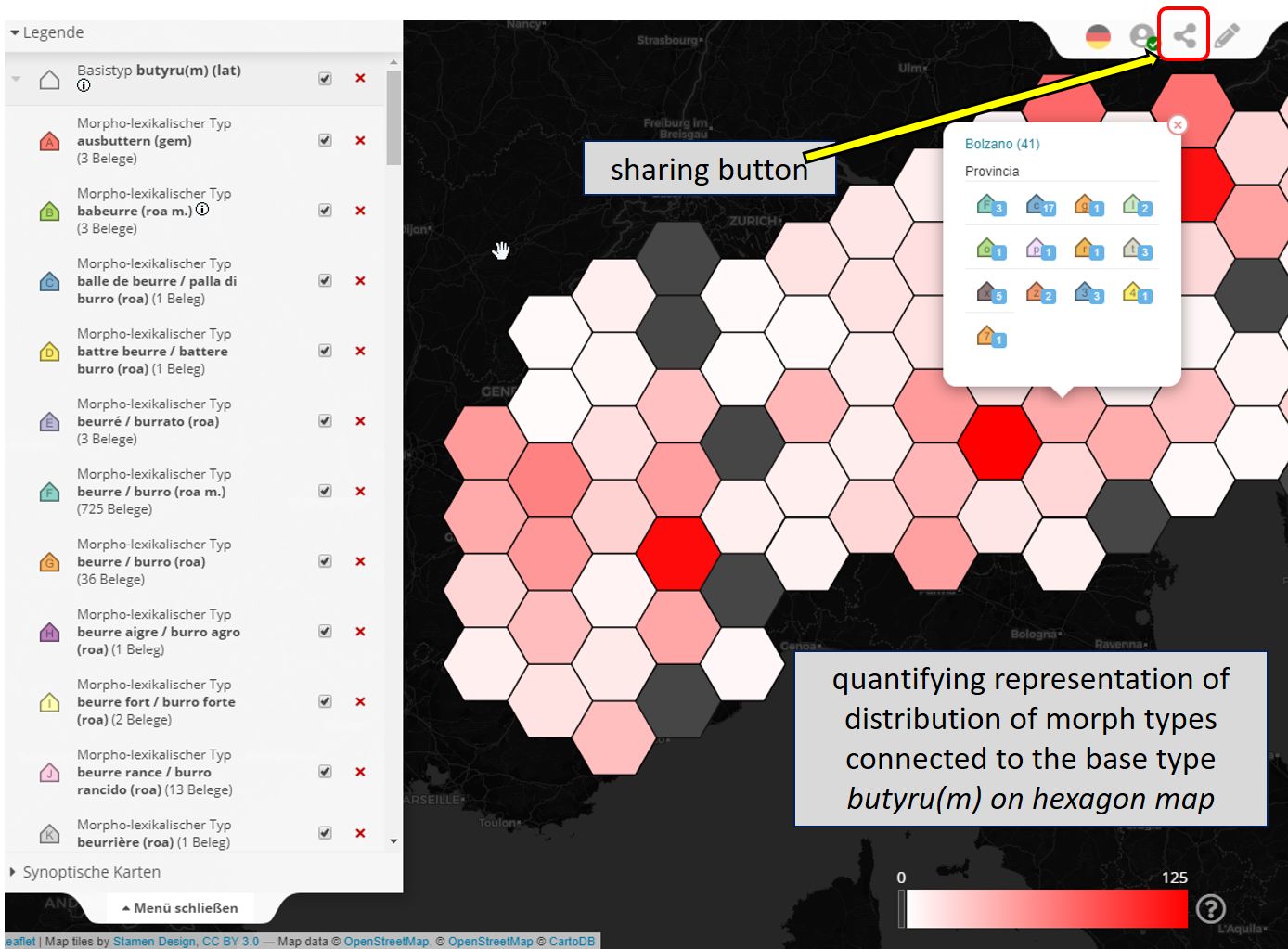
Hexagon map
The sharing symbol at the top right-hand corner of the map allows you to call up a persistent link that refers stably to the current map view and can, for example, be sent by e-mail or used in texts.
The realization of the online map is based on the latest graphics technology (WebGL) and is extremely powerful. This performance becomes visible above all during zoom processes with a large number of map symbols and borders, which demand a high computing power from the computer. The use of WebGL allows the necessary calculations on the processor of the graphics card (GPU) which is responsable for the decisive performance gain.
Cross-linkage and sustainability
Access to VA-data
Access to VerbaAlpina data is possible in various ways:
- Via the project portal, which is freely accessible on the Internet and above all via the interactive online map and the – not yet mentioned – Lexicon alpinum,
- via the API, which is also freely accessible,
- or by using the PMA interface of the MySQL database.
The API allows the download of finely granulated material in a number of different formats and aggregations. Access via the PMA interface is reserved for VerbaAlpina's official cooperation partners. The PMA interface allows data analysis using the SQL language. SQL-statements can also be executed using a form in the mapping tool. This function will be accessible to the public very soon. At present its use is restricted to registered users.
VerbaAlpina's core data is very finely granulated and the individual elements are uniquely identified with persistent identifiers and can therefore be addressed precisely. Ultimately, these alphanumeric identifiers fulfill the function of VerbaAlpina-specific norm data. In concrete terms, all morph types, concepts and political communities are given a unique number which can be used to access the specific data in different ways or be referenced externally. Identifiers of the morph types have the prefix L, concepts C and communities A. The ID L1435, for example, stands for the morph type "babeurre (m.) (roa.)". The first of the following addresses calls up a mapping of the distribution of this morph type, the second leads to the download of the data stored on this morph type in XML format and the last, finally, leads to the commentary in the Lexicon Alpinum – if available:
- https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=133&db=191&single=L1435
- https://www.verba-alpina.gwi.uni-muenchen.de/?api=1&action=getRecord&id=L1435&version=191&format=xml&empty=0
- https://www.verba-alpina.gwi.uni-muenchen.de/?page_id=2374&db=191#L1435
With a few exceptions, all URLs that refer to VerbaAlpina content contain a parameter that refers to a specific version of VerbaAlpina, marked in red in the examples above. The first two digits represent the year, the last one the version number of the year (191: first version in 2019). While the database of the working version, which is recognizable by the character string xxx, is subject to permanent changes, the contents of the other versions are stable. This ensures that references to these URLs always call up the same content and citation security is guaranteed. VerbaAlpina data is versioned twice a year, at mid-year and at year-end. You can choose between the available versions on the homepage.
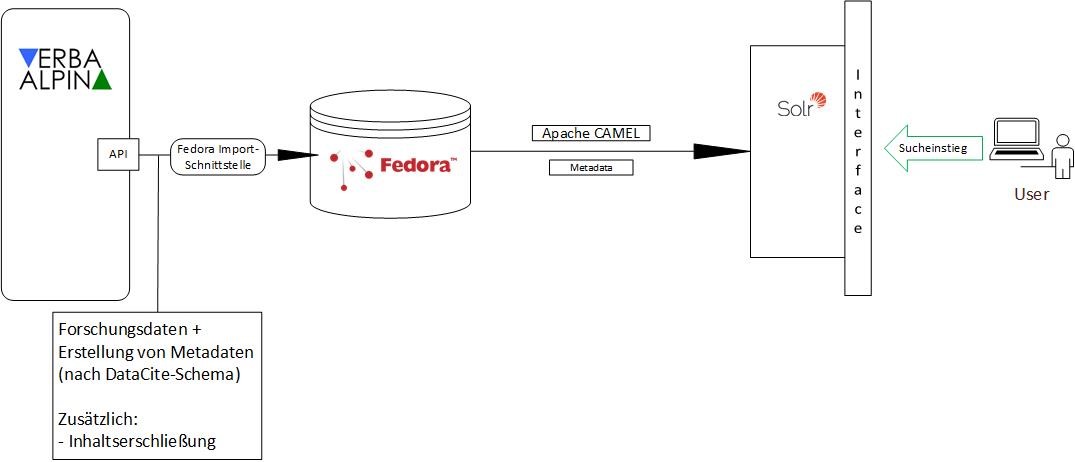
The data of VerbaAlpina will soon also be transferred to the RDF schema of the Semantic Web. However, the establishment of a SPARQL endpoint is not planned for the time being; the corresponding implementation involves some effort and seems dispensable since there are a number of other ways of accessing the VerbaAlpina data. After all, VerbaAlpina meets the criteria of the "Linguistic linked open data" movement (http://linguistic-lod.org/).9, and the data of VerbaAlpina will soon be included in this.
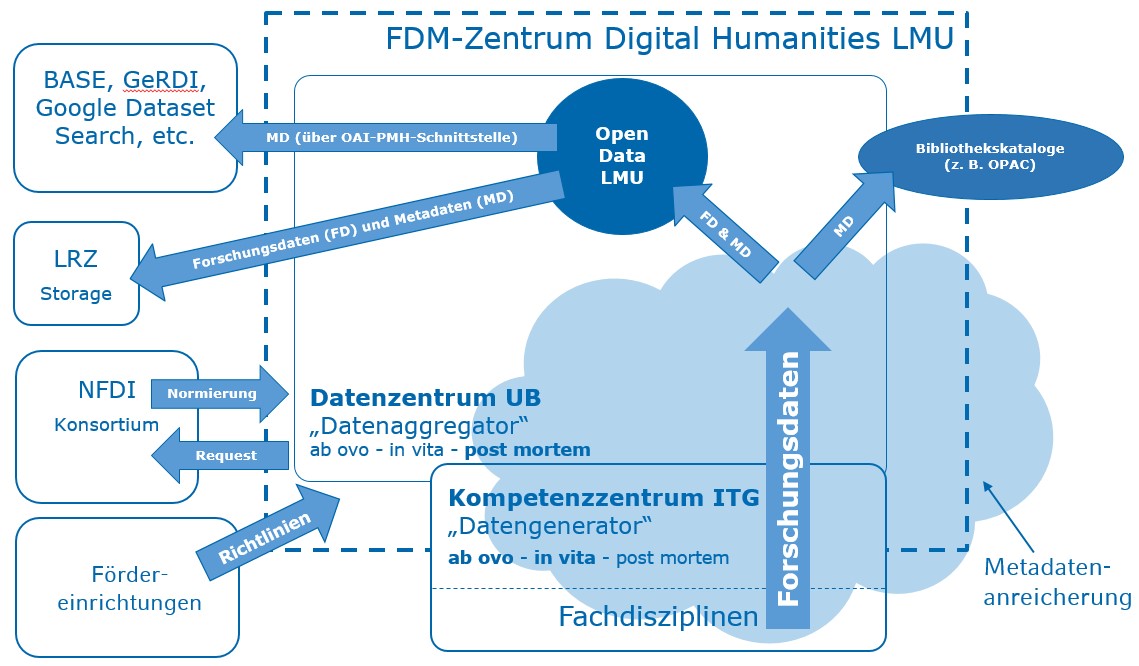
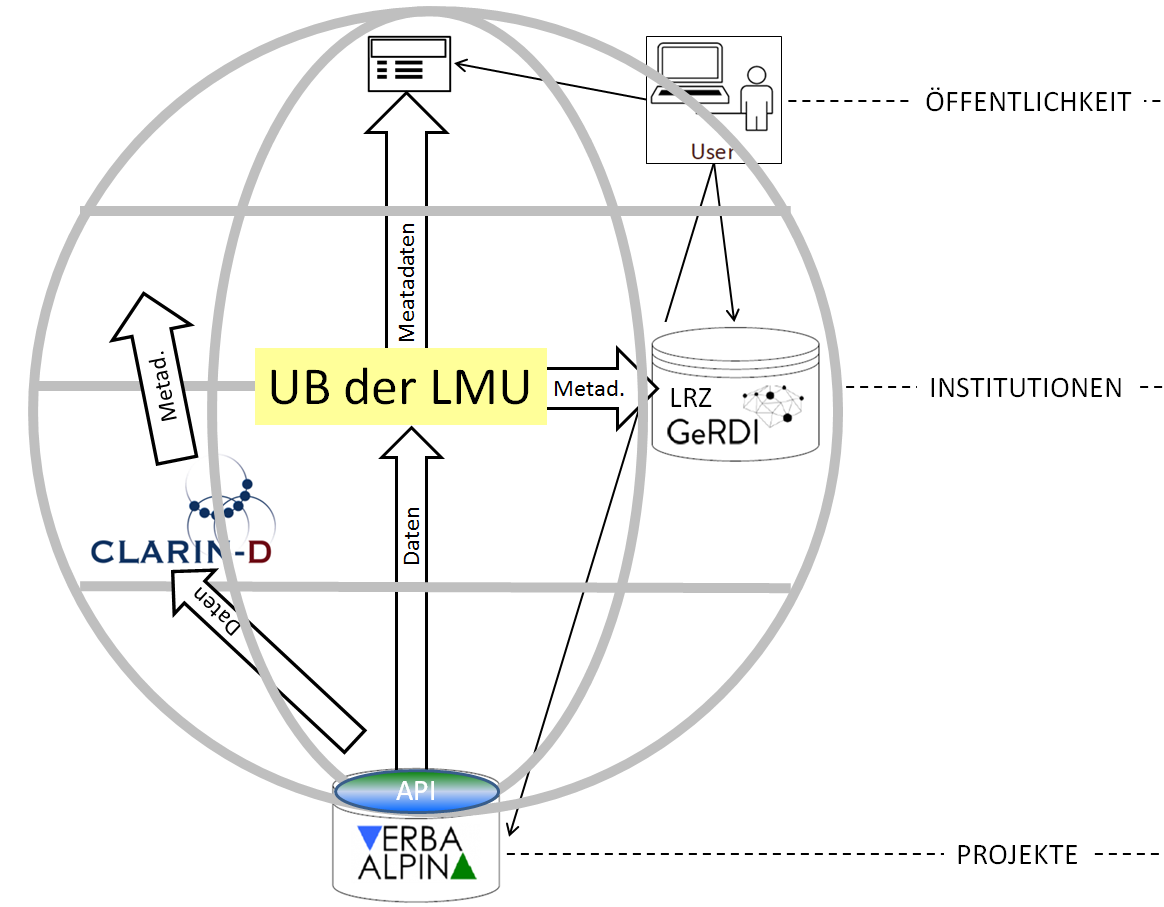
In the course of transferring the data of VerbaAlpina to the research data repository of the LMU-Library every item is enriched with DataCite metadata and is given a persistent DOI. The corresponding procedure is currently in development. It will soon be functional.
Linkage with external resources
VerbaAlpina links the three core categories of its database with external databases via the integration of suitable norm data.
In the case of morph types, corresponding links are established to the reference dictionaries. An interesting side effect is that the different suitability of the corresponding resources becomes clear. In terms of maximum interoperability, only some of the reference dictionaries provide suitable possibilities to technically address data in a desireable way. Positive examples include the portal of the Centre National de Ressources Textuelles et Lexicales ([Bibl:CNRTL]) or the Italian Treccani which offer transparent URLs for each lexical entry (e.g: https://www.cnrtl.fr/definition/beurre, http://www.treccani.it/vocabolario/burro/). In some other cases references are only possible with great inaccuracy or not at all. It is not uncommon to encounter the phenomenon that the addressability of the contents still refers to the conventional page logic of book printing and to PDF documents or image files. This is, for example, the case with the French etymological dictionary (FEW).
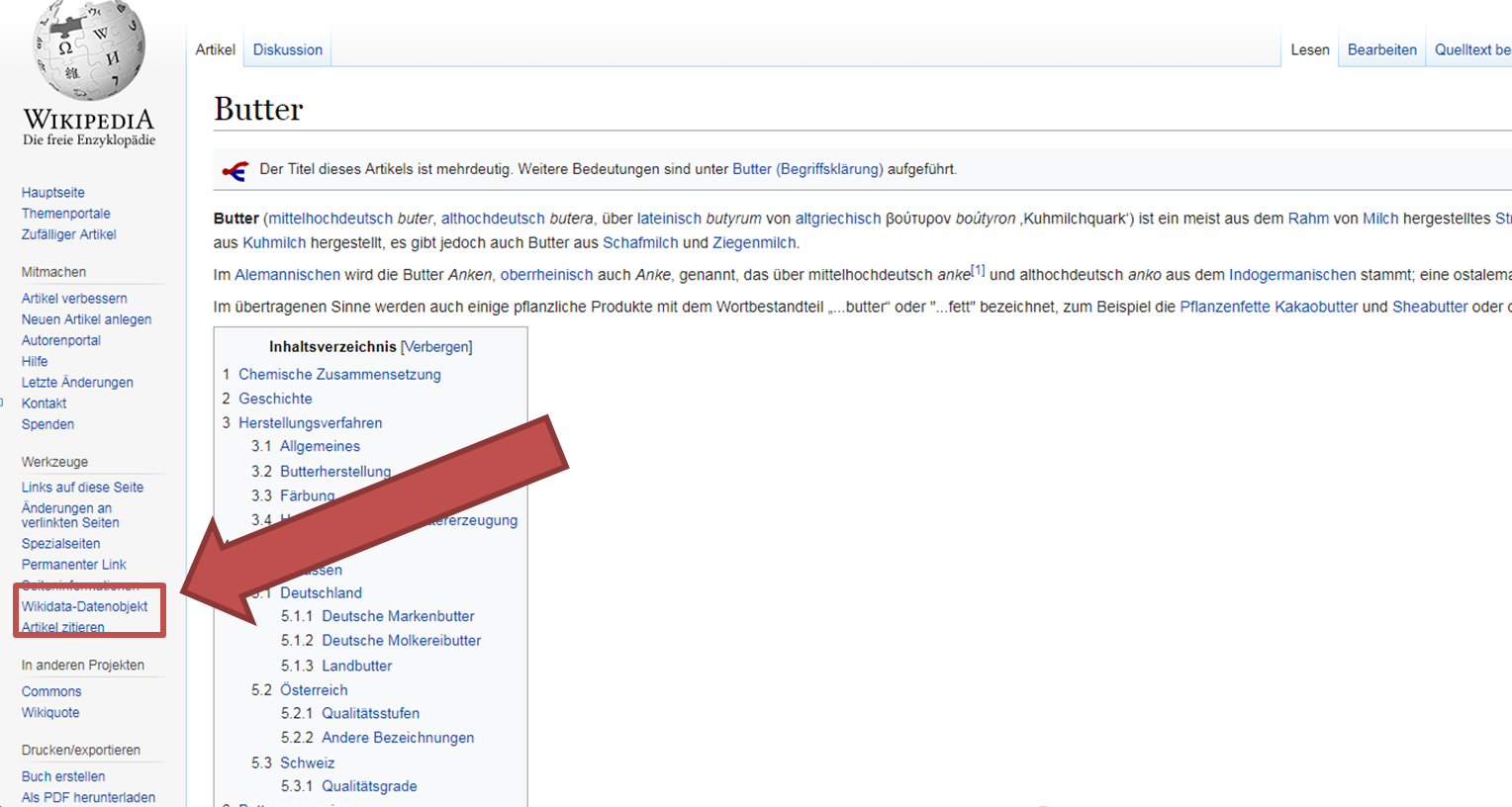
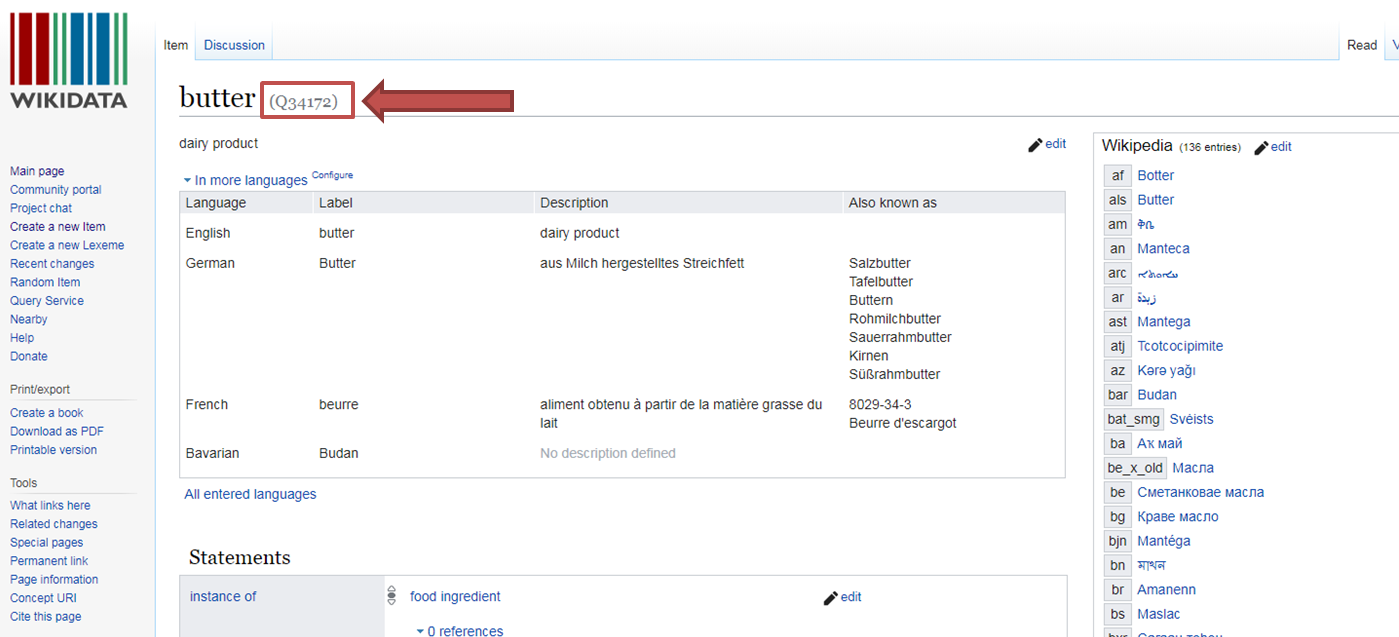
For the concepts VerbaAlpina refers so far exclusively to the so-called Wikidata data objects. Each concept is assigned the respective Wikidata Q-ID in the database of VerbaAlpina. The corresponding link leads to the Wikidata data object page. There you will find links to the articles in the different Wikipedia of this concept. The link to the norm data of geonames has already been mentioned.
As we have already seen, links to all norm data are presented to the user in the info windows on the online map.
Some organizational stuff
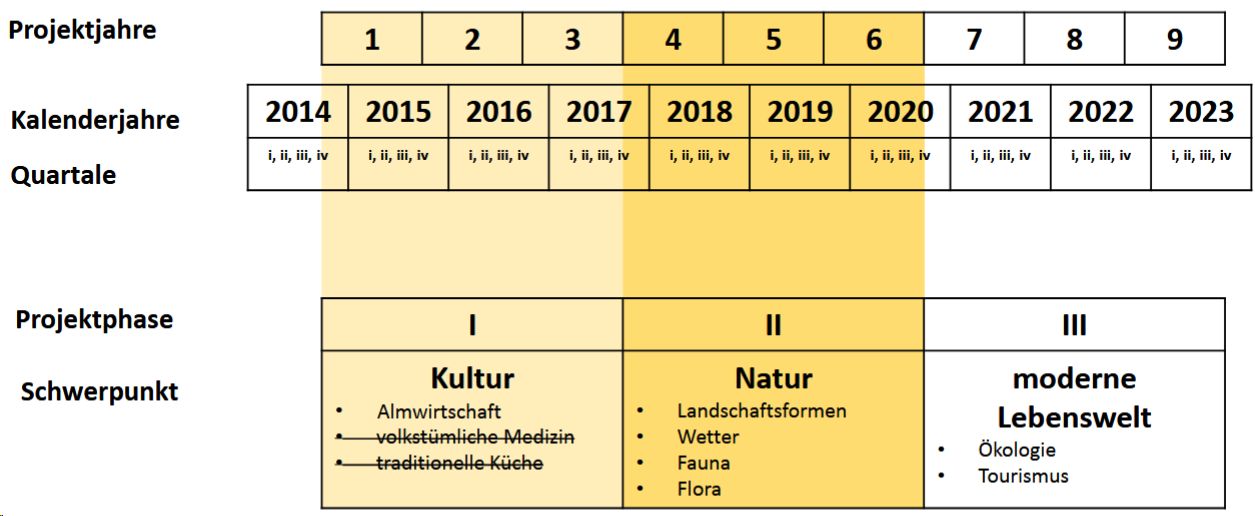
VerbaAlpina started in 2014 and is funded by the German Research Foundation (DFG) with a perspective until 2025. The individual project terms comprise 3 years each. At the moment we are heading towards the last year of the second term and are about to prepare the application for the funding of the third term.
VerbaAlpina is directed by Thomas Krefeld and myself. The staff is divided into two parts: There are three linguists and two computer scientists who are each supported by assistants. Among the linguists there are two Romance scholars and one Germanist. One of the computer scientists is mainly responsible for all aspects of the core data (data modelling, interfaces, API), the other mainly for all questions of visualisation, mainly the interactive online map.
VerbaAlpina is thus an interdisciplinary DH project with parts of the classical humanities and computer science. The LMU Center for Digital Humanities (IT-Gruppe Geisteswissenschaften; ITG) is responsible for the informatics part. This institution was created in 2000, is largely financed by the six humanities faculties of the LMU and has an unlimited perspective of existence. The ITG is responsible for planning and operating the IT infrastructure in the Humanities area. One of the ITG's steadily growing areas of responsibility is support in the planning and implementation of DH projects. From the ITG's point of view, VerbaAlpina is only one of numerous projects whose project data is managed in the context of a heterogeneous, but uniformly – namely relationally – structured overall data pool. Over the years, this data pool has grown to considerable size and diversity, offering at least theoretically the perspective of data analysis across project boundaries. Against this background, the ITG is currently developing a cooperation with the LMU-Master's programme in Data Science, which was launched at the beginning of 2017.
The ITG also plays an important role with regard to the sustainability of the results produced by VerbaAlpina. After the end of project funding, the ITG will continue to operate the project portal as far as possible and perform the minimum maintenance work required for operation.
* Given at the colloqium „NEW WAYS OF ANALYZING DIALECTAL VARIATION“, held at Sorbonne University, Paris, 21-23 November 2019. The English version of the talk was initially produced with the help of DeepL (https://www.deepl.com/translator) and subsequently corrected or adapted where necessary.
Grassi documents the local variation of a single small town in the Italian province of Trento ↩
However, the chosen definition of the study area causes certain asymmetries, such as the fact that the Swiss Emmental, famous for its cheese, lies outside the Alpine Convention and is therefore not covered by VerbaAlpina, although this region could very well be considered part of the Alpine region from both an economic and an environmental point of view. ↩
Such is the case in the AIS ↩
AIS 1218_1, 129 ↩
This would be the case, for example, if the Böhmer Ascoli system, used for example in the AIS, were transcribed directly into IPA instead of the present one, since IPA does not allow such a fine differentiation with regard to the individual sounds as Böhmer Ascoli does ↩
The procedure is sketched in S. Lücke / C. Riepl / C. Trautmann, Softwaretools und Methoden für die korpuslinguistische Praxis (Korpus im Text 1, München 2017, S. 126f. ↩
A master thesis has just been completed at the Institute of Computer Science of the LMU, which was intended to design an algorithmic solution to this problem. Among other things, deep learning methods were used. As far as VerbaAlpina can judge, however, no success is in sight in this way either – not to talk about the technical availability of an appropriate tool. ↩
AIS: Map 1152: un'ape; le api"
ALF: Map 1: abeille"
ALJA: Map 792: (l') abeille *(le) mâle des abeilles"
ASLEF: Map 1148: ape"
TSA: Map III_28: Biene"(cf. map https://www.verba-alpina.gwi.uni-muenchen.de?page_id=133&db=xxx&tk=2428)
↩S. Chiarcos, Christian; McCrae, John; Cimiano, Philipp; Fellbaum, Christiane (2013). Towards open data for linguistics: Lexical Linked Data (PDF). Heidelberg, in: Alessandro Oltramari, Piek Vossen, Lu Qin, and Eduard Hovy (Hrsgg.), New Trends of Research in Ontologies and Lexical Resources. Springer. ↩
Bibliographie
- AIS = Jaberg, Karl / Jud, Jakob (1928-1940): Sprach- und Sachatlas Italiens und der Südschweiz, Zofingen, vol. 1-7
- ALF = Gilliéron, Jules / Edmont, Edmond (1897-1900): l’Atlas linguistique de la France, Paris , Champion. Link
- ALJA = Martin, Jean-Baptiste / Tuaillon, Gaston (1971, 1978, 1981): Atlas linguistique et ethnographique du Jura et des Alpes du nord, Paris, vol. 1, 3, 3a, Éd. du Centre National de la Recherche Scientifique
- ASLEF = Pellegrini, Giovan Battista (1974-1986): Atlante storico-linguistico-etnografico friulano, Padova, vol. 1-6
- DizMT = Grassi, Corrado (2009): Dizionario del dialetto di Montagne di Trento, San Michele all'Adige
- FEW = Wartburg, Walter (1922-1967): Französisches etymologisches Wörterbuch. Eine Darstellung des galloromanischen Sprachschatzes , Basel, vol. 20, Zbinden. Link
- Idiotikon = (1881 ff.): Schweizerisches Idiotikon. Schweizerdeutsches Wörterbuch, Basel. Link
- TSA = Klein, Karl Kurt/ Kühebacher, Egon/ Schmitt, Ludwig Erich (1965, 1969, 1971): Tirolischer Sprachatlas, vol. 1-3, Innsbruck, Tyrolia-Verl. [u.a.]
- VALTS = Gabriel, Eugen (1985-2004): Vorarlberger Sprachatlas mit Einschluss des Fürstentums Liechtenstein, Westtirols und des Allgäus , vol. 1-5, Bregenz, vol. 1-5, Vorarlberger Landesbibliothek




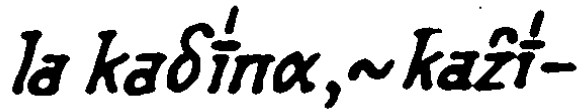





{kind=link}